TDT4215: Web-intelligence
# Curriculum
As of spring 2016 the curriculum consists of:
- __A Semantic Web Primer__, chapter 1-5, 174 pages
- __Sentiment Analysis and Opinion Mining__, chapter 1-5, 90 pages
- __Recommender Systems__, chapter 1-3, and 7, 103 pages
- _Kreutzer & Witte:_ [Opinion Mining Using SentiWordNet](http://stp.lingfil.uu.se/~santinim/sais/Ass1_Essays/Neele_Julia_SentiWordNet_V01.pdf)
- _Turney:_ [Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews](http://www.aclweb.org/anthology/P02-1053.pdf)
- _Liu, Dolan, & Pedersen:_ [Personalized News Recommendation Based on Click Behavior](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.308.3087&rep=rep1&type=pdf)
# Semantic Web
## The Semantic Web Vision / Motivation
The Semantic Web is an extension of the normal Web, that promotes common data formats and exchange protocols. The point of Semantic Web is to make the internet machine readable. It is not a matter of artificial intelligence; if the ultimate goal of AI is to build an intelligent agent exhibiting human-level intelligence (and higher), the goal of the Semantic Web is to assist human users in their day-to-day online activities.
Semantic Web uses languages specifically designed for data:
- Resource Description Framework (RDF)
- Web Ontology Language (OWL)
- Extensive Markup Language (XML)
Together these languages can describe arbitrary things like people, meetings or airplane parts.
## Ontology
An ontology is a formal and explicit definition of types, properties, functions, and relationship between the entities, which result in an abstract model of some phenomena in the world. Typically an ontology consist of classes arranged in a hierarchy. There are several languages that can describe an ontology, but the achieved semantics vary.
## RDF
> Resource Description Framework
RDF is a data-model used to define ontologies. It's a model that is domain-neutral, application-neutral, and it supports internationalization. RDF is an abstract model, and therefore not language-specific. XML is often used to define RDF data, but it is not a necessity.
### RDF model
The core of RDF is to describe resources, which basically are "things" in the world that can be described in words og relations to other resources etc. RDF consists of a lot of triples that together describe something about a particular resource. A triple consist of _(Subject, Predicate, Object)_, and is called a __statement__.
The __subject__ is the resource, the thing we'd like to talk about. Examples are authors, apartments, people or hotels. Every resource has a URI _(unique resource identifier)_. This could be an ISBN-number, a URL, coordinates, etc.
The __predicate__ states the relation between the subject and the object and are called property. For example Anna is a _friend of_ Bruce, Harry Potter and the Philosopher's Stone was _written by_ J.K. Rowling or Oslo is _located in_ Norway.
The __object__ is another resource, typically a value.
The statements are often modeled as a graph, and an example could be: _(lit:J.K.Rowling, lit:wrote, lit:HarryPotter)_.

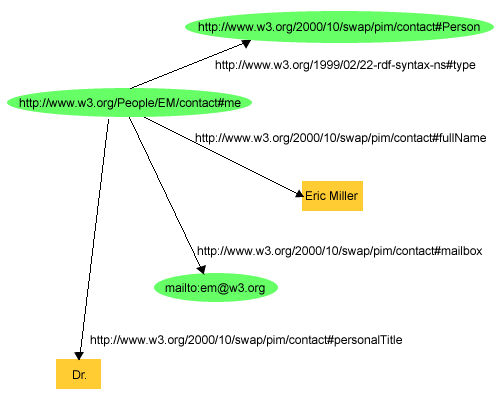
Below is a more complex example where you can see that _http://www.w3.org/People/EM/contact#me_ has the property _fullName_ defined in _http://www.w3.org/2000/10/swap/pim/contact_, which is set to the value of _Eric Miller_.
### Serialization formats
N-triples, Turle, RDF/XML, RDF/JSON.
N-triples
: It is plain text format for encoding an RDF graph.
Turtle
: Turtle can only serialize valid RDF graphs. It is generally recognized as being more readable and easier to edit manually than its XML counterpart.
RDF/XML
: It expresses RDF graph as XML document.
RDF/JSON
: It expresses RDF graph as JSON document.
## RDFS
> Resource Description Framework Schema
While the RDF language lets users describe resources using their own vocabulary, it does not specify semantics for any domains. The user must define what those vocabularies mean in terms of a set of basic domain independent structures defined by RDF Schema.
RDF Schema is a primitive ontology language, and key concepts are:
- Classes and subclasses
- Properties and sub-properties
- Relations
- Domain and range restrictions
### Classes
A class is a set of elements. It defines a type of objects. Individual objects are instances of that class. Classes can be structured hierarchical with sub- and super-classes.
### Properties
Properties are restriction for classes. Objects of a class must obey these properties. Properties are globally defined and can be applied to several classes. Properties can also be structured hierarchical, in the same way as classes.
## SPARQL
> SPARQL Protocol and RDF Query Language
RDF is used to represent knowledge, SPARQL is used to query this representation. The SPARQL infrastructure is a __triple store__ (or Graph store), a database used to hold the RDF representation. It provides an endpoint for queries. The queries follow a syntax similar to Turtle. SPARQL selects information by matching __graph patterns__.
Variables are written with a questionmark prefixed (?var), SELECT is used to determine which variable is of interest, and the query to be match is placed inside WHERE { ... }.
SPARQL provides facilities for __filtering__ based on both numeric and string comparison. eg. FILTER (?bedroom > 2).
UNION and OPTIONAL are constructs that allow SPARQL to more easily deal with __open world__ data, meaning that there is always more information to be known. This is a consequence of the principle that anyone can make statements about any resource. UNION lets you combine two queries. eg. {} UNION {}. OPTIONAL lets you add a result to the graph IF the optional-part matches, else it creates no bindings, but continues (does not eliminate the other results).
There exists a series of possibilities for organizing the result set, among others: LIMIT, DISTINCT, ORDER BY, DESC, ASC, COUNT, SUM, MIN, MAX, AVG, GROUP BY.
UPDATE provides mechanisms for updating and deleting information from triple stores, and ASK (insted of SELECT) returns true/false instead of the result-set and CONSTRUCT (insted of SELECT) returns a subset of graph insted of a list of results. Can be used to construct new graphs
Since schema information is represented in RDF, SPARQL can query this as well. It allows one to retrieve information, and also to query the semantics of that information.
### Example query
_Returns all sports, from the ontology, that contains the text "ball" in their name._
PREFIX dbpediaowl:<http://dbpedia.org/ontology/>
SELECT DISTINCT ?sport where {
?sport rdf:type dbpediaowl:Sport .
FILTER regex(?sport, "ball", "i") .
}
An online endpoint for queries can be found [here](http://dbpedia.org/sparql).
## OWL
> Web ontology language
RDF and RDF Schema are limited to binary ground predicates and class/property hierarchy. We sometimes need to express more advanced, more expressive knowledge. The requirements for such a language is:
- well-defined syntax
- a formal semantics
- sufficient expressive power
- convenience of expression
- efficient reasoning support
More specific, __automatic reasoning support__, which is used to:
- check the consistency of the ontology
- check for unintended relations between classes
- check for unintended classifications of instances
There is a trade-off between expressive power and efficient reasoning support. The richer the logical formalism, the less efficient reasoning support, often crossing the border to __decidability__: reasoning on such logic is not guaranteed to terminate. Because this trade-off exists, two approaches to OWL have been made: [Full](### OWL full) and [DL](### OWL DL).
### OWL Full
> RDF-based semantics
This approach uses all the OWL primitives. It is great in the way that any legal RDF document is also a legal OWL Full document, and any valid RDF Schema inference is also a valid OWL Full conclusion. The problem is that it has become so powerfull that it is undecidable, there is no complete (efficient) reasoning support.
### OWL DL
> Direct semantics
DL stans for Descriptive Logic, and is a subset of predicate logic (first-order logic). This approach offers efficient reasoning support and can make use of a wide range of existing reasoners. The downside is that it looses full compability with RDF: a RDF document must be extended in some way to be a valid OWL DL document. However, every legal OWL DL document is a legal RDF document.
Three __profiles__, OWL EL, OWL QL, and OWL RL, are syntactic subsets that have desirable computational properties. In particular, OWL2 RL is implementable using rule-based technology and has become the de facto standard for expressive reasoning on the Semantic Web.
### The OWL language
[#] TODO: constructs, classes, properties, cardinality, axioms
OWL uses an extension of RDF and RDFs. It can be hard for humans to read, but most ontology engineers use a specialized ontology development tool, like [Protégé](http://protege.stanford.edu).
There are four standard __syntaxes__ for OWL:
RDF/XML
: OWL can be expressed using all valid RDF syntaxes.
Functional-style syntax
: Used in the language spesification document. A compact and readable syntax.
OWL/XML
: XML-syntax, allows us to use off-the-shelf XML authoring tools. Does not follow RDF conventions but closely maps onto function-style.
Manchester syntax
: As human readable as possible. Used in Protégé.
# Sentiment analysis
Sentiment analysis is about searching through data to get people's opinions about something. Sentiment analysis is also called opinion mining, opinion extraction, sentiment mining, subjectivity analysis, affect analysys, emotion analysis, or review mining.
Sentinemt analysis is important because opinions drive decisions. People will seek other people's opinions when buying something. It is useful to be able to mine opinions on a product, service or topic.
Businesses and organizations are interested in knowing what people think of their products. Individuals are interested in what others think of a product or service. We would like to be able to do a search like "How good is iPhone" and get a general opinion on how good it is.
With "explosions" of opinion data in social media and similar applications it is easy to gather data for use in decisionmaking. It is not always necessary to create questionnaires to get peoples opinions. It can, however, be difficult to extract meaning from long blogposts and arcticles, and make a summary. This is why we need _Automated Sentiment analysis systems_.
There are two types of evaluation:
- Regular opinions ("This camera is great!")
- Comparisons ("This camera is better than this other camera.")
Both can be direct or indirect.
## The Model
A regular opinion are modeled as a quintuple:
(e, a, s, h, t) = (entity, aspect, sentiment, holder, time)
Entity
: The target of the opinion, the "thing" which the opinion is expressed on. _(camera)_
Aspect
: The attribute of the entity, the specific part of the "thing". _(battery life)_
Sentiment
: Classification either as positive, negative or neutral, or a more granular representation between these. _(+)_
Holder
: The opinion source, the one expressing the opinion. _(Ola)_
Time
: Simply the datetime when this opinion was expressed. _(05/06/16 12:30)_
_Example: "Posted 05/06/16 12:30 by Ola: The battery life of this camera is great!"_
The task of sentiment analysis is to discover all these quintuples in a given document.
A __framework__ of tasks:
1. Entity extraction and categorization
- entity category = a unique entity
- entity expression = word or phrase in the text indicating an entity category
2. Aspect extraction and categorization
- explicit and implicit aspect expression
- Implicit: "this is expensive"
- Explicit: "the price is high"
3. Opinion holder extraction and categorization
4. Time extraction and standardization
5. Aspect sentiment classification
- Determine the polarity of the opinion on the aspect
6. Opinion quintuple generation
.
## Levels of Analysis
Research has mainly been done on three different levels.
### Document-level
Document-level sentiment classification works with entire documents and tries to figure out of the document has a positive or negative view of the subject in question. An example of this is to look at many reviews and see what the authors mean, if they are positive, negative or neutral.
### Sentence-level
Sentence-level sentiment classification works with opinion on a sentence level, and is about figuring out if a sentence is positive, negative or neutral to the relevant subject. This is closely related to _subjectivity classification_, which distinguishes between objective and subjective sentences.
### Entity and aspect-level
Entity and aspect-level sentiment classification wants to discover opinions about an entity or it's aspects. For instance we have the following sentence, "The iPhone’s call quality is good, but its battery life is short", two aspects are evaluated: call quality and battery lifetime. The entity is the iPhone. The iPhone's call quality is positive, but the battery duration is negative. It's hard to find and classify these aspects, as there are many ways to express positive and negative opinions, metaphors, comparisons and so on.
There are two core tasks of aspect-based sentiment analysis: the [aspect extraction](##### Aspect Extraction), and the [aspect sentiment classification](##### Aspect Sentiment Classification). We'll start by looking at the latter.
#### Aspect Sentiment Classification
There are two main approaches to this problem; Supervised learning and lexicon-based.
__Supervised learning.__
Key issue is how to determine the scope of each sentiment expression. Current main approach is to use parsing to determine the dependencies and other relevant information. Difficult to scale up to a large number of application domains.
__Lexicon based.__
Some words can be identified as either positive or negative immediately, like good, bad, excellent, terrible and so on. A list of such words or sentences is called a __sentiment lexicon__. This approach has been shown to perform quite well in a large number of domains. Use a sentiment lexicon, composite expressions, rules of opinions, and the sentence parse tree to determine the sentiment orientation on each aspect in a sentence.
_The algorithm_:
1. Input
- "The voice quality of this phone is not good, but the battery life is long"
2. Mark sentiment words and phrases
- good [+1] (voice quality)
3. Apply sentiment shifters
- NOT good [-1] (voice quality)
4. Handle but-clauses
- long [+1] (battery life)
5. Aggregate opinions
- voice quality = -1
- battery life = +1
There are some known issues with sentiment lexicons. Orientations in different domains _("camera sucks", "vacum sucks")_, sentences containing sentiment words may not express any sentiment _("which camera is good?")_, sarcasm _("what a great car, stopped working in two days")_, and sentences without sentiment words can also imply opinions _(“This washer uses a lot of water”)_ (a fact, but using water is negative. A matter of identifing resource usage).
#### Aspect Extraction
Now we'll look at the other task of aspect-based sentiment analysis, extracting the aspects from the text. There are four main approaches for accomplishing this:
1. Extraction based on frequent nouns and noun phrases
2. Extraction by exploiting opinion and target relations
3. Extraction using supervised learning
4. Extraction using topic modeling
Below follows a brief description of each approach:
__Finding frequent nouns and noun phrases.__
This method finds explicit aspect expressions bt using sequential pattern mining to find frequent phrases. Each frequent noun phrase is given an PMI _(pointwise mutual information)_ score. This is a score between the phrase and some meronymy discriminators associated with the entity class.
__Use opinion and target relations.__
Use known sentiment words to extract aspects as the target for that sentiment. e.g. "the software is amazing", amazing is a known sentiment word and software is extracted as an aspect. Two approaches exists: The double propagation method and a rule based approach.
__Using supervised learning.__
Based on sequential learning (labeling). Supervised means that it needs a pre-labeled training-set. Most state-of-the-art methods are HMM _(Hidden Markov Models)_ and CRF _(Conditional Random Fields)_.
__Using topic modeling.__
An unsupervised learning method that assumes each document consists of a mixture of topics and each topic is a probability distribution over words. The output of topic modeling is a set of word clusters. Based on Bayesian networks. Two main basic modelsare pLSA _(Probabilistic Latent Semantic Analysis)_ and LDA _(Latent Dirichlet allocation)_.
## Two unsupervised methods
> As described by two of the papers
### Search-based
[#] TODO
_Turney:_ [Thumbs Up or Thumbs Down?](http://www.aclweb.org/anthology/P02-1053.pdf).
### Lexicon-based
[#] TODO
_Kreutzer & Witte:_ [Opinion Mining Using SentiWordNet](http://stp.lingfil.uu.se/~santinim/sais/Ass1_Essays/Neele_Julia_SentiWordNet_V01.pdf).
# Recommender systems
Recommender systems elicit the interests and preferences of an individual, and make recommendations. This has the potential to support and improve the quality of a customers decision.
## Paradigms of recommender systems
There are many different ways to design a recommendation system. What they have in common is they take input into a _recommendation component_ and uses it to output a _recommendation list_. What varies in the different paradigms is what goes into the recommendation component. One of the inputs to get personalized recommendations is a user profile and contextual parameters.
_Collabarative recommender systems_, or "tell me what is popular among my peers", uses community data.
_Content-based recommender systems_, or "show me more of what I've previously liked", uses the features of products.
_Knowledge based recommender systems_, or "tell me what fits my needs", uses both the features of products and knowledge models to predict what the user needs.
_Hybrid recommender systems_ uses a combination of the above and/or compositions of different mechanics.