TDT4173: Machine Learning and Case-Based Reasoning
# Introduction
## Well Posed Learning Problems
> __Definition__: A computer program is said to __learn__ from experience _E_ with respect to some class of tasks _T_ and performance measure _P_ if its performance at tasks in _T_, as measured by _P_, improves with experience _E_.
An example of a task, inspired by [MarI/O](https://www.youtube.com/watch?v=qv6UVOQ0F44):
- Task _T_: Playing the first level of Super Mario Bros.
- Performance measure _P_: How far the Mario character is able to advance.
- Training experience _E_: Playing the level over and over.
## Designing a learning system
- __Direct and indirect training examples__: Whether the system will receive examples of _one_ choice and whether it’s bad or good, or only a sequence of choices and their final outcome.
- __Credit assignment__: Determining the degree to which each choice in a sequence contributes to the final outcome (in indirect examples).
### Adjusting weights (LMS weight update rule)
The ideal target function can be called $V$. This is the magical best function which we are trying to approximate with our machine learning. The approximation that we achieve is called $\hat{V}$. One training example can be called $b$, and each of its attributes is called $x_i$. The output for a given example is thus $\hat{V}(b)$.
Let’s imagine that the training example $b$ has $n$ attributes. In a program which represents $\hat{V}(b)$ as a linear function $\hat{V}(b) = w_0 + \sum_{i=1}^n w_i \times x_i$, it is possible to approximate $V$ with the following method, called the Least Mean Squares (LMS) training rule:
For each training example $\langle b, V_{train}(b)\rangle$:
- Use the current weights to calculate $\hat{V}(b)$
- For each weight $w_i$, update it as $w_i \leftarrow w_i + \eta (V_{train}(b) - \hat{V}(b)) x_i$
$\eta$ is a small constant (e.g. 0.1) that dampens the size of the weight update.
## Learning
"Any process by which a system improves performance" -H. Simon
Basic definition: "Methods and techniques that enable computers to improve their performance through their own experience"
## Why machine learning?
* Today, lots of data is collected everywhere (Big Data)
* There are huge data centers
# Concept learning and the General-to-Specific Ordering
Concept learning is about inferring a boolean-valued function from training examples of input and output.
We may for instance be trying to learn whether a certain person will be enjoying sports on a particular day given different attributes of the weather. Let us call this the _EnjoySports_ target concept.
## A concept learning task
Let's take a look at the _EnjoySports_ target concept. When learning the target concept, the learner presented a set of training examples. Each instance is represented by the attributes Sky, AirTemp, Humidity, Wind, Water and Forecast.
|| Example || Sky || AirTemp || Humidity || Wind || Water || Forecast || EnjoySport ||
|| 1 || Sunny || Warm || Normal || Strong || Warm || Same || Yes ||
|| 2 || Sunny || Warm || High || Strong || Warm || Same || Yes ||
|| 3 || Rainy || Cold || High || Strong || Warm || Change || No ||
|| 4 || Sunny || Warm || High || Strong || Cool || Change || Yes ||
### The inductive learning hypothesis
Our learning task is to determine a hypothesis $h$ which is identical to the target concept $c$ over the entire set of instances, $X$. However, our only information about the target concept $c$ is our knowledge of it through the training examples themselves. (If we had already known the true $c$, there wouldn’t be much of a point to learning it.)
In order to determine what hypothesis will work best on unseen examples, we have to make an assumption (i.e. we can’t really prove it): What works best for the training examples will work best for the unseen examples. This is the _fundamental assumption of inductive learning_.
> __The inductive learning hypothesis__: Any hypothesis found to approximate the target function well over a sufficiently large set of training examples will also approximate the target function well over other unobserved examples.
## Hypothesis space
## Find-S
## Candidate elimination algorithm
This is an important part of the curriculum. Learn it.
## Inductive bias
TL;DR: Assumptions that you need to make in order to generalize
An inductive bias is the set of assumptions needed to take some new input data, which the system has _not_ encountered before, and predict the output. E.g: a self-driving car may have been trained to avoid cats in the road, but suddenly it encounters a dog. What should it do?
If the system does not have an inductive bias, then it has not learned anything other than reacting to the specific examples that it has been trained on. In that case, it is basically just a [key-value store](https://en.wikipedia.org/wiki/Key-value_database) for its training examples. An inductive bias is essential to machine learning.
There are two types of bias: __Representational bias__ and __Search bias__. For example, in decision tree learning, there is no representational bias (because anything can be represented), but there is search bias. The search is greedy and ID3 keeps the most important information high up in the tree tends to produce the shortest possible decision tree. The candidate elimination algorithm has representational bias because it cannot represent anything. It assumes that the solution to the problem can be expressed as a conjunction of concepts.
# Decision Tree Learning
> Decision tree learning is a method for approximating discrete-valued target functions in which the learned function is represented by a decision tree.
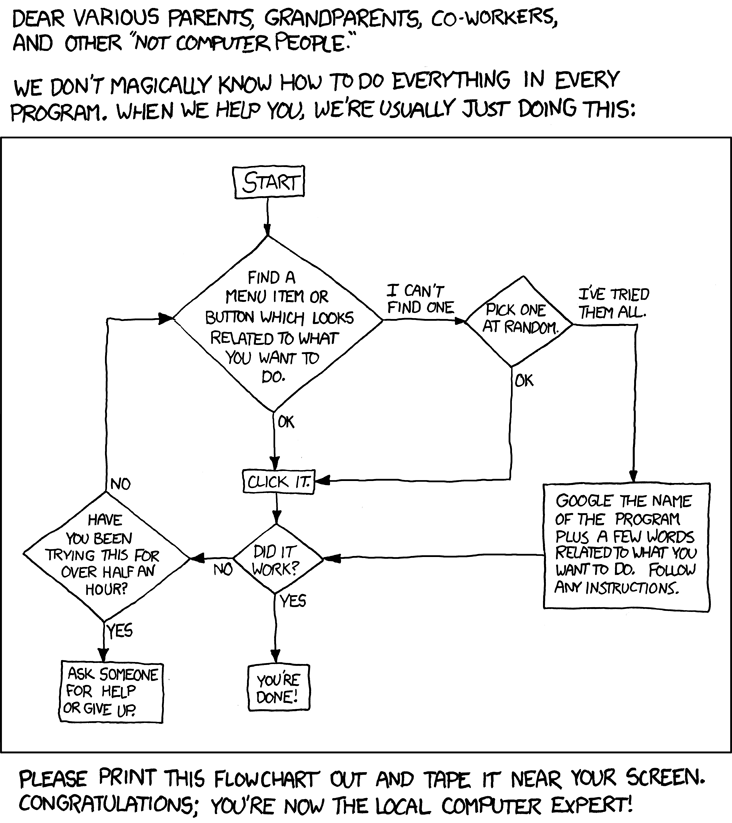
_This flowchart could be reshaped to a decision tree. (CC-BY-NC 2.5 Randall Munroe)._
## ID3 algorithm
The ID3 algorithm relies on two important, related concepts: _entropy_ and _information gain_.
- Entropy: How evenly distributed (homogenous) the examples are.
- Information gain: The expected reduction in entropy by splitting the examples using a certain attribute.
### Information entropy
Khan Academy has [a very helpful video on information entropy](https://www.khanacademy.org/computing/computer-science/informationtheory/moderninfotheory/v/information-entropy). In short, entropy is a measure of how many "yes/no" questions you have to ask _on average_ in order to get the information you want. Groups with even distributions have high entropy while groups with uneven distributions have low entropy.
#### Explain it like I’m five
Imagine guessing a random letter tile that your friend has drawn from the letters in Scrabble. The Scrabble letters are not evenly distributed: There are more tiles with the letter E than the letter W. Thus, by guessing in a smart way, you would be able to target the most frequent letters first.
Now imagine guessing a random letter from a collection with only one tile for each letter from A to Z. No letter is more probable than the other, and thus you could not target any letters specifically. __Because you have to use more guesses to guess a random letter than a Scrabble tile, the collection of random letters have a higher entropy than Scrabble tiles.__
#### Explain it like I’m a professor
The formula for the entropy of a collection $S$ which has an attribute which can take on classifications $c \in C$ is
$$ Entropy (S) \equiv \sum_{c\in C} p_c \times - log_2 (p_c)$$
$p_c$ is the probability that a random example drawn from S will take on a classification from the total number of classifications. For instance, C could be all the letters of the alphabet. If drawing a random letter from an English text, $p_c$ for the letter _e_ would be 0.12.
The $-log_2(p_i)$ is the expected encoding length for the classification: If we wanted the most efficient encoding, we would encode a symbol that occurs 50 percent of the time with one bit, a symbol that occurs 25 percent of the time with 2 bits, etc.
A lot of the time, we work with boolean classifications. In that case, the formula simplifies to
$$ Entropy(S) \equiv p_\oplus \times -log_2(p_\oplus) + p_\ominus \times-log_2(p_\ominus)$$
### Information Gain
Let's explain the concept "information gain" by example. Suppose you're playing the game "Guess who?" where you see a set of cards and you are supposed to guess which card matches the opponent's card.

_An example of Guess Who (CC-BY-SA 3.0 Matěj Baťha)_
You may ask the opponents yes/no questions to eliminate candidates. If you are smart, you ask questions that eliminate many candidates no matter the answer to the question. For example, if you see 10 women and 10 men, you should ask "Is the person a man?" which will eliminate half of the candidates when you get the answer (yes or no). This answer gives you much information about the solution, so the "gender" attribute has high information gain. More formally, it reduces the information entropy much. In a decision tree, this is the kind of attribute you'd want to split on high up in the tree.
### The algorithm
Now, let's explain what ID3 actually does. It generates a decision tree from a data set. It's recursive. Roughly, here's what the algorithm does:
ID3(examples, target attribute, attributes)
Create a root node
If all examples have the same classification
Return a leaf node with that class
Else If there are no more attributes to split on
Return a leaf node with the most common class of the examples in the parent node
Else
Find the best attribute to split on, based on information gain
Split on that attribute
For each branch, run ID3
For all the details, see [Wikipedia](https://en.wikipedia.org/wiki/ID3_algorithm)
## Prefer short hypotheses
Occam's razor: Prefer the simplest hypothesis that fits the data. Or in other words: If two decision trees fit the data equally well, prefer the shortest tree.
## Overfitting
Decision trees can run into the problem of overfitting. This usually occurs when there is noise in the training data (which is often the case).
Techniques for reducing overfitting:
* Stop growing then data split is not statistically significant
* Post prune decision tree
* Minimum Description Length principle for pruning decision trees: minimize size of tree and minimize validation error
* Select the best tree by measuring performance over validation data set
## Cross validation
Split the data set into more than one part. Train the learner on one part (training set) and test its performance on the other. You do this to test how well the learner generalizes.
# Evaluating Hypotheses
# Instance-Based Learning
# Learning Sets of Rules
# Analytical Learning
# Case–Based Reasoning
# Deep Learning
# Support Vector Machines
# Linear regression
There are two types of machine learning problems: classification and predicting numbers. If you're predicting numbers, for example electric energy consupmtion on a given day, then you may for example use linear regression.
Linear regression is about trying to find a plane or line that fits the training data points. The squared error is minimized by tuning the parameters of the function to fit the data points. A gradient method is used in the iterative method that tunes the parameters toward a good fit. There's a "learning rate" constant.
Remember, extrapolation is not always suitable

For the exam in 2016, there is probably no need to remember formulas you'd need for doing linear regression. Being able to explain the main idea should be enough.