TDT4160: Computers and Digital Design
Preface
This compendium tries to explain the essence of the course. The information provided is largely based on the course book "Structured Computer Organization" and the lecture slides. Please note that this compendium is written by students, so please be critical to what you read.
Anyone is allowed to edit this compendium, so feel free to suggest improvements.
Chapter 1
Stored-program computer
Data and program are both stored in electronic memory. The computer keeps track of what is data and what are instructions. The machine fetches instuctions, and data is transfered between memory and ALU.
Von Neumann and Harvard architecture
A computer with a von Neumann architecture stores data and instructions in the same memory, while a computer with a Harvard architecture has separate memories for storing programs and data. Both are stored-program designs.
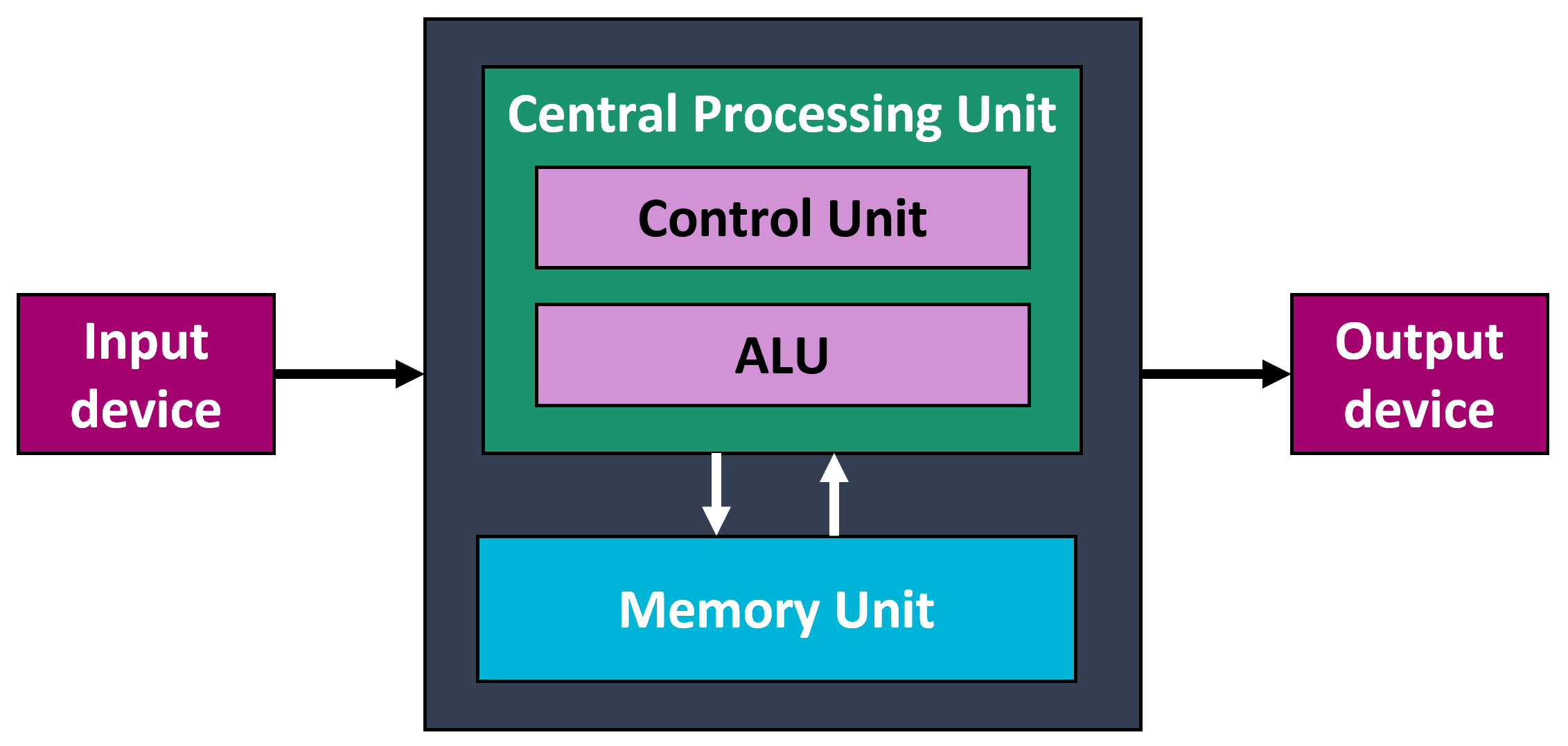
Von Neumann Architecture
A theoretical design for a stored-program computer that serves as the basis for almost all modern computers. The von Neumann arichitecture describes a machine with five basic parts: the memory, the arithmetic logic unit, the control unit, and the input and output equipment.
- Von Neumann architecture
- Computer systems are built up from three types of components: processors, memories, and I/O devices.
- CPU (Central Processing Unit)
- The part of the computer that fetches instructions one at a time from a memory, decodes them, and executes them.
- Memory
- The part of the computer where programs and data are stored.
- I/O (input/output) devices
- The parts of the computer used to transfer information from and to the outside world.
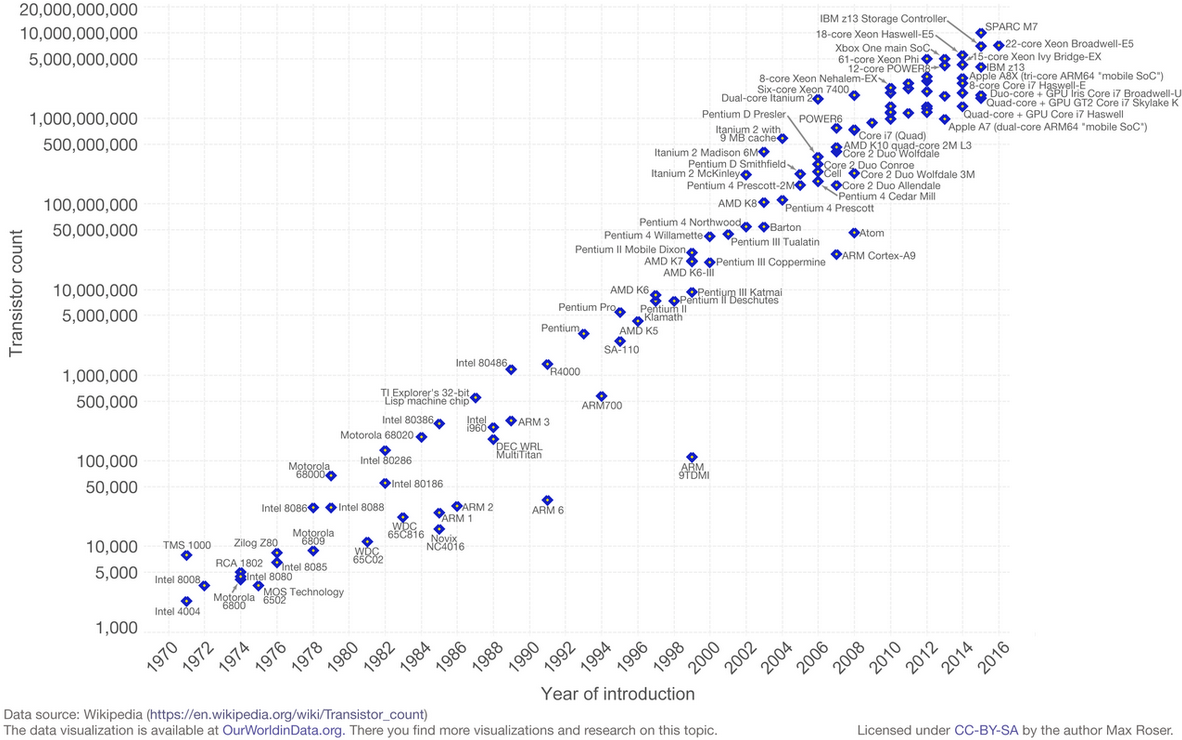
Moore's law
Moore's law is the observation that the number of transistors in a dense integrated circuit doubles about every two years. The observation is named after Gordon Moore, the co-founder of Fairchild Semiconductor and Intel His paper of 1965 described a doubling every year in the number of components per integrated circuit, and projected this rate of growth would continue for at least another decade. In 1975, looking forward to the next decade, he revised the forecast to doubling every two years. The period is often quoted as 18 months because of a prediction by Intel executive David House (being a combination of the effect of more transistors and the transistors being faster)
Chapter 2
Computer systems are built up from three types of components: processors, memories, and I/O devices.
Processors
The task of a processor is to fetch instructions one at a time from a memory, decode them, and execute them. The fetch-decode-execute cycle can always be described as an algorithm and, in fact, is sometimes carried out by a software interpreter running at a lower level. To gain speed, many computers now have one or more pipelines or have a superscalar design with multiple functional units that operate in parallel. A pipeline allows an instruction to be broken into steps and the steps for different instructions executed at the same time. Multiple functional units is another way to gain parallelism without affecting the instruction set or architecture visible to the programmer or compiler.
The CPU (Central Processing Unit) is the "brain of the computer". Its function is to execute programs stored in the main memory by fetching their instructions, examining them, and then executing them one after another. The components are connected by a bus, which is a collection of parallel wires for transmitting address, data, and control signals. Buses can be external to the CPU, connecting it to memory and I/O devices, but also internal to the CPU.
The CPU is composed of several distinct parts.
- The control unit
- Component responsible for fetching instructions from main memory and determining their type.
- The arithmetic logic unit
- Component that performs operations such as addition and Boolean AND. Needed to carry out the instructions.
The CPU also contains a small, high-speed memory used to store temporary results and certain control information. This memory is made up of several registers, each having a certain size and function.
- Program counter (PC)
- Points to the next instruction to be fetched for execution.
- Instruction Register (IR)
- Holds the instruction currently being executed.
- Memory Address Register (MAR)
- Holds the address of the memory location currently being accessed by the processor.
- Memory Buffer/Data Register (MDR)
- Holds the data being transferred to or from the memory location currently being accessed.
Most computers have numerous other registers as well, some of them general purpose as well as some for specific purposes.
Memory
The memory is the part of the computer where programs and data are stored. Memories can be categorized as primary or secondary.
Primary memory
The primary memory is used to hold the program currently being executed. Its access time is short (a few tens of nanoseconds at most) and is independent of the address being accessed. Caches reduce this access time even more. They are needed because processor speeds are much greater than memory speeds, meaning that having to wait for memory accesses all the time greatly slows down processor execution. Some memories are equipped with error-correcting codes to enhance reliability.
Secondary memory
Secondary memories, in contrast, have access times that are much longer (milliseconds or more) and is often dependent on the location of the data being read or written. Tapes, flash memory, magnetic disks, and optical disks are the most common secondary memories. Magnetic disks come in many varieties, including IDE disks, SCSI disks, and RAIDS. Optical disks include CD-ROMs, CD-Rs, DVDs, and Blu-rays.
Static and dynamic RAM
Static RAM: Faster, large memory cell (area), uses a lot of power, does not need to be refreshed, simple interface.
Dynamic RAM: Slower, small memory cell (area), uses less power, needs to be refreshed, complicated interface.
Cache
Small, fast memory. The most heavily used memory words are kept in the cache. When the CPU needs a word, it first looks in the cache. Only if the word is not there does it go to main memory. If a substantial fraction of the words is in the cache, the average access time can be greatly reduced.
Latency hiding
By reducing average access time, one can "hide" latency.
Memory Hierarchy
Different types of memories can be arranged in a hierarchy with fastest, smallest, and most expensive at the top, and slowest, largest, and least expensive at the bottom.

Processor memory gap
Processor performance has improved a lot faster than memory access time.


I/O devices
I/O devices are used to transfer information into and out of the computer. They are connected to the processor and memory by one or more buses. Examples are terminals, mice, game controllers, printers, and modems. Most I/O devices use the ASCII character code, although Unicode is also used and UTF-8, one of the Unicode-standards, is gaining acceptance as the computer industry becomes more Web-centric and globalised.
Chapter 3
Gates
Computers are constructed from integrated circuit chips containing tiny switching elements called gates. The most common gates are AND, OR, NAND, NOR, and NOT. Simple circuits can be built up by directly combining individual gates, although everything can be built using NOR or NAND gates.
Complex circuits
More complex circuits are multiplexers, demultiplexers, encoders, decoders, shifters, and ALUs. Arbitrary Boolean functions can be programmed using a FPGA. If many boolean functions are needed, FPGAs are often more efficient. The laws of Boolean algebra can be used to transform circuits from one form to another. In many cases more economical circuits can be produced this way.
Adders
Computer arithmetic is done by adders. A single-bit full adder can be constructed from two half adders. An adder for a multibit word can be built by connecting multiple full adders in such a way as to allow the carry out of each one feed into its left-hand neighbour.

A logical schematic for a full adder.
Memory
The components of (static) memories are latches and flip-flops, each of which can store on bit of information. These can be combined linearly into latches and flip-flops for memories with any word size desired. Memories are available as RAM, ROM, PROM, EPROM, EEPROM, and flash. Static RAMs need not be refreshed; they keep their stored values as long as the power remains on. Dynamic RAMs, on the other hand , must be refreshed periodically to compensate for leakage from the capacitors on the chip.
Bus
The components of a computer system are connected by buses. Many, but not all, of the pins on a typical CPU chip directly drive on bus line. The bus lines can be divided into address, data, and control lines. Synchronous buses are driven by a master clock. Asynchronous buses use full handshaking to synchronize the slave to the master.
Buses enables data and control signals to move around the CPU and memory. There are a number of different buses.
A bus is a communication channel through which data can be moved.
There are many buses in a computer; one example is the universal serial bus (USB), which can transfer data between the computer and external devices.
Control bus: Carries control signals around the CPU and memory indicating whether the operation is a read or a write and ensuring that the operation happens at the right time.
Address bus: Carries memory addresses for memory locations to be read from or written to.
Data bus: Carries data between the CPU and memory. For a write operation the CPU will put the data on the data bus to be sent to memory. For a read operation, the data will be taken from a memory block and sent to the CPU. Carries data from CPU to memory and vice versa.
Example CPU Chips
The core i7 is an example of a modern CPU. Modern systems using it have a memory bus, a PCIe bus, and a USB bus. The PCIe interconnect is the dominant way to connect the internal parts of a computer at high speeds. The ARM is also a modern high end CPU but is intended for embedded systems and mobile devices where low power consumption is important. The Atmel ATmega168 is an example of a low-priced chip good for small, inexpensive appliances and many other price-sensitive applications.
Interfacing
Switches, lights, printers, and many other I/O devices can be interfaced to computers using parallel I/O interfaces. These chips can be configured to be part of the I/O space or the memory space, as needed. They can be fully decoded or partially decoded depending on the application.
Chapter 4: The Microarchitecture Level
The goal of this chapter is to explain microarchitecture. On this level, processors are illustrated in block diagrams. The goal is to use processor microarchitecture to understand what a units a processor is made of and how those units are connected. In this course the IJVM is used as an example.
Synchronized busstranfer:
The signal is syncronized with a clock
ASynchronized busstranfer:
The signal is syncronized with a handshake
Components in CPU
Control Unit
Think about it as the "captain in the army". It recieves its orders from RAM in the form of an instruction and then breaks that instruction down into specific commands for the other components.
Arithmetic Logic Unit
One of the most important units under the command of the control unit is the Arithmetic Logic Unit (ALU). The ALU is what performs all the mathmatical operations inside the CPU such as addition, subtraction, and even comparisons. The ALU has to inputs (often labeled input A and B), and an output.
Normal process: Control unit recieves an instruction from RAM, then tell the ALU what to do (what operation and what input to use). The ALU then often output an answer. For some instructions like (comparisons) the ALU doesn't need to computer an output, it will simply give a flag back to the contol unit.
Registers
The eight wires coming out of an ALU run to what is called a register. A register is a very simple component whos only job is to store a number temporarily. Registers acts just like RAM, only that they are inside the CPU making them faster and more useful for storing a number temporaily while instructions are bing processes. When the ALU sends the output to a register, the value wont actually be saved until the control unit turns on the register set wire.
The CPU bus
The CPU bus connects the components inside the CPU to eachother, it makes it possible to move numbers from one components to another (like moving data from one register to another).
The Data Path
The heart of every computer is the data path. It contains some registers, one, two or three buses, and one or more functional units such as ALUs and shifters. The main execution loop consists of fetching some operands from the registers and sending them over the buses to the ALU and other functional unit for execution. The results are then stored back in the registers.
The data path can be controlled by a sequencer that fetches microinstructions form a control store. Each microinstruction contains bits that control the data path for one cycle. The bits specify which operands to select, which operation to perform, and what to do with the results. In addition, eahc microinstruction specifies its successor, typically explicitly by containing its address. Some microinstructions modify this base address by ORing bits into the address before it is used.
The IJVM Machine
The IJVM machine is a stack machine with 1-byte opcodes that push words onto the stack, pop words from the stack, and combine (e.g., add) words on the stack. A microprogrammed implementation was given for the Mic-1 microarchitecture. By adding an instruction fetch unit to preload the bytes in the instruction stream, many references to the program counter could be eliminated and the machine greatly speeded up.
Microarchitecture Level Designs.
There are many ways to design the microarchitecture level. Many trade-offs exist, including two-bus versus three-bus designs, encoded versus decodeed microinstruction fields, presence or absence of prefetching, shallow or deep pipelines and much more. The Mic-1 is a simple, software-controlled machine with sequential execution and no parallelism. In contrast, the Mic-4 is a highly parallel microarchitecture with a seven-stage pipeline.
Improving performance
Performance can be improved in a variety of ways. Cache memory is a major one. Direct-mapped cashes and set-associative caches are commonly used to speed up memory refreshes. Branch prediction, both static and dynamic, is important, as are out-of-order execution, and speculative execution.
Examples of the microarchitecture level
Our three example machines, the Core i7, OMAP4430, and ATmega168, all have microarchitectures not visible to the ISA assemble-language programmers. The Core i7 has a complex scheme for converting the ISA instructions into micro-operations, caching them, and feeding them into a superscalar RISC core for out-of-order execution, register renaming, and ever other trick in the book to get the last possible drop of speed out of the hardware. The OMAP4430 has a deep pipeline, but is further relatively simple, with in-order issure, in-order execution, and in-order retirement. The ATmega168 is very simple, with a straightforward single main bus to which a handful of registers and one ALU are attached.
Chapter 5: The Instruction Set Architecture
The instruction set is a set of instructions that a computer is able to understand and execute. The specifics of the instructions may vary from computer to computer, but in the following section the most common ones are listed.
The purpose of instructions sets
When writing a computer program, you don't want to write it using logic (boolean algebra) because it would be very inconvenient.
How a program executes
Programs are written by people (programmers) usually in a high level language such as java, c, python and so on. The code written in high level language needs to be compiled into assemble code which is language at a lower level. The assembly code will be put into an OS loader which loads the program into memory.
The instruction set architecture level is what most people think of as "machine language" although on CISC machines it is generally built on a lower layer of microcode. At this level the machine has a byte- or word-oriented memory consisting of some number of megabytes or gigabyes, and instructions such as MOVE, ADD, and BEQ.
Most modern computers have memory that is organized as a sequence of bytes, with 4 or 8 bytes grouped together into words. There are normally also between 8 and 32 registers present, each one containing one word. On some machines (e.g., Core i7), refrences to words in memory do not have to be aligned on natural boundaries in memory, while on others (e.g. OMAP4430, ARM), they must be. But even if words do not have to be aligned, performance is better if they are.
Instructions generally have one, two, or three operands, which are addressed using immediate, direct, register, indexed, or other addressing modes. Some machines have a large number of complex addressing modes. In many cases, compilers are unable to use them in an effective way, so they are unused. Instructions are generally available for moving data, dyadic and monadic operations, including arithmetic and Boolean operations, branches, procedure calls, and loops, and sometimes for I/O. Typical instructions move a word form memory to a register (or vice versa), add, subtratc, multiply, or divide two registers or a register and a memory words, or compare two items in registers or memory. It is not unusual for a computer to have well over 200 instructions in its repertoire. CISC machines often have many more.
Control flow at level 2 is achieved using a variety of primitives, including branching, procedure calls, coroutine calls, traps, and interrupts. Branches are used to terminate one instruction sequence and begin a new one at a (possibly distant) location in memory. Procedures are used as an abstration mechanism, to allow a part of the program to be isolated as a unit and called from multiple places. Abstraction using procedures or the equivalent, it would be impossible to write any modern software. Coroutines allow two threads of control to work simultaneously. Traps are used to signal exceptional situations, such as arithmetic overflow. Interrupts allow I/O to take place in parallel with the main computation, with the CPU getting a signal as soon as the I/O has been completed.
The Towers of Hanoi is a fun little porblem with a nice recursive solution that we examined. Iterative solutions to it have been found, but they are far more complicated and elegant than the recursive one we studied.
Last, teh IA-64 architecture uses the EPIC model of computing to make it easy for programs to exploit parallelism. It uses instruction groups, predication, and speculative LOADs to gain speed. All in all, it may represent a significant advance over the Core i7, but it puts much of the burden of parallelization on the compiler. Still, doing work at compile time is always better than doing it at run time
Common instructions
- LOAD
- Move data from RAM to registers.
- STORE
- Move data from registers to RAM.
- MOVE
- Copy data among registers.
- ADD
- Add two numbers together.
- COMPARE
- Compare one number with another.
- JUMP IF CONDITION
- Jump if condition to another address in RAM
- JUMP
- Jump to another address in RAM.
- OUT
- Output to a device.
- IN
- Input from a device such as a keyboard.
Instruction Formats
An instuction consists of an opcode, usually alongwith additional information suchg as where operands come from and where results go to. The general subject of specifying where the operands are (i.e, their addresses) is called addressing. There can be several possible formats for level 2 instructions. An instruction always has an opcode to tell what the instruction does. There can be zero, one, two, or three addresses present. On some machines, all instructions have the same length; on others there may be many different lengths. Instructions may be shorter than, the same length as, or longer than the word length. Having all the instructions be the same length is simmpler and makes decoding erasier but often wastes space, since all instructions then have to be as long as the longest one. Other trade-offs are also possible.
Addressing
Most instructions have operands, so some way is needed to specify where they are. This is called addressing.
- Immediate addressing
- The address part of an instruction actually contains the operand itself rather than an address or other information describing where the operand is.
Immediate addressing has the virtue of not requiring an extra memory reference ot fetch the operand. It has the disadvantage that only a constant can be supplied this way. Also, the numberof values is limited by the size of the field. Still, amny architecture use this technique for specifiying small integer constants.
- Direct addressing
- The address part of an instruction contains the operands full address in memory.
Like immediate addressing, direct addressing is restricted in its use: the instruction will always access exactly the same memory location. So while the value can change, thel ocation cannot. Thus direct addressing can only be used to access global variables whose address is known at compile time. Nevertheless, many programs have global variables,so this mode is widely used.
- Register addressing
- The address part of an instruction specifies a register rather than a memory location.
- Regoster indirect addressing
- The address
Chapter 6
The operating system can be regarded as an interpreter for certain architectural features not found at the ISA level. Chief among these are virtual memory, virtual I/O instructions, and facilities for parallel processing.
Virtual memory
Virtual memory is an architectural feature whose purpose is to allow programs to use more address space than the machine has physical memory, or to provide a consistent and flexible mechanism for memory protection and sharing. It can be implemented as pure paging, pure segmentation, or a combination of the two. In pure paging, the address space is broken up into equal-sized virtual pages. Some of these are mapped onto physical page frames. Others are not mapped. A reference to a mapped page is translated by the MMU into the correct physical address. A reference to an unmapped page causes a page fault. Both the Core i7 and the OMAP4430 ARM CPU have MMUs that support virtual memory and paging.
Performance
Here the longest step ∆y limits clockfrequency, and the maximum clockfrequencey is 1/25ns = 40 Mhz.
Prosessorer
Prosessesorer kan referer til flere forskjellige styre- og behandlingsenheter i elektroniske maskiner. I all hovedsak prater man om prosessorer i sammenheng med CPU (Central Prosessing Unit) og mikroprosessorer. Slike enheter utgjør kjernen av en moderne datamaskin, som står for all behandling av digitale og analoge signaler som mottas og sendes ut igjen til datamaskinen.
CPU
En Central Processing Unit (CPU) er "hjernen" til moderne datamaskiner. Hovedfunksjonen til en CPU er å utføre instruksjoner som er gitt av et dataprogram. Disse dataprogrammene er lagret i hovedlageret til CPUen. Dette gjøres ved at instruksjoner hentes inn til hovedprosessoren hvor den inspiserer og så sekvensielt kjører hver instruks. Hver av disse "instruksjonsettene" ligger i en buss.
Buss
En buss er en samling med parallelle ledninger som overfører adresser, rå data og kontrollsignaler. En buss kan eksistere som både en intern og ekstern komponent til en CPU.
Organisering i CPU
En CPU består av 3 hoveddeler, en aritmetisk logisk enhet (ALU), en rekke registere og en kontrollenhet. prosessoren består også av et hovedminne som inneholder midlertidige resultater fra utregninger gjort i hovedprosessoren.
ALU
En Aritmetisk logisk enhet er en enhet som gjør utregninger på de inputene i fra et dataregister. Disse registerene ligger sammen med ALUen i det som heter datapath. Operasjoner foregår ved at en instruksjon forteller ALUen at den skal gjøre operasjoner på to registere som ligger i data path. Disse to registeren hentes inn som input hvor det gjøres en operasjon på de, før resultatet blir enten lagret tilbake til registeret, eller at det lagres på minnet til maskinen. ALU kan gjøre grunnleggende aritmetiske operasjoner som addisjon og subtraksjon.
Array processor
Mange identiske prosessorer som synkront gjør de samme operasjonene på datasett med lik struktur og ulikt innhold. Dette lar maskinen utføre store mengder arbeid parallellt, nyttig f.eks. for å analysere vitenskapelig data.
Vector processor
Lignende idé som array processor. Dataene som skal jobbes med puttes i en vektor og sendes samlet gjennom en prosessor spesialdesignet for å håndtere slike vektorer.
Hurtigbuffer | Cache
Hurtigbufferet holder informasjon på samme måte som hovedminnet. Det er mye mindre plass til informasjon i hurtigbufferet, men det går også mye raskere å hente informasjon fra det til prosessoren.
Ord | Word
En benevnelse som benyttes om den naturlige datastørrelsen i en gitt datamaskin. Et ord er ganske enkelt en samling av bit som håndteres samtidig av maskinen. Antallet bit i et ord, kalt ordstørrelsen, er et viktig kjennetegn ved enhver datamaskinarkitektur. Vanlige ordstørrelser i dagens PC-er er 32 og 64 bit. De fleste registrene i en datamaskin har størrelsen til et ord.
Locality of reference | Lokalitetsprinsippet
Når man ber om ett ord fra hovedminnet, antar man at man kommer til å trenge det ordet flere ganger, og at man også kommer til å trenge noen av naboene. Derfor blir ordet sammen med noen av naboene kopiert til hurtigbufferet.
Gjennomsnittlig minneaksesstid | mean memory access time
Lokalitetsprinsippet betyr at for å bruke ett ord k ganger trenger man ett tregt kall til hovedminnet og deretter k - 1 raske kall til hurtigbufferet. Ved hjelp av k kan man regne seg fram til et gjennomsnitt på hvor raskt prosessoren kan jobbe.
mean access time = c + (1 - h) * m
cer cache access time, tiden det tar programmet å hente informasjon fra hurtigbuffer.mer memory access time, tiden det tar å hente informasjon fra hovedminnet.h = (k - 1)/ker trefforholdstall (hit ratio), andelen av referanser som kan hentes fra hurtigbufferet i stedet for hovedminnet.(1 - h)er dermed miss ratio, andelen som må hentes fra hovedminnet.
Logiske kretser
Adderere
| A (inn) | B (inn) | Sum (ut) | Mente (ut) |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
Når man adderer to bits sammen har man de fire mulighetene som tabellen viser. Kretskomponenten som adderer to bits kaller man en halvadderer (half adder).
For å addere et ord som består av flere bits, må man ha en ripple-carry adder. Det kan man lage ved å lenke sammen flere fulladderere.
Fulladdereren består av en halvadderer som adderer de to bitene, og en annen halvadderer som adderer resultatet fra den første halvaddereren med carry-biten fra addisjonen av de forrige bitene. Summen herfra lagres som resultat-bit, og hvis en eller begge av addisjonene i dette steget produserte en carry-bit sendes en cassy-bit videre til neste fulladderer.
Raw dependence / true dependence
Når ett steg vil lese en verdi som ikke enda er ferdig skrevet at ett annet sted. RAW, Read After Write. Da må vi bare vente til verdien er klar før nye steg kan starte.
Chapter 8
Parallelism
Parallelism comes in two general forms, namely, instruction-level parallelism and processor-level parallelism.
Processor level parallelism
Systems with multiple processors are increasingly common. Parallel computers include array processors, on which the same operation is performed on multiple data sets at the same time, multiprocessors, in which multiple CPUs share common memory, and multicomputers, in which multiple computers each have their own memories but communicate by message passing.
Instruction level parallelism
Instruction-level parallelism (ILP) is a measure of how many of the instructions in a computer program can be executed simultaneously.

Superscalar Architectures
A superscalar processor is a CPU that implements a form instruction-level parallelism within a single processor. Can execute more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to different execution units on the processor. It therefore allows for more throughput (the number of instructions that can be executed in a unit of time) than would otherwise be possible at a given clock rate. Each execution unit is not a separate processor (or a core if the processor is a multi-core processor), but an execution resource within a single CPU such as an arithmetic logic unit.
Superscalability can be implemented without affecting the ISA, but it requires extra logic for handling instruction transfers.