TDT4160: Datamaskiner og digitalteknikk
Innledning
Dette kompendiumet tar sikte på å forklare essensen av faget TDT4160. Informasjonen som gis er i stor grad basert på kursboken, øvinger og forelsninger. Merk at dette faget har byttet pensum i 2024.
Kursboken i TDT416 er følgende:
Patterson and Hennessy, Computer Organization and Design -- RISC-V Edition: The Hardware Software Interface (2nd Edition), Morgan Kaufmann Publishers, 2020, Paperback ISBN: 978-0-12-820331-6, eBook ISBN: 9780128245583
Følgende kapitler i Patterson and Hennessy er pensum:
- Kapittel 1.1 til 1.13
- Kapittel 2.1 til 2.12, 2.14, 2.22 og 2.23
- Kapittel 3.1 til 3.6, 3.9 og 3.10
- Kapittel 4.1 til 4.11, 4.15 og 4.16
- Kapittel 5.1 til 5.4, 5.6, 5.7, 5.10, 5.16 og 5.17
- Kapittel 6.1 til 6.8, 6.11, 6.14 og 6.15
- Appendiks A-1 til A-3, A-5, A-7 til A-11 (unntatt beskrivelsene av Verilog-kode)
I tillegg er øvingene og forelesningene pensum.
Online sections er tilgjengelig her: https://www.elsevier.com/books-and-journals/book-companion/9780128203316
(informasjon gitt i fra BlackBoard-siden for høst 2025)
Alle har lov til å redigere dette kompendiet, så foreslå gjerne forbedringer. Vær oppmerksom på at dette kompendiet er skrevet av studenter, så vær kritisk til det du leser.
Kapittel 1 --- Computer Abstractions and Technology
1.1 Introduction
Vi bruker datamaskiner overalt, i blant annet biler, telefoner, og innebgyde systemer (embedded). Personlige datamaskiner (Personal Computers (PC)) er datamsskiner designet for å brukes av en bruker, gjerne med et grafisk grensenitt og enheter som et tastatur og en mus. Servere er datamaskiner som brukes for å kjøre større programmer, gjerne rettet mot flere brukere, gjerne samtidig, og er ofte tilgjengelig via et nettverk. Supercomputers er datamskiner med høyest ytelse og kostnad, og er gjerne laget som servere. Disse har gjerne flere terabytes(TB) med minne(1,000,000,000,000 (10^(12)) bytes. Innebgyde datamaskiner (embedded computer) er en datamaskin innen en annen enhet som er brukt for å kjøre et gitt programm eller aplikasjon. Telefoner og nettbrett er Personal mobile devices (PMDs)(personlige mobile enheter).
Cloud Computing (skytjenester) refererer til store samlinger av servere, gjerne på et datasenter, som man kan knytte seg til via internettet og brukes til bl.a lagring. Software as a Service(Saas) er en tjeneste som leverer software som en tjeneste over internettet, gjerne gjennom en browser på en lokal enhet i stedet for binær kode som må installeres på datamskinen. Eksempler er søkemotorer og sosiale media.
Lagret-program datamaskiner (stored-program computers)
Data og program er begge lagret i elektronisk minne. Datamaskinen holder styr på hva som er data og hva som er instruksjoner. Maskinen henter instruksjoner og data blir overført mellom minne og ALU.
(Von Neumann- og Harvard-arkitektur er ikke like mye pensum i ny lærebok, men greit å vite!)
Von Neumann- og Harvard-arkitektur
En datamaskin med en von Neumann-arkitektur, lagrer data og instruksjoner i det samme minnet, mens en datamaskin med en Harvard-arkitektur lagrer data og instruksjoner i separate minner. Begge har lagret-program design.
Von Neumann arkitektur
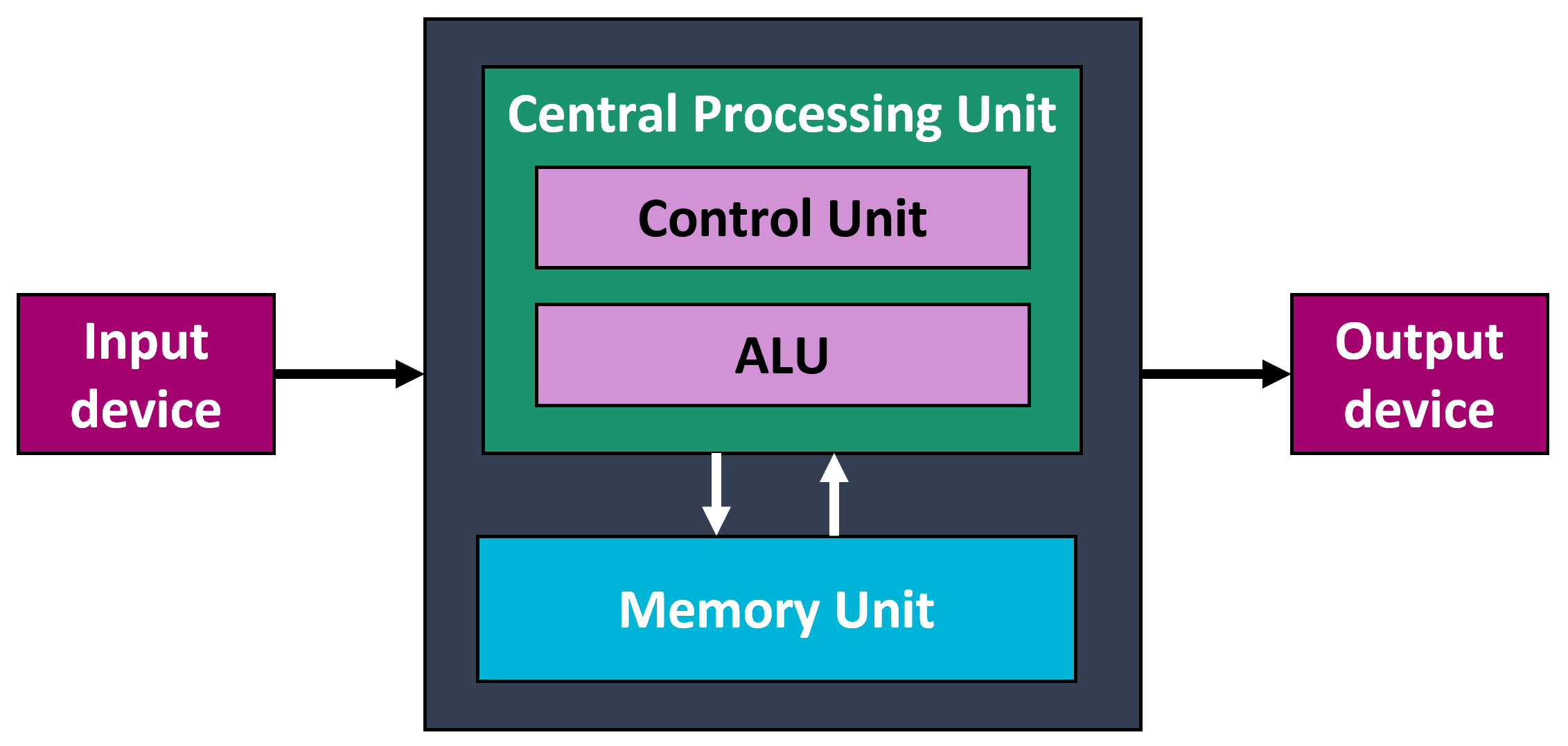
Et teoretisk design av en lagret-program datamaskin som fungerer som grunnlaget for nesten alle moderne datamaskiner. Von Neumann-arkitekturen beskriver en maskin med fem grunnleggende deler: minnet, den aritmetiske logiske enheten, kontrollenheten og input- og outpututstyret.
- Von Neumann arkitektur
- Datamaskinsystemer er bygd opp av tre typer komponenter: prosessorer, minner og I/O-enheter
- Prosessor (CPU)
- Delen av datamaskinen som henter instruksjoner enkeltvis fra et minne, dekoder dem og utfører dem.
- Minne
- Delen av datamaskinen der programmer og data lagres.
- I/O-enheter (input/output)
- Delene av datamaskinen som brukes til å overføre informasjon fra og til omverdenen.
1.2 Eight Great Ideas in Computer Architecture
1. Moore's Law
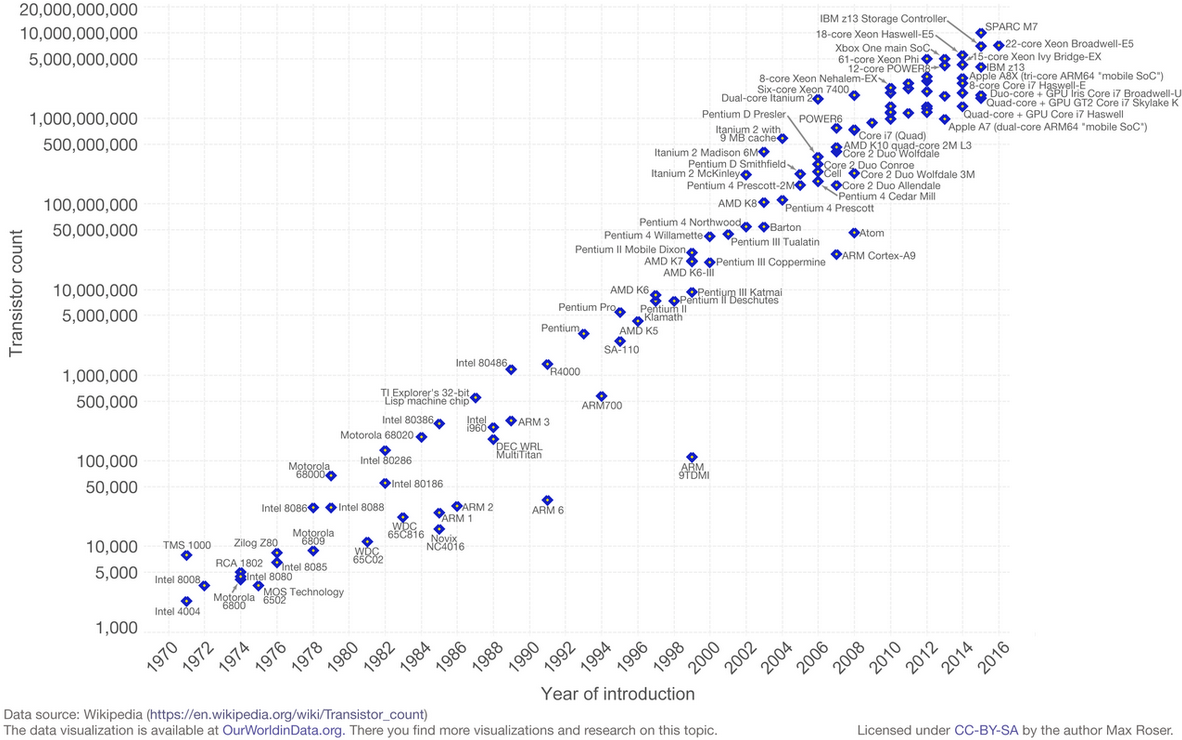
Moores lov er observasjonen at antall transistorer i en tett integrert krets dobles omtrent hvert annet år. Observasjonen er oppkalt etter Gordon Moore, medgründeren av Fairchild Semiconductor og Intel. Hans artikkel fra 1965 beskrev en dobling hvert år i antall komponenter per integrert krets, og anslo at denne veksten ville fortsette i minst et tiår til. I 1975, ved en vurdering av det neste tiåret, reviderte han prognosen til en dobling hvert annet år. Perioden er ofte sitert som 18 måneder på grunn av en spådom fra Intel-leder David House (som er en kombinasjon av effekten av flere transistorer og at transistorene er raskere)
2. Use Abstraction to Simplify Design
Ha ulike detaljnivå av en enhet, program osv. Målet er å kunne forklare et konsept med ulike abstraksjonsnivå, altså ulike nivå av detalj.
3. Make the Common Case Fast
I stedet for å fokusere for å optimalisere sjeldne tilfelle, fokuserer man heller å å gjøre det som skal gjøres ofte så optimalisert som mulig. Uansett hvor mye man optimaliserer operasjoner som utføres i parallell vil instruksjoner/arbeidet som utføres sekvensiellt være limiterende faktor, hvis common case er det sekvensielle arbeidet er det lurt å optimalisere arkitekturen til hetrogene maskiner altså maksiner med dedikerte prosessorer for arbeidet som skal utføres.
4. Performance via Parallelism
Om man kjører operasjoner i parallell, vil man få mer ytelse.
5. Performance via Pipelining
Boka bruker en analogi av pipelining hvor det illustreres en rekke av folk, som står side om side, og leverer en bøtte av vann mellom seg for å slukke en brann. Dette demonstrerer pipelining(samlebbånd på norsk), da man sparer ressurser på at en og en skal levere vann.
6. Performance via Prediction
"Spør heller om tilgivelse enn om lov". I flere tilfelle kan det nytte seg ytelsesmessig å gjette hva neste operasjon er, for å spare ressurser på å vente på hva svaret er. Dette er forutsett at man kan gjette veldig strategisk.
7. Hierarchy of Memories
Datamaskiner har gjerne et hierarki av minne, der det raskeste og minste er på toppen av hierarkiet, mens det tregeste og største minnet er på bunnen. Kostnad av minnet er ofte invers relativ av størrelsen (mindre minne (størrelse), høyere kostnad per størrelsesenhet).
8. Dependability via Redundancy
For å skape gode systemer krever man at systemene er pålitelige (dependable) ved at de bl.a kan ta over og ser når feil oppstår. Man trenger også redundancy som forsikrer seg om at det er en "plan B".
Kapittel 2 --- Instructions
2.1 Introduction
For å programmere en datamaskin sin hardware, må man "snakke" dens språk. Dette er da i form av instruksjoner. Hver datamaskin har et instruksjonssett, et "vokabular" for å kunne gi "kommandoer" til en datamaskinarkitektur. Vi jobber med instruksjonssettet RISC-V (uttalt "risk five").
En datamaskin bruker stored program concept, som er ideen at instruksjoner og data kan bli lagret i minnne som nummer (en rekke med binære tall som 0 og 1, som kan utrykkes med desimal).
Datamaskinsystemer er bygd opp av tre typer komponenter: prosessorer, minner og I/O-enheter.
Prosessorer
Oppgaven til en prosessor er å hente instruksjoner enkeltvis fra et minne, dekode dem og utføre dem. Hent-dekod-utfør-syklusen kan alltid beskrives som en algoritme og utføres faktisk noen ganger av et programvaretolkeprogram (interpreter) som kjører på et lavere nivå. For å øke hastigheten har mange datamaskiner nå en eller flere pipeliner eller har et superskalært design med flere funksjonelle enheter som opererer parallelt. En pipeline gjør at en instruksjon kan deles inn i trinn og trinnene for forskjellige instruksjoner utføres samtidig. Flere funksjonelle enheter er en annen måte å oppnå parallellitet uten å påvirke instruksjonssettet eller arkitekturen som er synlig for programmereren eller kompilatoren.
CPU (Central Processing Unit) er "hjernen til datamaskinen". Dens funksjon er å kjøre programmer lagret i hovedminnet ved å hente instruksjonene deres, undersøke dem og deretter utføre dem etter hverandre. Komponentene er koblet sammen med en buss, som er en samling av parallelle ledninger for overføring av adresse, data og kontrollsignaler. Busser kan være eksterne til CPU, koble den til minne og I/O-enheter, men også interne til CPU.
CPU-en er sammensatt av flere forskjellige deler.
- Kontrollenheten
- Komponent som er ansvarlig for å hente instruksjoner fra hovedminnet og bestemme typen deres.
- Den aritmetiske logiske enheten
- Komponent som utfører operasjoner som addisjon og boolsk AND. Nødvendig for å utføre instruksjonene.
CPU-en inneholder også et lite høyhastighetsminne som brukes til å lagre midlertidige resultater og kontrollinformasjon. Dette minnet består av et antall registre som hver har en gitt størrelse og funksjon.
- Programteller (PC)
- Peker på neste instruksjon som skal hentes for utførelse.
- Instruksjonsregister (IR)
- Holder instruksjonen som utføres for øyeblikket.
- Minneadresseregister (MAR)
- Inneholder adressen til minneplasseringen som prosessoren for øyeblikket har tilgang til.
- Minnebuffer/dataregister (MDR)
- Inneholder dataene som overføres til eller fra minneplasseringen som for øyeblikket er gitt tilgang til.
De fleste datamaskiner har også en rekke andre registre, noen av dem for generelle formål så vel som noen for spesifikke formål.
Minne
Minnet er den delen av datamaskinen der programmer og data lagres. Minner kan kategoriseres som primære eller sekundære.
Primærminne
Primærminnet brukes til å holde programmet som kjøres for øyeblikket. Tilgangstiden er kort (på det meste noen få titalls nanosekunder) og er uavhengig av adressen som aksesseres. Cacher reduserer denne tilgangstiden enda mer. De er nødvendige fordi prosessorhastigheter er mye høyere enn minnehastigheter, noe som betyr at å måtte vente på minnetilgang hele tiden reduserer prosessorkjøringen betydelig. Noen minner er utstyrt med feilrettingskoder for å øke påliteligheten.
Sekundært minne
Sekundære minner har derimot tilgangstider som er mye lengre (millisekunder eller mer) og er ofte avhengig av plasseringen til dataene som leses eller skrives. Bånd, flashminne, magnetiske disker og optiske disker er de vanligste sekundære minnene. Magnetiske disker kommer i mange varianter, inkludert IDE-disker, SCSI-disker og RAIDS. Optiske disker inkluderer CD-ROM, CD-R, DVD og Blu-ray.
Statisk og dynamisk RAM
Statisk RAM: Raskere, stor minnecelle (område), bruker mye strøm, trenger ikke å oppdateres, enkelt grensesnitt.
Dynamisk RAM: Tregere, liten minnecelle (område), bruker mindre strøm, må oppdateres, komplisert grensesnitt.
Cache
Lite, raskt minne. De mest brukte minneordene oppbevares i hurtigbufferen. Når prosessoren trenger et ord, ser den først i hurtigbufferen. Bare hvis ordet ikke er der, går den til hovedminnet. Hvis en betydelig brøkdel av ordene er i hurtigbufferen kan den gjennomsnittlige tilgangstiden reduseres kraftig.
Skjuling av ventetid
Ved å redusere gjennomsnittlig tilgangstid kan man "skjule" latens.
Minnehierarki
Ulike typer minner kan ordnes i et hierarki med raskeste, minste og dyreste øverst, og tregeste, største og minst kostbare nederst.
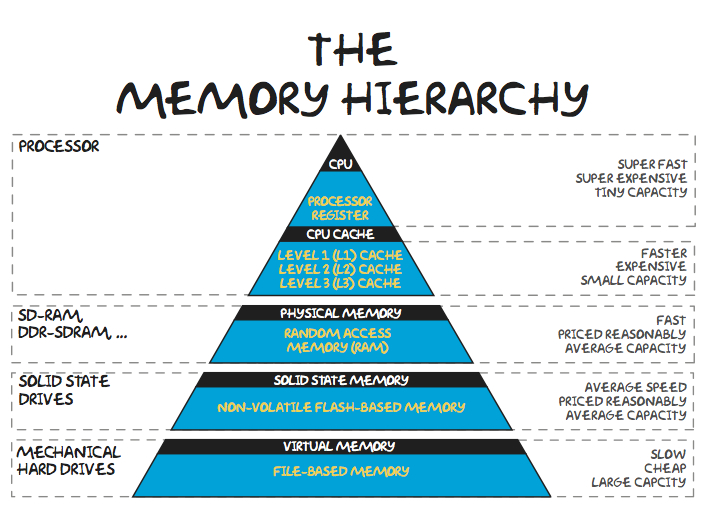
Prosessorminnegap
Prosessorytelsen har forbedret seg mye raskere enn minnetilgangstiden.
I/O-enheter
I/O-enheter brukes til å overføre informasjon inn og ut av datamaskinen. De er koblet til prosessoren og minnet med en eller flere busser. Eksempler er terminaler, mus, spillkontrollere, skrivere og modemer. De fleste I/O-enheter bruker ASCII-tegnkoden, selv om Unicode også brukes og UTF-8, en av Unicode-standardene, får aksept etter hvert som dataindustrien blir mer nettsentrisk og globalisert.
2.2 Operations of the Computer
I en RISC-V instruksjon som add a, b, c, vil datamaskinen ta inn verdien til variablene b og c og legge de i a. Vær obs på denne rekkefølgen.
Eksempel på addisjon av flere variabler (engelsk):
The following sequence of instructions adds the four variables:
add a, b, c// The sum of b and c is placed in a
add a, a, e// The sum of b, c, d, and e is now in a
add a, a, d// The sum of b, c, and d is now in a
Thus, it takes three instructions to sum the four variables.
// Utgjør kommentarer i koden.
2.3 Operands of the Computer Hardware
I motsetning til variabler man er vandt med i annen kontekst, jobber man i datamaskinarkitektur med registre. I RISV-V har man 32 ulike registre. Størrelsen på et register i RISV-V arkitektur er enten 64 bits (doubleword) eller 32 bits (word).
Noen instruksjoner i RISC-V er data transfer instructions, som innebærer å overføre data mellom minne og registre. For å gjøre dette, må man vite adressen til dette dataelementet, som er en verdi som indikerer plasseringen til dataen i en minnestruktur.
I instruksjoner kan man også bruke konstante verdier. Eksempel (på engelsk):
An alternative that avoids the load instruction is to offer versions
of the arithmetic instructions in which one operand is a constant.
This quick add instruction with one constant operand is called add
immediate or addi. To add 4 to register x22, we just write
addi x22, x22, 4 // x22 = x22 + 4
RISC-V har et register, x0som er hardkodet til verdien null(0).
2.4 Signed and Unsigned Numbers
Least Significant Bit - LSB (til høyre i ordet) Most Significant Bit - MSB (til venstre i ordet)
Toerskomplement (two's complement) eksempel (på engelsk):
Suppose we're working with 8 bit quantities (for simplicity's sake) and suppose we want to find how -28 would be expressed in two's complement notation. First we write out 28 in binary form.
00011100
Then we invert the digits. 0 becomes 1, 1 becomes 0.
11100011
Then we add 1.
11100100
That is how one would write -28 in 8 bit binary.
For å sjekke om et tall er positivt eller negativt, trenger en datamaskinarkitektur bare sjekke første bit, om det er 1 (negativt tall) eller 0 (positivt tall). Dette er kalt sign bit (tenk minus/plus sign på engelsk).
2.5 Representing Instructions in the Computer
2.6 Logical Operations
arith = arithmetic AND, OR, XOR og NOT er bit-by-bit
| Logical operations | C operators | Java Operators | RISC-V instructions |
| Shift left | << | << | sll, slli |
| Shift right | >> | >>> | srl, srli |
| Shift right arith | >> | >> | sra, srai |
| AND | & | & | and, andi |
| OR | | |
| |
or, ori |
| XOR | ^ | ^ | xor, xori |
| NOT | ~ | ~ | xori |
Kapittel 3 --- Arithmetic for Computers
Gates
Computers are constructed from integrated circuit chips containing tiny switching elements called gates. The most common gates are AND, OR, NAND, NOR, and NOT. Simple circuits can be built up by directly combining individual gates, although everything can be built using NOR or NAND gates.
Complex circuits
More complex circuits are multiplexers, demultiplexers, encoders, decoders, shifters, and ALUs. Arbitrary Boolean functions can be programmed using a FPGA. If many boolean functions are needed, FPGAs are often more efficient. The laws of Boolean algebra can be used to transform circuits from one form to another. In many cases more economical circuits can be produced this way.
Adders
Computer arithmetic is done by adders. A single-bit full adder can be constructed from two half adders. An adder for a multibit word can be built by connecting multiple full adders in such a way as to allow the carry out of each one feed into its left-hand neighbour.

A logical schematic for a full adder.
Memory
The components of (static) memories are latches and flip-flops, each of which can store on bit of information. These can be combined linearly into latches and flip-flops for memories with any word size desired. Memories are available as RAM, ROM, PROM, EPROM, EEPROM, and flash. Static RAMs need not be refreshed; they keep their stored values as long as the power remains on. Dynamic RAMs, on the other hand , must be refreshed periodically to compensate for leakage from the capacitors on the chip.
Bus
The components of a computer system are connected by buses. Many, but not all, of the pins on a typical CPU chip directly drive on bus line. The bus lines can be divided into address, data, and control lines. Synchronous buses are driven by a master clock. Asynchronous buses use full handshaking to synchronize the slave to the master.
Buses enables data and control signals to move around the CPU and memory. There are a number of different buses.
A bus is a communication channel through which data can be moved.
There are many buses in a computer; one example is the universal serial bus (USB), which can transfer data between the computer and external devices.
Control bus: Carries control signals around the CPU and memory indicating whether the operation is a read or a write and ensuring that the operation happens at the right time.
Address bus: Carries memory addresses for memory locations to be read from or written to.
Data bus: Carries data between the CPU and memory. For a write operation the CPU will put the data on the data bus to be sent to memory. For a read operation, the data will be taken from a memory block and sent to the CPU.
Example CPU Chips
The core i7 is an example of a modern CPU. Modern systems using it have a memory bus, a PCIe bus, and a USB bus. The PCIe interconnect is the dominant way to connect the internal parts of a computer at high speeds. The ARM is also a modern high end CPU but is intended for embedded systems and mobile devices where low power consumption is important. The Atmel ATmega168 is an example of a low-priced chip good for small, inexpensive appliances and many other price-sensitive applications.
Interfacing
Switches, lights, printers, and many other I/O devices can be interfaced to computers using parallel I/O interfaces. These chips can be configured to be part of the I/O space or the memory space, as needed. They can be fully decoded or partially decoded depending on the application.
3.2 Addition and Subtraction
Man vet at man får overflyt på et tall på toerskomplement(altså tallet kan ikke korrekt represnteres av gitt antall bit) når resultatet av to positive tall blir et negativt tall, og resultatet av to negative tall blir et positivt tall. Dette skyldes at det ekstra bit-et som blir brukt for å representere overflyten har "glidd" inn i sign-bitet, og man får da feil representasjon av tallet.
Knowing when an overflow cannot occur in addition and subtraction is all well and good, but how do we detect it when it does occur? Clearly, adding or subtracting two 64-bit numbers can yield a result that needs 65 bits to be fully expressed. The lack of a 65th bit means that when an overflow occurs, the sign bit is set with the value of the result instead of the proper sign of the result. Since we need just one extra bit, only the sign bit can be wrong. Hence, overflow occurs when adding two positive numbers and the sum is negative, or vice versa. This spurious sum means a carry out occurred into the sign bit. Overflow occurs in subtraction when we subtract a negative number from a positive number and get a negative result, or when we subtract a positive number from a negative number and get a positive result. Such a ridiculous result means a borrow occurred from the sign bit.
For unsigned tall, kan man se om det har skjedd overflyt om resultatet av en sum er mindre enn de to tallene som adderes og om resultatet av å trekke fra et tall er større enn forskjellen mellom de to tallene.
3.3 Multiplication
For å regne binær multiplikasjon for hånd, anbefaler jeg å se animasjonen fra denne nettsiden.

3.4 Division
Nettsiden nevnt i delen for multiplikasjon har også et godt verktøy for å se divisjon av binære tall for hånd.

Kapittel 4 --- The Processor
Prosessorer
Prosessesorer kan referer til flere forskjellige styre- og behandlingsenheter i elektroniske maskiner. I all hovedsak prater man om prosessorer i sammenheng med CPU (Central Prosessing Unit) og mikroprosessorer. Slike enheter utgjør kjernen av en moderne datamaskin, som står for all behandling av digitale og analoge signaler som mottas og sendes ut igjen til datamaskinen.
CPU
En Central Processing Unit (CPU) er "hjernen" til moderne datamaskiner. Hovedfunksjonen til en CPU er å utføre instruksjoner som er gitt av et dataprogram. Disse dataprogrammene er lagret i hovedlageret til CPUen. Dette gjøres ved at instruksjoner hentes inn til hovedprosessoren hvor den inspiserer og så sekvensielt kjører hver instruks. Hver av disse "instruksjonsettene" ligger i en buss.
Buss
En buss er en samling med parallelle ledninger som overfører adresser, rå data og kontrollsignaler. En buss kan eksistere som både en intern og ekstern komponent til en CPU.
Organisering i CPU
En CPU består av 3 hoveddeler, en aritmetisk logisk enhet (ALU), en rekke registere og en kontrollenhet. prosessoren består også av et hovedminne som inneholder midlertidige resultater fra utregninger gjort i hovedprosessoren.
ALU
En Aritmetisk logisk enhet er en enhet som gjør utregninger på de inputene i fra et dataregister. Disse registerene ligger sammen med ALUen i det som heter datapath. Operasjoner foregår ved at en instruksjon forteller ALUen at den skal gjøre operasjoner på to registere som ligger i data path. Disse to registeren hentes inn som input hvor det gjøres en operasjon på de, før resultatet blir enten lagret tilbake til registeret, eller at det lagres på minnet til maskinen. ALU kan gjøre grunnleggende aritmetiske operasjoner som addisjon og subtraksjon.
Synchronized bus-transfer:
The signal is syncronized with a clock
Asynchronized bus-transfer:
The signal is syncronized with a handshake
Components in CPU
Control Unit
Think about it as the "captain in the army". It recieves its orders from RAM in the form of an instruction and then breaks that instruction down into specific commands for the other components.
Arithmetic Logic Unit
One of the most important units under the command of the control unit is the Arithmetic Logic Unit (ALU). The ALU is what performs all the mathematical operations inside the CPU such as addition, subtraction and even comparisons. The ALU has two input-signals (often labeled input A and B) and one output-signal.
Normal process: Control unit recieves an instruction from RAM and proceeds to tell the the ALU what to do (what operation and input to use). The ALU then often outputs an answer. For some instructions (e.g. comparisons) the ALU doesn't need to comput an output - it will simply give a flag back to the contol unit.
Registers
The eight wires coming out of an ALU run to what is called a register. A register is a very simple component whos only job is to store a number temporarily. Registers acts just like RAM, only that they are inside the CPU making them faster and more useful for storing a number temporaily while instructions are being processed. When the ALU sends the output to a register, the value wont actually be saved until the control unit turns on the register set wire.
The CPU bus
The CPU bus connects the components inside the CPU to eachother, it makes it possible to move numbers from one components to another (like moving data from one register to another).
The Data Path
The heart of every computer is the data path. It contains some registers, one, two or three buses, and one or more functional units such as ALUs and shifters. The main execution loop consists of fetching some operands from the registers and sending them over the buses to the ALU and other functional unit for execution. The results are then stored back in the registers.
The data path can be controlled by a sequencer that fetches microinstructions form a control store. Each microinstruction contains bits that control the data path for one cycle. The bits specify which operands to select, which operation to perform, and what to do with the results. In addition, eahc microinstruction specifies its successor, typically explicitly by containing its address. Some microinstructions modify this base address by ORing bits into the address before it is used.
The IJVM Machine
The IJVM machine is a stack machine with 1-byte opcodes that push words onto the stack, pop words from the stack, and combine (e.g., add) words on the stack. A microprogrammed implementation was given for the Mic-1 microarchitecture. By adding an instruction fetch unit to preload the bytes in the instruction stream, many references to the program counter could be eliminated and the machine greatly sped up.
Microarchitecture Level Designs.
There are many ways to design the microarchitecture level. Many trade-offs exist, including two-bus versus three-bus designs, encoded versus decodeed microinstruction fields, presence or absence of prefetching, shallow or deep pipelines and much more. The Mic-1 is a simple, software-controlled machine with sequential execution and no parallelism. In contrast, the Mic-4 is a highly parallel microarchitecture with a seven-stage pipeline.
Improving performance
Performance can be improved in a variety of ways. Cache memory is a major one. Direct-mapped cashes and set-associative caches are commonly used to speed up memory refreshes. Branch prediction, both static and dynamic, is important, as are out-of-order execution, and speculative execution.
Examples of the microarchitecture level
Our three example machines, the Core i7, OMAP4430, and ATmega168, all have microarchitectures not visible to the ISA assemble-language programmers. The Core i7 has a complex scheme for converting the ISA instructions into micro-operations, caching them, and feeding them into a superscalar RISC core for out-of-order execution, register renaming, and ever other trick in the book to get the last possible drop of speed out of the hardware. The OMAP4430 has a deep pipeline, but is further relatively simple, with in-order issure, in-order execution, and in-order retirement. The ATmega168 is very simple, with a straightforward single main bus to which a handful of registers and one ALU are attached.
The instruction set is a set of instructions that a computer is able to understand and execute. The specifics of the instructions may vary from computer to computer, but in the following section the most common ones are listed.
The purpose of instructions sets
When writing a computer program, you don't want to write it using logic (boolean algebra) because it would be very inconvenient.
How a program executes
Programs are written by people (programmers) usually in a high level language such as java, c, python and so on. The code written in high level language needs to be compiled into assemble code which is language at a lower level. The assembly code will be put into an OS loader which loads the program into memory.
The instruction set architecture level is what most people think of as "machine language" although on CISC machines it is generally built on a lower layer of microcode. At this level the machine has a byte- or word-oriented memory consisting of some number of megabytes or gigabyes, and instructions such as MOVE, ADD, and BEQ.
Most modern computers have memory that is organized as a sequence of bytes, with 4 or 8 bytes grouped together into words. There are normally also between 8 and 32 registers present, each one containing one word. On some machines (e.g., Core i7), refrences to words in memory do not have to be aligned on natural boundaries in memory, while on others (e.g. OMAP4430, ARM), they must be. But even if words do not have to be aligned, performance is better if they are.
Instructions generally have one, two, or three operands, which are addressed using immediate, direct, register, indexed, or other addressing modes. Some machines have a large number of complex addressing modes. In many cases, compilers are unable to use them in an effective way, so they are unused. Instructions are generally available for moving data, dyadic and monadic operations, including arithmetic and Boolean operations, branches, procedure calls, and loops, and sometimes for I/O. Typical instructions move a word form memory to a register (or vice versa), add, subtract, multiply, or divide two registers or a register and a memory words, or compare two items in registers or memory. It is not unusual for a computer to have well over 200 instructions in its repertoire. CISC machines often have many more.
Control flow at level 2 is achieved using a variety of primitives, including branching, procedure calls, coroutine calls, traps, and interrupts. Branches are used to terminate one instruction sequence and begin a new one at a (possibly distant) location in memory. Procedures are used as an abstration mechanism, to allow a part of the program to be isolated as a unit and called from multiple places. Abstraction using procedures or the equivalent, it would be impossible to write any modern software. Coroutines allow two threads of control to work simultaneously. Traps are used to signal exceptional situations, such as arithmetic overflow. Interrupts allow I/O to take place in parallel with the main computation, with the CPU getting a signal as soon as the I/O has been completed.
The Towers of Hanoi is a fun little porblem with a nice recursive solution that we examined. Iterative solutions to it have been found, but they are far more complicated and elegant than the recursive one we studied.
Last, the IA-64 architecture uses the EPIC model of computing to make it easy for programs to exploit parallelism. It uses instruction groups, predication, and speculative LOADs to gain speed. All in all, it may represent a significant advance over the Core i7, but it puts much of the burden of parallelization on the compiler. Still, doing work at compile time is always better than doing it at run time
Common instructions
- LOAD
- Move data from RAM to registers.
- STORE
- Move data from registers to RAM.
- MOVE
- Copy data among registers.
- ADD
- Add two numbers together.
- COMPARE
- Compare one number with another.
- JUMP IF CONDITION
- Jump if condition to another address in RAM
- JUMP
- Jump to another address in RAM.
- OUT
- Output to a device.
- IN
- Input from a device such as a keyboard.
Instruction Formats
An instuction consists of an opcode, usually alongwith additional information such as where operands come from and where results go to. The general subject of specifying where the operands are (i.e, their addresses) is called addressing. There can be several possible formats for level 2 instructions. An instruction always has an opcode to tell what the instruction does. There can be zero, one, two, or three addresses present. On some machines, all instructions have the same length; on others there may be many different lengths. Instructions may be shorter than, the same length as, or longer than the word length. Having all the instructions be the same length is simmpler and makes decoding erasier but often wastes space, since all instructions then have to be as long as the longest one. Other trade-offs are also possible.
Addressing
Most instructions have operands, so some way is needed to specify where they are. This is called addressing.
- Immediate addressing
- The address part of an instruction actually contains the operand itself rather than an address or other information describing where the operand is.
Immediate addressing has the virtue of not requiring an extra memory reference ot fetch the operand. It has the disadvantage that only a constant can be supplied this way. Also, the numberof values is limited by the size of the field. Still, many architectures use this technique for specifying small integer constants.
- Direct addressing
- The address part of an instruction contains the operands full address in memory.
Like immediate addressing, direct addressing is restricted in its use: the instruction will always access exactly the same memory location. So while the value can change, the location cannot. Thus direct addressing can only be used to access global variables whose address is known at compile time. Nevertheless, many programs have global variables, so this form of addressing is widely used.
- Register addressing
- The address part of an instruction specifies a register rather than a memory location.
- Register indirect addressing
- The address
Enkeltsykelprosessoren
Kontrollsignaler for ulike instruksjonsformater i RISC-V arkitektur:
| Instruksjon | ALUSrc | MemtoReg | RegWrite | MemRead | MemRead | Branch | ALUop |
| R-format | 0 | 0 | 1 | 0 | 0 | 0 | 10 |
| ld/lw | 1 | 1 | 1 | 1 | 0 | 0 | 00 |
| sd/sw | 1 | X | 0 | 0 | 1 | 0 | 00 |
| beq | 0 | X | 0 | 0 | 0 | 1 | 01 |
add x2, x2, x3

- Instruksjonen er hentet, og PC er inkrementert. (PC+4)
- Registerene x2(rs1) og x3(rs2) er lest fra registerfila og kontrollenheten regner ut verdiene på kontrollsignalene.
- ALUen regner ut summen av verdiene i x2 og x3.
- Resultatet fra ALUen skrives til destinasjonsregisteret x1(rd) i registerfila.
ld x1, offset(x2)

- Instruksjonen er hentet, og PC er inkrementert. (PC+4)
- Registerene x2(rs1) er lest fra registerfila og kontrollenheten regner ut verdiene på kontrollsignalene.
- ALUen regner ut summen av verdiene i x2 og offset.
- Resultatet fra ALUen er minneadressen til ønsket verdi. Resultatet fra ALUen brukes for å indeksere dataen i minnet.
- Dataen på minneadressen skrives til destinasjonsregisteret x1(rd) i registerfila.
beq x1, x2, offset

- Instruksjonen er hentet, og PC er inkrementert. (PC+4)
- Registerene x1(rs1) og x1(rs2) er lest fra registerfila og kontrollenheten regner ut verdiene på kontrollsignalene.
- ALUen subtraherer erdiene i x1 og x2 (x2-x1) PC adderes med offset (PC+offset).
- Resultatet fra ALUen utgjør hvilken operasjon som utføres. Er Zero '1' betyr dette at x2-x1 = 0, og PC = PC+offsett. Hvis ikke x2-x1 = 0, så er PC inkrementert som vanlig (PC+4)
Hvorfor brukes ikke enkeltsykelsprosessoren i dag?
- for ueffektiv for moderne design/ytelsesbehov
- den lengste datastien ugjør klokkesykelen, dette gjør alle operasjoner "like trege"
- CPI(Cycles per Instruction) er 1, men sykelen er for lang
- er i strid med "make the common case fast"-prinsipp, man kan ikke forbedre common case når worst-case styrer klokkesykel/ytelse
Samlebåndsporsessoren
Pipelining: (samlebånd) en teknikk hvor man har flere overlappende instrukser som utføres.
Dette kan tenkes som analogien med en vaskedag. For en ikke-samlebåndsprosess, vasker man klærne slik:
- Legg i skitne klær i vaskemaskinen og skru den på
- Når vaskemaskinen er ferdig, legg de våte klærne i tørketrommelen
- Når tørketrommelen er klar, bretter man klærne
- Til sist legger man klærne på plass i skapet.
I en samlebåndsprosess, vil det være slik:
Så fort klærne er ferdige i vaskemaskinen fra første runde, legg i en ny farge med klær som må vaskes. Når den første runden med vask er tørr fra tørketrommelen, bretter du klærne mens du venter på runde to av vasken, som nå er i tørketrommelen. Når en vask er ferdig i vaskemaskinen, putter du bare inn en ny (gitt du har veldig mange skitne sokker i mange farger!) og hele prosessen vil bli kuttet ned i lengden, illustrert her:

Men obs: pipelining forbedrer vår totale gjennomstrømning (vasker vi får gjort i løpet av en tidsenhet) men ikke tiden det tar fra klær legges i vaskemaskinen til de er rene. Og før man har kommet seg gjennom første iterasjon av prosessen, vil man ikke ha gjennomført flere vasker enn ikke-samlebåndsprossen (selv om man har startet p tre andre vasker, telles de ikke som ferdige). Dette gjør at vi har en start-up tid før første "vask" er ferdig før man faktisk får effekten av en samlebåndsprosess.
I RISC-V er prossesen i en runde slik:
- Hent instruksjonen fra minnet. (Instruction Fetch, IF)
- Les registerene og dekod instruksjonen. (Instruction Decode, ID)
- Kjør operasjonen eller regn ut en adresse (gitt operasjon) (Execute, EX)
- Aksesser dataminnet (om nødvendig) (MEM)
- Skriv resultatet til registeret (om nødvendig) (Write Back, WB)
En samlebåndsprosess introduserer flere ting som kan gå galt:
Strukturfare («Structural hazard»): En enhet instruksjonen trenger er ikke tilgjengelig
En strukturfare kan beskrives som at hardwaren ikke støtter den kombinasjonen av instruksjoner vi ønsker å utføre, f.eks om i vaskemaskinscrenarioet er det en kombinert tørketrommel og vaskemaskin, og den iterative prosessen over er ugyldig.
Datafare («Data hazard»): Instruksjonen kan ikke utføres fordi data ikke er tilgjengelig - oppstår når en instruksjon trenger data produsert av en tidligere instruksjon(avhengighet) eller instruksjonene kjøres nært nok i samlebåndet at verdiene ikke kan hentes fra registerfila. Et eksemepel er
add x19, x0, x1
sub x2, x19, x3
hvor vi ikke kan bruke riktig verdi av x19.
Kontrollfare («Control hazard») (også kalt branch hazard): Vi vet ikke hvilken instruksjon som skal utføres
- oppstår ved betingelse forgreningsinstruksjoner (f.eks beq) fordi vi ikke vet hvilken instruksjon vi skal utføre før EX-steget.
Og vi løser disse problemene med:
Videresending (forwarding) (også kalt bypassing) - vi bytter ut verdien lest fra registerfila med den oppdaterte verdien
OBS! Les-bruk farer (Load-use hazards): videresendingen fungerer bare når verdien har blitt produsert når vi trenger den.
Prediksjon(prediction)
- Forgreningsprediksjon: det enkleste er å ta sjansen på at forgreningsinstruksjonen ikke gir et hopp. Hvis vi tar feil, må vi fjerne instruksjonene som ikke skal utføres (flush the pipeline), vi må sette kontrollsignaler til 0 for IF, ID og EX.
- Vi kan optimalisere med å gjøre beqi ID med videresending og faredeteksjon.
- Mer avansert prediksjon for forgreningsinstruksjoner (dynamisk forgreningsprediksjon): hvor hoppet forgreningsinstruksjonen sist? (Branch Target Buffer (BTB)), hva gjorde denne forgreningsinstruksjonen de siste n gangene vi har sett den? hva har de siste m forgreningsinstruskjonene gjort?
Faredeteksjon (Hazard detection): - faredeteksjonsenheten sjekker om vi skal lese fra minnet og skrive skrive til register som neste instruksjon leser. Da lager den et hull i samlebåndet (no operation) og holder samme verdi i PC og IF/ID
Hull (bubble): en stans i samlebåndet. Kontrollsignalene blir satt til 0.
Stans (stalling):
Unntak Unntak («Exception») - En ikke-forventet endring i kontrollflyt - Eksempel: En ikke-implementert instruksjon
Når et unntak oppstår i en RISC-V maskin, må vi: 1. Lagre adressen til instruksjonen som utføres i et forhåndsdefinert register (SEPC) 2. Lagre grunnen til unntaket i et foråndsdefinert register (SCAUSE) 3. Overføre kontroll til operativsystemet på en forhåndsdefinert adresse 4. Operativsystemet håndterer unntaket
For at operativsystemet skal gjøre jobben sin må tilstanden til maskinen være som om: - Alle instruksjoner før er ferdige - Ingen instruksjoner etter har kjørt - Dette kalles presise unntak («precise exceptions» (også kalt precise interrupt) og gjør det mulig å starte programmet på nytt fra der unntaket skjedde. Da har man unntak og avbrudd man vet er assosiert med gitt instruksjon som var årsaken til avbruddet. - Imprecise exception (også kalt imprecise interrupt) oppstår når man ikke kan assosiere insturksjonen med unntaket eller avbruddet som skjedde.
Avbrudd Avbrudd («Interrupt») - Et unntak der kilden er utenfor prosessoren (for eksempel I/O)
4.8 DATA Hazard: Forwarding versus Stalling
** Tatt fra gamle pensum: "Raw dependence / true dependence Når ett steg vil lese en verdi som ikke enda er ferdig skrevet at ett annet sted. RAW, Read After Write. Da må vi bare vente til verdien er klar før nye steg kan starte."
Utvidet

Gitt instruksjonene avbildet
sub x2, x1, x3 // Register z2 written by sub
and x12, x2, x5 // 1st operand(x2) depends on sub
or x13, x6, x2 // 2nd operand(x2) depends on sub
add x14, x2, x2 // 1st(x2) & 2nd(x2) depend on sub
sw x15, 100(x2) // Base (x2) depends on sub
Her er oppstartskostnadden først I1,I2,I3,I4,I5 Gitt oppstarts verdiene x1 = 15, x2 = 20, x3 = 5, x5 = 5, x6 = 7 blir følgende resultat:
sub x2, 15 - 5 = 10
bitwise AND av 20 og 5 (10100 og 00101) blir 4 (00100)
or x13 (7 or 20) = 21
add x14, 10, 10 = 20 (Her har I1 altså subtraksjons instruksjonen nådd WB og resultatet kan hentes i Decode)
sw x15, 100(10) = 110
Uten Faredeteksjon eller forwarding blir slike avhengigheter ikke løst automatisk og kjøres igjennom uten problem, men resultatet blir feil i forhold til hva ønsket output skal være.
Derfor innfører vi registere mellom hvert steg i samlebåndet samt faredeteksjons maskinvare. Dette er to tiltak brukt for å løse RAW - Read after Write farer (Ekte data-avhengigheter)
Forwarding-enheten sammenlikner destinasjonsregisterene til instruksjoner i EX/MEM- og MEM/WB-registrene med kilderegisterene til instruksjonen i EX. Dersom resultatet finnes i disse pipeline-registrene, kan det videresendes direkte til ALU-inngangen. Faredeteksjonsenheten oppdager load–use-farer der forwarding ikke er mulig, og setter inn en NOP for å stalle samlebåndet slik at korrekt verdi blir brukt.
Load-Use Farer
lw x5, 0(x4) //produserer verdien til x5 i MEM-fasen
add x6, x5, x7 //trenger verdien i EX-fasen (før MEM)
Load–use-farer oppstår når en instruksjon skal bruke et register som nettopp ble lastet fra minnet av en load-instruksjon. I en vanlig 5-stegs pipeline blir verdien fra en lw først tilgjengelig i slutten av MEM-steget, mens den neste instruksjonen trenger verdien allerede i EX-steget. Derfor er ikke forwardsing alene nok. Fare-deteksjonsenheten oppdager situasjonen og legger inn én stall (en boble) slik at load-instruksjonen kommer ett steg lengre i samlebåndet. Deretter kan videresendingsenheten sende verdien fra MEM-steget til EX-steget, og programmet fortsetter korrekt med minimal forsinkelse.
Kapittel 5 --- Large and Fast
5.1 Introduction
Det finnes to typer lokalitet ("nærhet); lokalitet i tid og lokalitet i rom. Prinsippet bak disse er at når man henter en intstruksjon, er det stor sannsynlighet for at man trenger en instruksjon som ligger nært i adresserommet(rom). Om man henter en instruksjon, er det også stor sannsynlighet for at man skal bruke denne instruksen igjen snart (tid). Oppstår f.eks. i løkker.

I en datamaskin er det er hierarki av minne. Dette representeres grafisk som en trekant, for å beskrive forholdet mellom størrelse, pris, fart og lokalitet. I en minnestruktur som dette er det raskeste minnet (i toppen av trekanten) det raskeste minnet, men også det dyreste per størrelsesenhet og det minste i størrelse. Hvordan dette fungerer er at prosessoren vil be om data fra det øverste nivået av minne. Om den ønskede dataen finnes i det gitte minnet, kalles dette en hit, mens om denne dataen ikke finnes i det gitte minnet, kalles dette en miss. I dette tilfellet må man hoppe et steg ned i hierarkiet av minne for å igjen se om den gitte ønskede dataen eksisterer der. Raten av hit versus miss er hit-raten, gitt i en brøkdel mellom 0 og 1. Miss-raten er 1-hit rate.
Minneblokk (block (or line)): den minste enheten informasjon som kan være tilstede (eller ikke tilstede) i en cache.
Om man får en miss, bruker man miss penalty for å beskrive tiden det tar å overføre en blokk fra et lavere nivå av minne til det øverste nivået i minne så det er tilgjengelig for prosessoren. Hit time er tiden det tar for å aksessere et nivå av minne og avgjøre om det var en hit eller miss.
5.2 Memory Technologies
Hurtigbuffer | Cache
Hurtigbufferet holder informasjon på samme måte som hovedminnet. Det er mye mindre plass til informasjon i hurtigbufferet, men det går også mye raskere å hente informasjon fra det til prosessoren.
Ord | Word
En benevnelse som benyttes om den naturlige datastørrelsen i en gitt datamaskin. Et ord er ganske enkelt en samling av bit som håndteres samtidig av maskinen. Antallet bit i et ord, kalt ordstørrelsen, er et viktig kjennetegn ved enhver datamaskinarkitektur. Vanlige ordstørrelser i dagens PC-er er 32 og 64 bit. De fleste registrene i en datamaskin har størrelsen til et ord.
Locality of reference | Lokalitetsprinsippet
Når man ber om ett ord fra hovedminnet, antar man at man kommer til å trenge det ordet flere ganger, og at man også kommer til å trenge noen av naboene. Derfor blir ordet sammen med noen av naboene kopiert til hurtigbufferet.
Gjennomsnittlig minneaksesstid | mean memory access time
Lokalitetsprinsippet betyr at for å bruke ett ord k ganger trenger man ett tregt kall til hovedminnet og deretter k - 1 raske kall til hurtigbufferet. Ved hjelp av k kan man regne seg fram til et gjennomsnitt på hvor raskt prosessoren kan jobbe.
mean access time = c + (1 - h) * m
cer cache access time, tiden det tar programmet å hente informasjon fra hurtigbuffer.mer memory access time, tiden det tar å hente informasjon fra hovedminnet.h = (k - 1)/ker trefforholdstall (hit ratio), andelen av referanser som kan hentes fra hurtigbufferet i stedet for hovedminnet.(1 - h)er dermed miss ratio, andelen som må hentes fra hovedminnet.
SRAM
- minne-arrays
- fast data access time, ulik read/write tid
- ingen behov for å refreshe, nær sykeltid (prosessor)
- seks-åtte transsistorer
- lav effekt
DRAM
- en transistor, ladning av kondensator
- refresh av cellen, kan lese og skrive tilbake
- buffer rows
- Double Data Rate (DDR) Synchronus DRAM
- Dual Inline Memory Modules (DIMM) (4-16 DRAM)
Flash Memory
- Eletrically Erasable Programmable Read-Only Memory (EEPROM)
- skriving kan "slite ut" bits (wear-leveling, spread out writes)
Disk Memory
- "platter" (rund disk) som roterer rundt en aksel (spindle) på ca 54000 til 15 000 RPM. Hver platter har et magnetisk belegg som kan brukes til å lagre informasjon.
- arm med read/write head (elekromagnetisk kveil).
- sirklene er tracks, og hver track er bygget opp av sectors. hver sector er den minste enheten man kan lese/skrive til/fra en disk.
- rotational latency: tiden det tar for rett sektor å rotere under read/write head. gjenommsnittlig 1/2 rotation time.
- transfer time: tiden det tar å overføre en blokk med bits. sammenhengdende blocks kan være på uike tracks.
5.3 The Basics of Caches
- direct-mapped cache: a cache structure where each memory location is matched to exactly one location in the cache
- tag: a field in a table used for memory hierarchy that contains the address information required to identify whether the associated block in the hierarchy corresponds to a requested word.
- valid bit: a field in the tables of a memory hierarchy that that the block contains valid data
- caches are used for prediction recently referenced words replace less recently referenced words.
- miss rate goes up if block size is too large relative to cache.
- early restart → processor doesn't wait for all data, just first word (after miss)
- requested word first/critical word first organizes by address slightly faster (after miss)
- cache miss: a request for data from the cache that cannot be filled, not present data. the address of the instruction that generates a cache miss is PC-4. if we have a miss we stall the processor
- write-through: a scheme in which writes always update both cache and the next lower- level of the memory hierary, ensuring consistent data
- write buffer: a queue that holds data while the data is waiting to be written to memory.
- write-back: updates values only to the block in the cache, modifies lower level memory when the cache block is replaced
- split cache: a scheme in which two independent caches operate in parallell, one w/ data and one w/ instructions
- fully associative cache: structure which a block can be placed in any location of the cache
- set-associative cache: fixed number of locations (at least 2) Where each blockcan be placed in cache
- when a miss occurs in a direct-mapped cache, the requested block can only go in one position → replace.
- in an associative cache, we have a choice of which to replace.
- in a fully assosian cache, all caches are candidates for replacement.
- set-associative → select between sets.
- Least Recently Used (LRU): a replacement scheme in Whichthe block replaced isthe one that has been unused the longest time.
- multilevel cache: multiple levels
Chapter 6 --- Parallel Processors from Client to Cloud
6.1 Introduction
The operating system can be regarded as an interpreter for certain architectural features not found at the ISA level. Chief among these are virtual memory, virtual I/O instructions, and facilities for parallel processing.
Virtual memory
Virtual memory is an architectural feature whose purpose is to allow programs to use more address space than the machine has physical memory, or to provide a consistent and flexible mechanism for memory protection and sharing. It can be implemented as pure paging, pure segmentation, or a combination of the two. In pure paging, the address space is broken up into equal-sized virtual pages. Some of these are mapped onto physical page frames. Others are not mapped. A reference to a mapped page is translated by the MMU into the correct physical address. A reference to an unmapped page causes a page fault. Both the Core i7 and the OMAP4430 ARM CPU have MMUs that support virtual memory and paging.
Performance
Here the longest step ∆y limits clockfrequency, and the maximum clockfrequencey is 1/25ns = 40 Mhz.
Array processor
Mange identiske prosessorer som synkront gjør de samme operasjonene på datasett med lik struktur, men ulikt innhold. Dette lar maskinen utføre store mengder arbeid parallellt, nyttig f.eks. for å analysere vitenskapelig data.
Vector processor
Lignende idé som array processor. Dataene som skal jobbes med puttes i en vektor og sendes samlet gjennom en prosessor spesialdesignet for å håndtere slike vektorer.
Multiprocessor(flerprosessering): en datamaskin med minst to prosessorer. En motsetning til uniprocessor, med bare en prosessor.
For å kunne kjøre noe på en flerprosessor, er det ønskelig å implementere måter å parallellisere oppgaver på. Task-level paralellism (også kalt process-level parallelism) er en metode for å utnytte flere prosessorer ved å kjøre uavhenige programmer på de samtidig. I motsetning er parallell processing program en metode for å kjøre det samme programmet fordelt på ulike prosessorer samtidig.
Clusters, datamaskiner som er sammenkoblet i et lokalt nettverk og fungerer som en stor multiprosessor, kan blant annet brukes til å kjøre ytelseskrevende programmer og applikasjoner som søkemotorer, e-postservere og databaser.
En multicore microprosessor er mikroprosessorer som inneholder flere prosessorer(kalt kjerner "cores") i en integrert krets. De fleste mikroprosessorer i dag er multicore micorprocesssors. De fleste er Shared Memory Processors (SMPs), grunnet de deler et fysisk adresserom.
Denne teknologien fører til at om man ønsker å skrive rask kode, så skriver man parallell kode (samtidig, "concurrent"), ikke sekvensiell kode. (Dette kan være litt vanskelig å få helt greip på om man ikke har forhold til det, noen eksempler og videre lesing finnes her).
6.2 The Difficulty of Creating Parallel Processing Programs
Mye kode er skrevet sekvensiellt, og det er dermed en utfordring å få disse til å utnytte ytelsen av en multicore processor godt nok. Samtidig er det også vanskelig å skrive parallell programvare som kjører bra på et sekvensielt system.
En utfordring med å skrive parallell kode for et paralellt system er at man må kunne fordele oppgavene i et program jevnt utover prosessorene. Om arbeidsfordelingen ikke er god nok, vil man ikke ytnytte ytelsen godt nok, da deler av kjernene vil ha mange oppgaver å gjennomføre mens andre vil ha perioder på "standby".
Et annet problem er at kjernene kan bruke så mye tid på å "snakke" med hverandre til å kunne gjnnomføre de gitte oppgavene som trengs å gjennomføres effektivt nok. Utfordringene omhandler nettopp "scheduling", å dele oppgavene i parallele deler og å balansere arbeidsmengden mellom kjernene. Dess flere kokker(kjerner) dess mer søl, og vi må holde styr på hele systemet.
Almdahl's Lov minner oss også på at hver minste del av systemet må være parallelisert for å kunne utnytte flere kjerner.
Det er ulike teknikker for å øke ytelsen på et system. Begrepet strong scaling brukes om systemer hvor man måler programmets speed-up mens man oppnår en speed-up mens man beholder den opprinnelige størrelsen på oppgaven. Weak scaling derimot, er når oppgavestørrelsen øker proposjonalt med økende tall prosessorer. Hvis man har en størrelse av en oppgave, gitt i M, med P antall prosessorer, vil minnet for hver prosessor ved stong scaling være ca. M/P, mens for et system med weak scaling vil minnet per prosessor være nærmere M.
6.3 SISD, MIMD, SIMD, SPMD, and Vector
Vi kan kategoriere ulike typer parallell hardware basert på mengden instruksjonstrømmer og datastrømmer.
SISD (Single Instruction stream, Single Data stream: en uniprosessor.
MIMD (Multiple Instruction stream, Multiple Data streams: en multiprocessor.
Programmerere skriver gjerne et program som kjører på alle kjernene til en MIMD (multiprocessor) datamaskin, og bruker betingende utrykk for når ulike prosessorer skal kjøre ulike seksjoner av kode. Denne silen kalles SPMD.
SPMD (Single Program, Multiple Data streams): den vansligste MIMD(multiprocessor)-programmeringmodellen, hvor et program kjører på ulike kjerner.
MISD (Multiple Instruction stream, Single Data stream) kan eventuellt komme i form av en "stream prosessor), som tar inn beregninger på en datastrøm og gjør noe med denne dataen. Et mer poluært alternativ er SIMD (Single Instruction stream, Multiple Data streams), som kjører på vektorer av data. En enkelt SIMD-instruksjon kan for eksempel legge sammen 64 tall ved å sende 64 datastrømmer til 64 ALU-er og regne ut disse summene i en klokkesykel. Den samme instruksjoner er utført på mange datastrømmer i en SIMD-datamaskin.
En sekvensiell applikasjon kan bli kompilert til å kjøre på seriell hardware som en SISD eller på en parallell hardware som en SIMD. SIMD trenger bare en kopi av koden som kjøres, mens MIMDs kan kreve en kopi i hver prosessor eller ha flere instruksjonscaches. SIMD funker best med array i for-løkker. Siden SIMD krever en stor grad av identisk strukturert data for å håndtere parallellisering på en god måte, og her kommer data-level parallelism inn. Dette er teknikken med å gjøre samme handling på uavhengig data.
SIMD er svakest i case og switch-uttrykk, hvor hver kjøring vil utføre ulike operasjoner på dataen, avhengi av daten. I et slikt tilfelle med n caser vil yelsen til en SIMD maskin ligge på 1/ntedel av sin høyeste ytelse.
En annen måte å utnytte tankemåten av SIMD på er å bruke en vektorarkitektur, hvor i stedet for å ha 64 ALUer som utfører 64 beregninger samtidig, fokuserer denne teknikken på samle dataelementer fra minnet, sette de i rekkefølge i et større sett av registrer, og utføre operasjoner på disse sekvensielt for å så skrive resultatene tilbake til minnet(pipelined execution units). Man kan da ha 32 vektorregistre, hver med 64 64-bit elementer.
Vector versus Scalar
Vector instructions have several important properties compared to conventional instruction set architectures, which are called scalar architectures in this context:
- A single vector instruction specifies a great deal of work—it is equivalent to executing an entire loop. The instruction fetch and decode bandwidth needed is dramatically reduced.
- By using a vector instruction, the compiler or programmer indicates that the computation of each result in the vector is independent of the computation of other results in the same vector, so hardware does not have to check for data hazards within a vector instruction.
- Vector architectures and compilers have a reputation for making it much easier than when using MIMD multiprocessors to write efficient applications when they contain data-level parallelism. Hardware need only check for data hazards between two vector instructions once per vector operand, not once for every element within the vectors. Reduced checking can save energy as well as time.
- Vector instructions that access memory have a known access pattern. If the vector’s elements are all adjacent, then fetching the vector from a set of heavily interleaved memory banks works very well. Thus, the cost of the latency to main memory is seen only once for the entire vector, rather than once for each word of the vector.
- Because a complete loop is replaced by a vector instruction whose behavior is predetermined, control hazards that would normally arise from the loop branch are nonexistent. The savings in instruction bandwidth and hazard checking plus the efficient use of memory bandwidth give vector architectures advantages in power and energy versus scalar architectures. For these reasons, vector operations can be made faster t han a sequence of scalar operations on the same number of data items, and designers are motivated to include vector units if the application domain can often use them.
Vector lane: En eller flere vektor-enheter og en del av vektor-registerfila. Flere "lanes" ufører vektoroperasjoner samtidig.
Raw dependence / true dependence
Når ett steg vil lese en verdi som ikke enda er ferdig skrevet at ett annet sted. RAW, Read After Write. Da må vi bare vente til verdien er klar før nye steg kan starte.
Parallellisme
Parallellisme kommer i to generelle former, nemlig parallellisme på instruksjonsnivå og parallellisme på prosessornivå.
Prosessornivåparallellisme
Systemer med flere prosessorer er stadig vanligere. Parallelle datamaskiner inkluderer array-prosessorer, der den samme operasjonen utføres på flere datasett samtidig, multiprosessorer, der flere CPUer deler felles minne, og multidatamaskiner, der flere datamaskiner har sine egne minner, men kommuniserer ved meldingsoverføring.
Instruksjonsnivåparallellisme
Instruksjonsnivåparallellisme (ILP) er et mål på hvor mange av instruksjonene i et dataprogram som kan utføres samtidig.

Superscalar Architectures
A superscalar processor is a CPU that implements a form instruction-level parallelism within a single processor. Can execute more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to different execution units on the processor. It therefore allows for more throughput (the number of instructions that can be executed in a unit of time) than would otherwise be possible at a given clock rate. Each execution unit is not a separate processor (or a core if the processor is a multi-core processor), but an execution resource within a single CPU such as an arithmetic logic unit.
Superscalability can be implemented without affecting the ISA, but it requires extra logic for handling instruction transfers.
6.4 Hardware Multithreading
6.6 Introduction to Graphics
6.7 Clusters, Warehouse Scale Computers, and Other Message-Passing Multiprocessors
6.8 Introduction to Multiprocessor Network Topologies
Appendix
A.2 Gates, Truth Tables, and Logic Equations
- asserted signal: '1' deasserted signal: 'O'
- combinatorial logic: no memory, output dependent on input
- sequential logic: memory. previous inputs + inputs
Boolean algebra:
Another approach is to express the logic function with logic equations. This is done with the use of Boolean algebra (named after Boole, a 19th-century mathematician). In Boolean algebra, all the variables have the values 0 or 1 and, in typical formulations, there are three operators:
The OR operator is written as +, as in A+B. The result of an OR operator is 1 if either of the variables is 1. The OR operation is also called a logical sum, since its result is 1 if either operand is 1.
The AND operator is written as · , as in A · B. The result of an AND operator is 1 only if both inputs are 1. The AND operator is also called logical product, since its result is 1 only if both operands are 1.
The unary operator NOT is written as Ā. The result of a NOT operator is 1 only if the input is 0. Applying the operator NOT to a logical value results in an inversion or negation of the value (i.e., if the input is 0 the output is 1, and vice versa). There are several laws of Boolean algebra that are helpful in manipulating logic equations.
- Identity law: A+0=A and A·1=A
- Zero and One laws: A+1=1 and A·0=0
- Inverse laws: A + Ā = 1 and A · Ā = 0
- Commutative laws: A+B=B+A and A·B=B·A
- Associative laws: A+(B+C)=(A+B)+C and A·(B·C)=(A·B)·C
- Distributive laws: A·(B+C)=(A·B)+(A·C) and A+(B·C)=(A+B)·(A+C)
A.3 Combinational Logic
- decoder: logic block with n-bit input and 2n output, one output for each input
- PLA (Programmable Logic Array): implement logic functions as a sum of products
- ROMs (read only memory) (programmable ROMs, erasable PROMS) -erasure process ultraviolet light (slow)
- bus: a collection of data lines that are treated together as a single logical signal, or a collection of lines
Adderere
| A (inn) | B (inn) | Sum (ut) | Mente (ut) |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
Når man adderer to bits sammen har man de fire mulighetene som tabellen viser. Kretskomponenten som adderer to bits kaller man en halvadderer (half adder).
For å addere et ord som består av flere bits, må man ha en ripple-carry adder. Det kan man lage ved å lenke sammen flere fulladderere.
Fulladdereren består av en halvadderer som adderer de to bitene, og en annen halvadderer som adderer resultatet fra den første halvaddereren med carry-biten fra addisjonen av de forrige bitene. Summen herfra lagres som resultat-bit, og hvis en eller begge av addisjonene i dette steget produserte en carry-bit sendes en cassy-bit videre til neste fulladderer.
A.7 Clocks
- clocking metodology: determine valid data relative to clock
A.8 Memory Elements: Flip-Flops, Latches, and Registers
- register file: a data element that consists of a set of registers that can be read and written to by supplying a register number to be accessed
- flip-flop: a memory element for which the output is equal to the value of the stored state inside, changed only on clock edge
- latch: output equal to data stored, state changed when inputs and clock is asseterted ('1')
- D flip-flop: one data input that stores input when the clock edge occurs
- setup time: minimum time input to a memory device must be valid before the clock edge
- hold time: minimum time the output must be valid after the clock edge
Tips til øving på eksamen
- les oppsummeringen av kapitlene i boken. Finn ut hva du er kjent med, og hva du trenger mer øving i.
- test om du kan svare på læringsmålene gitt til faget.
- test om du kan dataflyten til en samlebåndsprosessor og en enkeltsykelprosessor.
- bruk RISC-V reference card og gjør deg kjent med dette.