TDT4215: Web-intelligence
# Curriculum
As of spring 2016 the curriculum consists of:
- __A Semantic Web Primer__, chapter 1-5, 174 pages
- __Sentiment Analysis and Opinion Mining__, chapter 1-5, 90 pages
- __Recommender Systems__, chapter 1-3, and 7, 103 pages
- _Kreutzer & Witte:_ [Opinion Mining Using SentiWordNet](http://stp.lingfil.uu.se/~santinim/sais/Ass1_Essays/Neele_Julia_SentiWordNet_V01.pdf)
- _Turney:_ [Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews](http://www.aclweb.org/anthology/P02-1053.pdf)
- _Liu, Dolan, & Pedersen:_ [Personalized News Recommendation Based on Click Behavior](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.308.3087&rep=rep1&type=pdf)
# Semantic Web
## The Semantic Web Vision / Motivation
Semantic Web uses languages specifically designed for data:
- Resource Description Framework (RDF)
- Web Ontology Language (OWL)
- Extensive Markup Language (XML)
Together these languages can describe arbitrary things like people, meetings or airplane parts.
## Ontology
An ontology is a formal and explicit definition of types, properties, functions, and relationship between the entities, which result in an abstract model of some phenomena in the world. Typically an ontology consist of classes arranged in a hierarchy. There are several languages that can describe an ontology, but the achieved semantics vary.
RDF is a data-model used to define ontologies. It's a model that is domain-neutral, application-neutral, and it supports internationalization. RDF is an abstract model, and therefore not language-specific. XML is often used to define RDF data, but it is not a necessity.
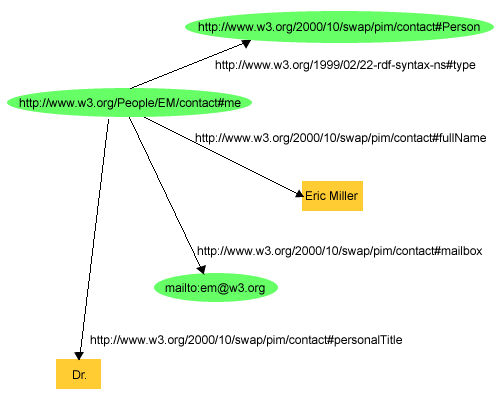
### Serialization formats
N-triples, Turle, RDF/XML, RDF/JSON.
N-triples
: It is plain text format for encoding an RDF graph.
Turtle
: Turtle can only serialize valid RDF graphs. It is generally recognized as being more readable and easier to edit manually than its XML counterpart.
RDF/XML
: It expresses RDF graph as XML document.
RDF/JSON
: It expresses RDF graph as JSON document.
- Classes and subclasses
- Properties and sub-properties
## OWL (Web ontology language)
### Basics of OWL
### Language constructs
#### Classes
#### Properties
#### Property characteristics
#### Cardinality
#### Individuals
#### Others
### Semantics and Reasoning
#### Description Logics
## Ontology guidelines
# Sentiment analysis
Sentiment analysis is about searching through data to get people's opinions about something. Sentiment analysis is also called opinion mining, opinion extraction, sentiment mining, subjectivity analysis, affect analysys, emotion analysis, or review mining.
## Basics of Sentiment analysis
Sentinemt analysis is important because opinions drive decisions. People will seek other people's opinions when buying something. It is useful to be able to mine opinions on a product, service or topic.
Businesses and organizations are interested in knowing what people think of their products. Individuals are interested in what others think of a product or service. We would like to be able to do a search like "How good is iPhone" and get a general opinion on how good it is.
With "explosions" of opinion data in social media and similar applications it is easy to gather data for use in decisionmaking. It is not always necessary to create questionnaires to get peoples opinions. It can, however, be difficult to extract meaning from long blogposts and arcticles, and make a summary. This is why we need _Automated Sentiment analysis systems_.
There are two types of evaluation:
- Regular opinions ("This camera is great!")
- Comparisons ("This camera is better than this other camera.")
The basic components of an opinion are:
- Opinion holder (Whoever holds the opinion)
- Entity (The entity on which the opinion is expressed)
- Opinion (The actual opinion being held)
An entity can be divided into subcomponents, like a camera having both a lens and a battery. These subcomponents are called _aspects_.
## Sentiment analysis models
### Model of an entity
### Model of a review
### Model of an opinion
### Different Levels of Analysis
Research has mainly been done on three different levels.
#### Document-level
Document-level sentiment classification works with entire documents and tries to figure out of the document has a positive or negative view of the subject in question. An example of this is to look at many reviews and see what the authors mean, if they are positive, negative or neutral.
#### Sentence-level
Sentence-level sentiment classification works with opinion on a sentence level, and is about figuring out if a sentence is positive, negative or neutral to the relevant subject. This is closely related to _subjectivity classification_, which distinguishes between objective and subjective sentences.
#### Entity and aspect-level
Entity and aspect-level sentiment classification wants to discover opinions about an entity or it's aspects. For instance we have the following sentence, "The iPhone’s call quality is good, but its battery life is short", two aspects are evaluated: call quality and battery lifetime. The entity is the iPhone. The iPhone's call quality is positive, but the battery duration is negative. It's hard to find and classify these aspects, as there are many ways to express positive and negative opinions, metaphors, comparisons and so on.
## Sentiment Lexicon and Its Issues
Some words can be identified as either positive or negative immediately, like good, bad, excellent, terrible and so on. There are also subsentences/phrases that can be identified as positive or negative. A list of such words or sentences is called a sentiment lexicon.
Use of just this is not enough. Below are several known issues:
1. Words and phrases can have different meaning in different contexts. For example, "suck" usually has a negative meaning, but can be positive if put in the right context: "This vacuum cleaner really sucks".
2. Sentences containing sentiment words sometimes do not reflect a sentiment. For example, "If this product X contain a _great_ feature Y, I'll buy it". _Great_ does not express a positive or negative opinion on the product X.
3. Sarcastic sentences are hard to deal with. They are mostly found in political discussions, e.g. "What an awesome product! It stopped working in two days".
4. Sentences without sentiment words can also express opinions. "This laptop consumes a lot of power.", reflects a partially negative opinion about the laptop, but the sentence is also objective as it states a fact.
## Opinion lexicon generation
## Aspect-based opinion mining
## Opinion mining of comparative sentences
## Opinion spam detection
## Unsupervised search-based approach
## Unsupervised lexicon-based approach
# Recommender systems
## Problem domain
Recommender systems are used to match users with items. This is done to avoid information overload and to assist in sales by guiding, advising and persuading individuals when they are looking to buy a product or a service.
Recommender systems elicit the interests and preferences of an individual, and make recommendations. This has the potential to support and improve the quality of a customers decision.
Different recommender systems require different designs and paradigms, based on what data can be used, implicit and explicit user feedback and domain characteristics.
## Purpose and success criteria
Different perspectives/aspects:
– Depends on domain and purpose
– No holistic evaluation scenario exists
Retrieval perspective:
– Reduce search costs
– Provide "correct" proposals
– Users know in advance what they want
Recommendation perspective:
– Serendipity – idendify items from the Long Tail
– Users did not know about existence
Prediction perspective:
– Predict to what degree users like an item
– Most popular evaluation scenario in research
Interaction perspective
– Give users a "good feeling"
– Educate users about the product domain
– Convince/persuade users - explain
Finally, conversion perspective
– Commercial situations
– Increase "hit", "clickthrough", "lookers to bookers" rates
– Optimize sales margins and profit
## Paradigms of recommender systems
There are many different ways to design a recommendation system. What they have in common is they take input into a _recommendation component_ and uses it to output a _recommendation list_. What varies in the different paradigms is what goes into the recommendation component. One of the inputs to get personalized recommendations is a user profile and contextual parameters.
_Collabarative recommender systems_, or "tell me what is popular among my peers", uses community data.
_Content-based recommender systems_, or "show me more of what I've previously liked", uses the features of products.
_Knowledge based recommender systems_, or "tell me what fits my needs", uses both the features of products and knowledge models to predict what the user needs.
_Hybrid recommender systems_ uses a combination of the above and/or compositions of different mechanics.
## Collaborative filtering
## Content-based flitering
## Semantic Vector space model