TDT4140: Software development
This covers most of the curriculum for 2014V. I am now finished with my work here, and what isn't here, won't be here unless you add it. Enjoy! – Vages
Chapter 1: Introduction
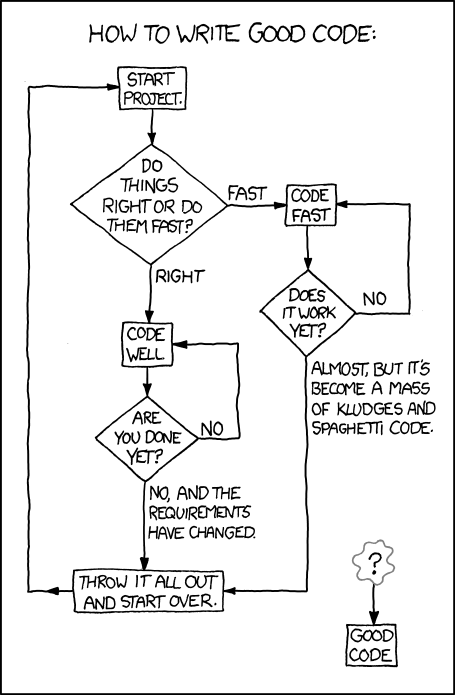 "You can either hang out in the Android Loop or the HURD loop." (xkcd 844: Good Code, CC-BY-NC 2.5 Randall Munroe)
"You can either hang out in the Android Loop or the HURD loop." (xkcd 844: Good Code, CC-BY-NC 2.5 Randall Munroe)
What is software engineering?
- Software are computer programs and their associated documentation. They may be developed for a specific customer (customized products) or the general market (generic products).
- Software engineering is an engineering discipline concerned with all aspects of software production, from system specification to maintenance. This is opposed to computer science (which is more concerned with theories and fundamentals). It usually consists of four activities:
- Software specification: What will it do?
- Software development: Making it do it.
- Software validation: Does it do it?
- Software evolution: Modify the software after release to reflect new requirements.
- System engineering is more concerned with the whole. This includes aspects such as hardware and process engineering. Software engineering is a part of this process.
Why is it called engineering?
Software engineering is an engineering practice because it, like all other engineering disciplines, applies theories selectively to discover new solutions to problems within given financial constraints (hopefully). Good software engineering takes extra effort, but saves a lot of money because the software is more maintainable.
The process is concerned not only with the technical aspects, but also the surrounding factors, such as project management, choosing a good team and the right development methods.
Roughly 60% of software development costs are related to development and 40% go to testing.
The general attributes of software
Good software should strive to meet these requirements. It is not possible to meet all requirements to their fullest (e.g: higher security might mean less efficiency).
| Maintainability | Software should be written so that bugs can be fixed and it can evolve. |
| Dependability and security | The software should not cause damage when a faliure occurs, and malicious users should not be able to access or damage the system |
| Efficiency | Do not waste system resources. Strive for high responsiveness, short processing time etc. |
| Acceptability | The software should be understandable for users and compatible with systems they use |
What affects software engineering?
A lot of software is bad (and not in the Michael Jackson way). This is due to a lot of factors, such as:
- Increasing demand: The world wants software, but sometimes faster than what anyone could possibly deliver.
- Low expectations: Developers aren't used to using good methods and develop poor software. Users are used to mediocre results.
- Bad development methods: Factors such as customer contracts (or simply incompetence or fear of novelty) prevents teams from choosing the appropriate development methods. Certain development methods, such as the waterfall method, is old; it has a lot of important uses, but agile methods might in many cases be better.
Software engineering ethics
You should always follow these ethical guidelines.
| Confidentiality | Treat your customer's information as secret. Often you might sign a confidentiality agreement, but not necessarily. Regardless of that, don't be a dick. |
| Competence | Don't misrepresent your level of competence. It will catch up with you. |
| Intellectual property rights | Respect the copyright of other programmers and creative individuals. |
| Computer misuse | Misuse covers everything from playing games during working hours to spreading malware from customer computers. |
Chapter 2: Software processes
This chapter describes software processes. Software processes vary, but always includes these four activities:
- Software specification: What will it do?
- Software development: Making it do it.
- Software validation: Does it do it?
- Software evolution: Modifying the software after release to reflect new requirements.
As well, the descriptions might include some of the following:
- Products: The outcomes of process activites (models etc.).
- Roles: Different responsibilities that must be covered.
- Pre- and post-conditions: Something that must be true either before or after an activity starts, such as "Requirements approved by customer".
Software process models
The book looks at three models.
The waterfall model
The first published method of software development. Has five stages.
- Requirements analysis and definition: Services, constraints and goals are designed.
- System and software design: Establishes the architecture.
- Implementation and unit testing: The coding.
- Integration and system testing: Individual units are integrated and tested as a complete system.
- Operation and maintenance: Deployment of the product and updating it according to customer needs and discovered errors. Normally the longest phase.
Pro/contra:
- Advantages: Consistent with processes in other engineering areas, and might thus be very palatable to customers.
- Disadvantages: Bad decisions early in the process might grow and become very hard (read: expensive) to correct.
Incremental development
This model is based on developing an initial implementation, exposing this to user feedback and evolving it through several versions.
Incremental development says requirements must be defined beforehand, but agile methods only defines very minimalistic requirements beforehand and work out the more advanced on the way.
Pro/contra:
- Advantages:
- The cost of accomodating changing needs and correcting errors is reduced.
- It is easier to get customer feedback, because the customer can actually see the product.
- More rapid delivery; the customer can use an early version of the product very early.
- Disadvantages: This is not very well suited for complex, long-lifetime systems or systems where safety is critical.
Reuse-oriented software engineering
Most projects today reuses components. The phases of reuse-oriented software engineering are:
- Requirements specification: See The waterfall model
- Component analysis: A search is made for components that can implement the specifications.
- Requirements modification: Components may not match requirements exactly, and modifications can be made to the requirements.
- System design with reuse: Design the framework as well as new components for requirements that you couldn't find a match for.
- Development and integration: implement the newly designed components. Integrate the system.
- System validation: See The waterfall model
Pro/contra:
- Advantages: May be very cheap, depending on how much software is reused, how easy it is to integrate and how much it costs.
- Disadvantages: You lose some control over the software.
Process activities
Software specification
Understanding and defining what services are required from the system; identify constraints on the system’s operation and development. The aim is to produce an agreed requirements document. Usually this is provided at two levels: A higher level for customers and a level with more detail for the developers.
Four main activities
- Feasibility study: May the needs be satisfied using current software and hardware technologies. Is it cost-effective and feasible within the budget? This part should be quick and cheap.
- Requirements elicitation and analysis: Derive system requirements through observation of existing systems.
- Requirements specification: Translate the information gathered into a specification document. User requirements describe the demands of the users. System requirements is a more detailed description of the functionality.
- Requirements validation: Checks for realism, consistency, and completeness. Errors must be corrected.
Software design and implementation
Converting the system specification into an executable system.
Four activities that may be involved in the design process for information systems:
- Architectural design: Identify the overall structure of the system, the principal components, their relationships and how they are distributed.
- Interface design: Define the interfaces between system components – this must be unambiguous. This allows for concurrent development.
- Component design: Designing the individual component. May be a statement of expected functionality, with the implementation left to the programmer, or a list of changes that have to be made to a reusable component or a detailed design model (which might even be used to automatically generate an implementation).
- Database design: Making the database. Reuse an existing one or make a new.
Software validation
Showing that the software conforms to its specification and meets the expectations of the customer.
The stages of the testing process are:
- Development testing: The developers test the components independently. Often done automatically.
- System testing: After integration. Finding unanticipated errors in interactions between the components. Show that the system meets functional and non-functional requirements.
- Acceptance testing: (Alpha testing) The final stage before the system is ready for operational usage. The system is tested with real data, instead of simulated test data.
Software evolution
Keeping the software up-to-date and bug free. Development and maintenance are becoming more and more alike, because of increasing reuse of code in development and increasing demand for new features (not just error-correction) in the maintenance phase.
Coping with change
Change is inevitable. And it is expensive, because of rework (replacing already finished, but now irrelevant, parts). There are two approaches to reducing these costs:
- Change avoidance: The development includes activities that can anticipate possible changes before significant rework is required. Prototyping is an example of this.
- Change tolerance: The process is designed to accommodate changes at relatively low cost – normally involving incremental development.
Prototyping
An initial version of a software system that is used to demonstrate concepts.
A problem with prototyping with users, is that it may not necessarily be used in the same way as the final system:
- The tester may not be a typical user.
- The training time might be insufficient.
- If certain parts of it is slow, the user may avoid them. Functionality that might be useful, is thus not tested.
Incremental delivery
Incremental development means delivering the software in incremental versions with small improvements every time. It starts with the customer specifying their requirements and sorting them by order of priority. Small increments of the software is then planned. Each increment is then delivered to the customer, who may test it in practice.
Advantages:
- Customers can use the early increments as prototypes. This helps in refining later system requirements.
- Customers can begin to use the system before it’s completely finished.
- It is relatively easy to incorporate changes into the system.
- The most important parts get more testing (because they are in use from the start).
Disadvantages:
- It can be hard to identify common parts that are needed by all increments because requirements are not defined in detail until the element is to be implemented.
- When replacing an old system, it is hard to get new users to try out a new system with less features.
- Many organizations are unwilling to use incremental delivery methods, because they want to specify what they get beforehand.
Boehm's spiral model

Is a try at combining change tolerance with change avoidance. Has an outward spiral that spins through for sectors – each representing one stage in an increment – and the innermost circles being more concerned with system feasibility and so on.
The four sectors:
- Objective setting: The objects for that phase of the project are defined. Constraints are identified and a management plan is drawn up. Risks are identified and alternative strategies may be planned.
- Risk assessment and reduction: Detailed analysis for every identified risk. Steps to reduce risks.
- Development and validation: The development model for the system is chosen based on the previous stages.
- Planning: The project is reviewed and a decision made whether to continue with a further loop of the spiral.
The Rational Unified process
A modern process model that has been derived from the work on UML and the Unified Software Development process. A hybrid model.
The RUP models from the business perspective rather than the technical. There are four phases:
- Inception: Establish a business case for the system. Identify all external entities (people and systems) that will interact with the system and define these interactions. Use this information to assess the contribution to that the system makes to the business. If this is minor, the project might be cancelled after this phase.
- Elaboration: Develop an understanding of the problem domain, establish an architectural framework for the system, develop the project plan, and identify key project risks. This should result in a requirements model for the system (perhaps UML cases), an architectural description, and a development plan for the software.
- Construction: System design, programming, and testing. On completion of the phase, one should have a working software system and associated documentation that is ready for delivery to users.
- Transition: Moving the system from the development community to the user community and making it work in its real environment. On completion, one should have a fully working software system with complete documentation.
It also has some static workflows. These are activities that are separated from the phases – you have to do them when you see fit. See the book for a list.
Six fundamental best practices are recommended:
- Develop software iteratively.
- Manage requirements: State them explicitly.
- Use component-based architectures.
- Visually model new software: Using UML models.
- Verify software quality.
- Control changes to software.
Chapter 3: Agile software development

The fundamental characteristics of rapid software development approaches:
- Specification, design and implementation are interleaved. The user requirements document defines only the most important characteristics.
- The system is developed in a series of versions.
- User interfaces are often developed in an interactive development environment that allows for quick redesign.
Customers are often very involved in the process.
Agile methods
Agile methods were a response to huge overheads involved in plan-driven development. The basic principles are outlined in the Agile manifesto (very short; required reading).
The principles of agile methods:
| Customer involvement | The customer helps decide what is to be implemented when and evaluates iterations of the system. |
| Incremental delivery | The product is delivered in small increments. |
| Embrace change | Expect the system requirements to change. |
| Maintain simplicity | Keep the process and software simple (refactor code). |
Agile methods have been very succesful for some types of system development:
- Product development where a software company is developing a small or medium-sized product for sale.
- Custom system development within an organization. This makes the customer commit to the development process.
Agile methods are not well suited for critical and complex systems. It also requires all members to have a relatively high skill level.
Things that may come in the way of agile development: - Customers are not able or willing to participate. - Team members aren't comfortable for intense involvement. - Prioritizing changes can be difficult. - Maintaining simplicity requires extra work. - It is hard to gain a contract for agile development, because customers are skeptical; they like (or are required by superiors) to know what they buy up front.
Extreme Programming
Extreme Programming (XP) got its name because it pushed known agile practices to its extreme.
In XP, requirements are expressed as scenarios, called user stories, which are written on story cards. You can read more about this in agile planning.
During the planning game, questions that require further exploration are uncovered. This may require a spike, an increment in which no programming is done. Usually, this involves prototyping, documentation or designing the system architecture.
In a normal increment, the scenarios are divided into tasks and are taken on by programmers, who work in pairs. Tests are always developed before code, and code must execute all tests successfully to be implemented into the system.
Some advantages of pair programming:
- People feel collective ownership of and responsibility for the code.
- Code is reviewed and refactored while it written.
- For inexperienced programmers, it has been shown to be just as effective as programming alone. (Productivity drops a little bit when experienced programmers program in pairs).
Even if productivity seems to drop, the benefits of sharing the knowledge between programmers might be worth a few lines of code less per hour.
Agile project management
Scrum isn't as concerned with programming practices as XP and focuses more on management – the two are often combined.
Scrum has three phases:
- Outline planning: Establish general objectives for the project and design the software architecture.
- Sprint cycles: Each cycle develops an increment of the system.
- A sprint has a fixed length (2 to 4 weeks).
- The starting point is the product backlog, a list of work to be done. During the assesment phase, the product backlog is reviewed and priorities and risks are assigned to each task.
- The selection phase lets the whole team select the features and functionality that will be developed during the current sprint.
- When they have reached agreement, the team organizes themselves to develop the software. They hold short daily meetings to review progress and reprioritize.
- Ath the end of each sprint, the work is completed, reviewed, and presented to stakeholders. A new cycle begins afterwards.
- Project closure: Completing the required documentation and assessing the lessons learned from the project.
There is no project manager in Scrum, but there is a Scrum master who arranges the daily meetings, tracks the backlog, records decisions, measures progress, and communicates with customers and management.
Scaling agile methods
Some effort has been made to adapt agile methods to larger systems. However, this has not been very succesful. More complex systems require more analysis before the project starts. However, once some design has been made, it is possible to divide the work to be done into smaller parts that can be developed by smaller teams.
Chapter 4: Requirements engineering
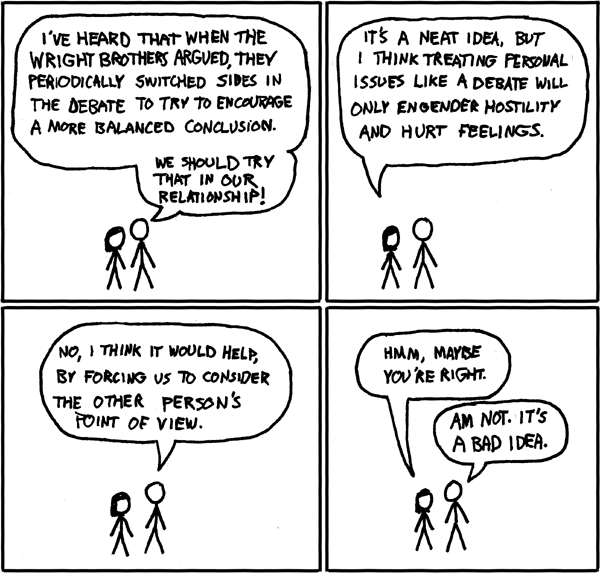 "I'm not sure if this is actually true" (xkcd 106: The Wright Brothers, CC-BY-NC 2.5 Randall Munroe)
"I'm not sure if this is actually true" (xkcd 106: The Wright Brothers, CC-BY-NC 2.5 Randall Munroe)
The requirements are descriptions of what the system should do. Requirements engineering is the process of finding out, analyzing, documenting and checking requirements.
The term is not used consistently in the industry. We will divide requirements into two types:
- User requirements: Statements in natural language and diagrams of what services the system should provide and its constraints.
- System requirements: More detailed descriptions of the system's functions, services, and operational constraints. This should be defined in the system requirements document.
Functional and non-functional requirements.
| Functional requirements | Statements of services that the system should provide, how it reacts to certain inputs and behaves in certain situations. |
| Non-functional requirements | Constraints on the services or functions, such as response time, constraints on the development process, and standards. Often very critical: Imagine that your word processor took ten seconds from each keystroke to displaying it on screen. |
Customers often specify non-functional requirements in vague terms such as "The system should be easy to use". This should be replaced by certain metrics, such as "A user should be able to use the system's functionality within 4 hours of training". Speed requirements can be assessed through metrics such as bytes processed per seconds. (This can be a problem for customers, because they don't understand what computing terms mean.)
The hierarchy of non-functional requirements
There is a huge hierarchy of non-functional requirements:

The three main groups are:
- Product requirements: Specify or constrain the behavior of the software.
- Organizational requirements: Derived from policies and procedures in customers' and developers' organizations.
- External requirements: Regulatory requirements, legislative requirements and ethical requirements.
The software requirements document
This document is an official statement of what the system developers should implement. It should include both user requirements and detailed system requirements.
The level of detail depends on how critical the system is (more critical
Requirements specification
The process of writing down the user and system requirements document. They should be clear, unambigiuous, easy to understand, complete and consistent. Albeit these goals seem simple in theory, in practice it is hard to achieve them all at the same time in.
Some ways to specify:
| Natural language | The most used, because it is easy to understand, but potentially ambiguous. Try to adhere to a standard structure for each sentence. |
| Structured natural language | Each requirement is put in a specific form. |
| Design description languages | Languages similar to programming languages, but with more abstract features. Rarely used. |
| Graphical notations | Graphical models supplemented by text annotations. UML is an example. |
| Mathematical specifications | Based on mathematical concepts such as final state machines. Unambiguous, but customers don't understand it. |
Requirements engineering processes
Read the book …
Requirements elicitation and analysis
This is done after a feasibility system: You work with customers and end-users to find out how the software should be constructed.
Stages:
- Discovery: Interacting with stakeholders (the people who the system will affect) to discover their requirements.
- Classification and organization: Groups requirements into coherent clusters.
- Prioritization and negotiation: Prioritizing requirements and finding and resolving conflicts through negotiation with the customer.
- Specification: Requirements are documented and input into the next round of the spiral. (Documents might be produced).
This process might be difficult because:
- Stakeholders don't know what they want or can't formulate it.
- They speak from their own perspective and take certain things for granted. (Even though breathing is important for you as a human, you rarely describe this as a part of your day, do you?)
- Different stakeholders have conflicting requirements.
- Political factors influence stakeholders. A manager might want a system that increases his influence in the workplace.
- The environment of the organization might change.
Some activities you might do:
| Discovery | Gathering information about the required and existing system. Distilling the user and system requirements about this information. |
| Interviewing | Have both structured questions and open discussions with stakeholders. It is hard to know what people really want. They might for instance tell you that they always follow work procedures, but in reality they cut corners (due to time restrictions etc.) |
| Scenarios | Creating a description of a scenario of system interaction that users can relate to. Tells about the state of the system before interaction, what happens, and what might go wrong. |
| Use cases | Identify the actors involved in an interaction, viewed in a diagram. |
| Etnography | Studying people in their working environment to find out how they really act and what they really need. |
 Use case diagram (CC-BY-SA 3.0 Kishorekumar 62)
Use case diagram (CC-BY-SA 3.0 Kishorekumar 62)
Requirements validation
The process of checking that the requirements actually define the system that the customer wants.
- Validity checks: A user might think that a system needs some specific functions. Further thought might bring to light that this is insufficient or can be replaced.
- Consistency checks: Checking that requirements aren't in conflict.
- Completeness checks: The document should contain all functions and constraints.
- Realism checks: Is this possible with current technology, budget and schedule?
- Verifiability: Are the requirements quantifiable (measurable)?
Techniques you might use to test this:
- Requirements review: The requirements document is analyzed systematically by a team of reviewers.
- Prototyping: An executable model is demonstrated to end users and customers.
- Test-case generation: Making tests for requirements often reveals problems.
Requirements management
Requirements for large systems are always changing. The problems you solve are often wicked problems, which are problems that cannot be completely defined. Changes might appear because business and technology changes or users are unsatisfied. Thus you need to keep track of requirements and how they change.
This requires:
- Requirements identification: Every requirement must have a unique identifier, so that it can be traced and cross-referenced.
- A change management process: Set of activites that assess the impact and cost of changes.
- Traceability policies: The relationships among requirements and between requirements and system design.
- Tool support: What tools to use to keep track of the requirements. They should be in a secure, managed, data store that is accessible to everyone involved in requirements engineering.
When a change is proposed, this process is followed:
- Problem analysis and change specification: You start with a problem or change proposal. This stage checks whether it is valid (i.e. worth caring about and possible to implement). If so, proceed.
- Change analysis and cost: The effect of the proposed change is analazed and the cost is analyzed. If worth it, proceed.
- Change implementation: Necessary parts of requirements and the system design are modified.
Chapter 5: System modeling
System modeling is the process of developing abstract models of the system. Each of the models present a different view or perspective of the system. This is usually done in UML (Unified Modeling Language), but it can also be done with mathematical models (these are not in the curriculum).
Models are useful for both discussing a proposed system and visualizing an an existing system.
The most essential UML models are:
- Activity diagrams: Show activities involved in a process. (Wikipedia)
- Use case diagrams: Show interactions between a system and its enviroment. (Wikipedia)
- Sequence diagrams: Show interactions between actors and the system, as well as between system components. (Wikipedia)
- Class diagrams: Show object classes and the associations between them. (Wikipedia)
- State diagrams: Show how the system reacts to internal and external events. (Wikipedia).
Context models
Early in the process of specification, you should decide the boundaries of the system: What should it do? Is this covered by an existing solution? Can functionality be left to manual processes or other software? A context model shows the relation between the system and other related systems.
An activity diagram will be used to show the flow of a system process, quite like a flowchart.
Interaction models
These models model the interactions between users and the system. This might be either use case models or sequence diagrams. You can read more about them in the introduction.
Structural models
Structural models display the organization of the system in terms of the components that make up the system, as well as their relationships. Static models show the system design; dynamic models show the organization of the system while it is executing (its different threads). These two kinds of diagrams might differ greatly for a system.
Class diagrams is a structural model that is used when developing an object oriented system. A box represents an object, and lines with different arrowheads show how they're associated. Class diagrams also helps the process of generalization: Classes that share common attributes, might have these attributes combined in a superclass that they all inherit from. When an object is composed of (i.e. contains) objects of another class, it is called aggregation.
Behavioral models
Behavioral models model the dynamic behavior of the system as it is executing. They show what happens (or, to be frank, what is supposed to happen) when a system respons to a stimulus from its environment. There are two types of stimuli:
- Data: Some data that the system should process arrives. The data from the tax processing has arrived.
- Events: Some event triggers the system. Events might have associated data. Your nuclear reactor has a meltdown. Along with it, you get a nice count of the radiation level measured in becquerels.
Data-driven modeling
The first method of showing the processing of input data was the data-flow diagrams, but these have been deprecated in newer versions of UML and replaced with activity diagrams (see above). The flow of data can also be shown in a sequence diagram.
Event-driven modeling
This is based on the assumption that a system has a finite number of states. Stimuli can cause a transition from one state to another. This is represented with a state diagram.
The problem with this is that the number of states can be large; imagine the state diagram for your operating system, for instance. One way to help tidy up the diagrams, is to combine several states into a superstate (which you elaborate in its own diagram).
Model-driven engineering
This is an approach to software engineering where models rather than programs are the principal outputs of the development process. The programs are generated automatically from the models.
- Pros:
- Allows engineers to think about the system without concern for low-level details. This reduces the likelihood of errors and speeds up the development process.
- Implementations for different platforms can be generated automatically.
- Cons:
- Abstractions you make for the model aren't always the right abstractions when implementing.
- The case for platform-independence isn't very relevant, because the main problem in developing a new system that might be ported to another platform largely lies in other parts of the implementation: Requirements engineering, security, and dependability.
You should make at least these three kinds of models in model-driven engineering:
- Computation independent model: Models the important domain abstractions used in the system. You might create more than one, each modeling its own part of the system.
- Platform independent model: Models the operation of the system without reference to its implementation.
- Platform specific models: Transformations of the platform independent model with a separate model for each platform. There might be several level, such as one level that is middleware-specific, but database independent. When a certain database system is chosen, you go deeper.
It is possible to make such models by adding information to UML diagrams to use them in model-driven engineering. This is done by an extension to UML 2, which is called xUML; this makes the semantics clear and contains a very high-level programming language to specify functions.
Chapter 6: Architectural design
Architectural design is understanding how a system should be organized and designing the structure of the system. This an important process in both agile and plan-driven development, because refactoring the architecture is mega-expensive. The non-functional requirements are the more dependent on the system architecture than the functional requirements.
Ideally, system components should be easy to separate. But as always, it is not as simple in practice, because boundaries aren't intuitive.
An architectural model is often used to:
- Facilitate discussion about the system design: Because of the lack of detail, it is useful for communications with stakeholders.
- Document an architecture that has been designed: The model is a complete system model that shows the different components, their interfaces, and their connections. This makes for easier evolution.
There are two levels of abstractions for architectural models:
- Architecture in the small: Concerned with the architecture of an individual program; organizing its components. Will be discussed in this chapter.
- Architecture in the large: Concerned with the architecture of complex enterprise systems that include other systems, programs and program components. Will be discussed in chapter 18 and chapter 19.
The advantages of designing a good system architecture:
- Stakeholder communication: Customers understand the system better.
- System analysis: The process makes the feasibility of the system clearer.
- Large-scale reuse: It is easier to see the potential for software reuse.
The architecture is often visualized in a block diagram (Wikipedia). The boxes within boxes are sub-components, and arrows represent data or control signals going from one component to another.
Architectural design
Architectural design is a creative process where you design a system organization that will satisfy the functional and non-functional requirements of a system.
Questions you should ask yourself:
- Is there a generic application architecture that can act as a template for the system?
- How will the system be distributed across a number of cores or processors? (When designing a system for PCs or embedded systems, you usually use only one core.)
- What architectural patterns or styles might be used? (Client-server, layered, etc.) Should be based on:
- Performance: If performance is critical, localize critical operations within a small number of components. Consider run-time system organizations that allow the system to be replicated and executed on different processors.
- Security: A layered structure is best if security is essential.
- Safety: If this is critical, all safety related operations should be located in a single or small number of components, thus reducing costs.
- Availability: If the system needs to always be available, there should be redundant components, so that parts can be replaced without the system shutting down.
- Maintainability: If this is critical, the architecture should have fine-grained, self-contained components that may readily be changed.
- What will be the fundamental approach used to structure the system?
- How will the structural components in the system be decomposed into subcomponents?
- What strategy will be used to control the operation of the components in the system?
- What architectural organization is best for delivering the non-functional requirements of the system?
- How will the architectural design be evaluated?
- How should the architecture of the system be documented?
Architectural views
Krutchen suggests that in addition to the block diagram, you make four additional views – this is called the 4+1 model. His four suggestions:
- Logical view: Shows the key abstractions in the system as objects or classes. It should be possible to relate the system requirements to entities in this view.
- Process view: Shows how the system is composed of interacting processes at runtime.
- Development view: Shows how the software is broken down into components that can be implemented by a single developer or development team.
- Physical view: SHows the system hardware and how software components are distributed across the processors in the system. (Useful for systems engineers.)
This is rarely done in agile methods. The book's author comments that for plan-driven development, the problem is that they're often made, but rarely used …
Architectural patterns
An architectural pattern is a stylized, abstract description of good practice, such as the Model-View-Controller pattern (MVC) (Wikipedia).
Layered architecture
Separation and independence are fundamental to architectural design, because they allow changes to be localized. MVC is an example of a layered architecture.
The basic idea and aim of a layered architecture is that each layer communicates (only) with the layers directly above or below. This means that if you have to replace the component or redesign the interfaces, you only have to worry about its adjacent components.
There is no clear-cut definition of what a layer should contain. It is always possible to make more or fewer.
Repository architecture
A repository architecture is organized around a shared database or reporitory. The integrated development environment you use to program (such as Eclipse) is an example of this: All the components make use of the same data, but none of them are interacting on top of one another. A repository architecture needs a standard way for the components to interact with it – this is called a schema. This architecture is only a static structure, and does not show the run-time organization.
Client-server architecture
A very common run-time organization. A system that follows this pattern is organized as a set of services and associated servers, with clients that access and use the services. You're probably using an architecture of this kind right now: Wikipendium is delivered to you by a server, and you are a client, accessing it through your web browser.
Major components:
- Servers that offer services to other components.
- Clients that call on the services offered by the servers.
- A network that allows the clients to access these servers.
Pipe and filter architecture.
A pipe and filter pattern is a run-time organization of a system where functional transformations process their inputs and produce outputs. Imagine a traditional assembly line, and you've pretty much got it down. This may seem a bit dull, but when doing batch processing, such as checking taxes or processing customer orders, you don't need to make things harder than they are. As you might imagine, it is not very useful for interactive applications.
Chapter 7: Design and implementation
(Never mind the comic: The content (as well as cake and grief counseling) will be available at the end.)
"This is why you shouldn't interrupt a programmer"

(CC-BY-NC-ND 2.5, Jason Heeris)
The design and implementation is the stage at which an executable software system is developed. For some simple systems, all activities are merged into this phase. In larger, complex, and/or critical systems, this is just one stage in the process.
Design is the process of finding a solution. Keep it somewhere, such as a UML diagram (or your head). Implementation is the process of turning that idea into computer code.
Object-oriented design using the UML
Object-oriented design involves designing object classes and the relationships between them. The advantage of an object oriented design is that it is very easy to change.
Prerequisites:
- Understand and define the context of and the external interactions with the system.
- Design the system architecture.
- Identify the principal objects in the system.
- Develop design models.
- Specify interfaces.
These things are done interleaved.
System context and interactions
Understanding the context and interactions is essential. Two different models:
- System context model: A structural model that demonstrates the other systems in the environment of the system being developed. (E.g. block diagram.)
- Interaction model: A dynamic model that shows how the system interacts with its environment as it is used. (E.g. use case diagram.)
Architectural design
The information from the last step is used as a basis for designing the system. You can read all about this in chapter 6.
Object class identification
Identify the objects and operations. Some ways:
- Grammatical analysis: Look at your requirements specifications. Nouns will probably make great objects and verbs great methods.
- Use tangible entities (i.e. things) in the application domain, such as "bike", "aircraft", "evil supercomputer" or "cake" and translate them to objects.
- Scenario-based analysis: Look at each scenario and the various objects required for that scenario.
Design models
These models show the objects or object classes in a system.
- Structural models: Describe the static structure, e.g. a class diagram. You can read about these in chapter 5.
- Dynamic models: Show the interactions between system objects.
The book recommends three models:
- Subsystem models: Show the logical groupings of objects into coherent subsystems. A class diagram with packages, each a collection of objects. (An example of a static model.)
- Sequence models: Shows object interactions. These are dynamic models, e.g. UML sequence diagrams or collaboration diagrams.
- State machine model: Shos how individual objects change their state in response to events. Represented in UML state diagrams, a dynamic model.
Be careful to keep these models simple; a lot of problems can easily be figured out on the fly by your programmers.
Interface specification
The process of designing how the objects will communicate. This is done in UML. An interface looks like an ordinary class, but they don't have any attributes, only methods. They also have guillemets around their class names, e.g. «CrowBar».
Design patterns
A design pattern is a pattern for solving a problem, made available for reuse. Useful for object-oriented design.
The essential elements: - A meaningful name. - A description of the problem area that explains when the pattern can be applied. - A solution description of the parts of the design solution, their relationships, and their responsibilities. Just a template – not a concrete description. Very likely to be graphical. - A statement of the consequences (results and trade-offs).
A good example is the Observer pattern, which solves the problem of telling several objects that the state of some object has changed.
Implementation issues
Some things you will probably need to think about …
Reuse
Reuse is now very widespread, and can occur both in the reuse of abstractions, components, or entire systems.
Usually, this leads to cheaper and more reliable software, but beware:
- Time is used to find software and assess whether it meets your needs.
- Buying reusable software may be expensive.
- Adapting and configuring components costs cash.
- Integration of your own code with the reused software also takes time.
Configuration management
The general process of managing a changing software system. Consists of three fundamental activites:
- Version management: Keeping track of the different versions of software components.
- System integration: Developers define what components are used to create each version of a system.
- Problem tracking: Allows users to report bugs and other problems. Developers should see who is working on these probles and when they are fixed.
Host-target development
Because the software is developed on one system and executed on another, you have to take into account differing operating systems, hardware, and software.
Your software development software (sic) should provide tools to help you with this, such as: - An integrated compiler and syntax-directed editing system. - A debbuging system. - Graphical editing tools (for things such as UML models). - Testing tools, such as JUnit, that test code automatically. - Project support tools, which help organize the code for different development projects.
These are often collected in one Integrated Development Environment, such as Eclipse.
Open source development

Open source means publishing the code with an invitation for anyone to contribute. The benefits are low cost and high reliability, but this requires that there is an active community of people interested in contributing the code (mostly because they're using it themselves). However, if you are a small company, the customers might trust you more if you make open source software – if you go out of business, they can still ask others to develop the code.
Open source licensing
The different open source licenses affect how you have to publish the products that contain the code:
- The GNU General Public License (GPL): If you use this code in any way, you must license your new software under the same terms (i.e. open source code and GPL it).
- The GNU Lesser General Public License (LGPL): A variant of the GPL that allows you to link to the open source components that you used, but still have your new components closed source. However, if you modify the open source components, you must publish your modified source code.
- The Berkley Standard Distribution (BSD) license: You are not obliged to republish any changes or modifications made to the open source code. You can also include it in proprietary and commercial systems, and the only thing you have to do is acknowledge the original creator.
Chapter 8: Software testing

"More efficient, less costly than unit tests", Commit Strip
The testing process tests a program with artificial data. It has two distinct goals:
- Validation testing: Demonstrating to both developers and customers that the software meets its requirements. There should be one test for every requirement.
- Defect testing: Testing the system to discover situations in which the behavior of the software is incorrect or not conforming to standards.
Testing shows the presence, not the absence of bugs – Edsger W. Dijkstra (Wikiquote)
The testing process is part of the process of verification and validation (V&V). They are not the same thing:
- Validation: Are we building the right product?
- Verification: Are we building the product right?
The overall goal of V&V is to see if the software is fit for purpose. How fit it is depends on:
- Software purpose: The more critical the software, the more reliable it should be.
- User expectations: Users are familiar with new software being unreliable (which gives you some slack!), but further into the lifespan, they expect it to be reliable.
- Marketing environment: In a competitive environment, a software company may decide to release a program before it has been fully tested and debugged because being first is more important. (Spotify was released only a few months before Wimp; ask your friends what they are using.)
Testing is a dynamic technique, but there are also static techniques, which don't execute the software. Inspection is one such technique. Why do we need inspection?
- Masking: When testing, one error can mask another error. This means that for the inputs you give, you get correct outputs, but because of things under the hood, this will not be the case for all inputs that will occur. Inspecting the code will (hopefully) reveal this.
- Incompleteness: Your software isn't complete, and developing tests for the incomplete software might be throwing money out the window.
- Broader quality attributes: Certain attributes can never be measured in terms of a boolean "success/failure" rating. Inspection can reveal suboptimal solutions when it comes to adherence to standards, ease of maintenance, efficiency, etc.
This chapter will focus on testing processes (that is, not inspection).
In traditional plan-driven development, test cases specify inputs, expected outputs and state what is being tested. Software is typically tested in three stages.
- Development testing: Testing during development to discover bugs and defects. Done by designers and programmers.
- Release testing: A separate testing team tests a complete version of the system before it is released to users.
- User testing: Potential users test it in their own environment.
Testing is mostly an automated process, but some manual testing is always required.
Development testing
This process includes all testing activities that are carried out by the team developing the system. Usually done by the developer, but sometimes each developer gets an associated tester.
There are three levels to development testing:
- Unit testing: The individual program units or classes are tested. Concerned with objects and their methods.
- Component testing: Several individiual units are integrated to create composite components. Concerned with the component interfaces.
- System testing: Some or all of the components are integrated to test the system as a whole. Concerned with component interactions.
The aim is defect testing: discovering bugs.
Unit testing
The unit tests should cover all features of the objects. You should:
- Test all operations associated with the object.
- Set and check the value of all attributes associated with the object.
- Put the object into all possible states, i.e. simulate all events that cause a state change.
When inheriting methods, it is important to test them both in the superclass and suclasses. The programmers may have made assumptions that are not necessarily true.
A unit test usually consists of the following phases:
- Setup: Initializing the system with the test case (the inputs and expected outputs).
- Call: Call the object or method to be tested.
- Assertion: Compare the result with the expected result.
In case of dependencies, it is often useful to rely on a mock object in order to replace unfinished dependencies or slow dependencies (such as a database).
Choosing unit test cases.
The unit tests should be effective. This means to things:
- The test cases should show that the component does what it is supposed to do.
- Defects should be revealed by the test cases.
It is wise to have two test cases: One to show correct behavior and the other to test a common problem (passing an input value that is too large).
You have two effective strategies for choosing test cases:
- Partition testing: Identify groups of inputs that have common characteristics, which lead to them being processed the same way (e.g. all positive numbers become a positive number when multiplied). Choose tests from within these groups: Testing somewhere in the midpoint is required, and you should also test on the boundaries.
- Guideline-based testing: Use testing guidelines to choose test cases. These reflect the experience of programmers when developing components.
These processes are examples of black-box testing: testing with knowledge only of the inputs and outputs. White-box testing uses some knowledge of the program code as well. For instance, you might know that a certain kind of input should generate a certain kind of error message, so why not test that this is actually the case for all these erroneous input?
In general, you should always do your best to force errors to occur. Choose inputs that are too large, empty, cause buffers to overflow, … use your imagination.
Component testing
Components are (usually) made up of several objects. The functionality of a component is accessed through the component interface, and this is what we're testing for here.
Component errors come from the interactions between objects, and thus it isn't possible to reveal them at earlier stages.
There are different kinds of component interfaces:
- Parameter interfaces: Data and function references are passed from one component to another. Methods in an object have a parameter interface.
- Shared memory interfaces: A block of memory is shared between components. Often used in embedded systems.
- Procedural interfaces: One component encapsulates a set of procedures that can be called by other components. Objects and reusable components have this form of interface.
- Message passing interfaces: One component requests a service from another by passing a message to it. A return message includes the results of executing the service. Some object oriented systems have this form of interface, as do client-server systems.
In complex systems, interface errors are one of the most common forms of error. Interface errors fall into three categories:
- Interface misuse: A calling component calls some other component and makes an error in the use of its interface. Parameters may be of the wrong type, in the wrong order, a wrong number, etc.
- Interface misunderstanding: A calling component misunderstands the specification of the interface of the called component and has made erroneous assumptions. The unexpected behavior trickles down in the system.
- Timing errors: In real time systems that use a shared memory, the producer of the data and the consumer of it may operate at a different speed. The consumer may access outdated data because the producer hasn’t updated it yet.
As with unit tests, you should try your best to break the interface. In message passing interfaces, you should especially try to generate many more messages than are likely to occur, which may reveal timing errors.
System testing
This involves integrating components to create a version of the system that is then tested. This checks for component compatibility, correct interaction and transfer of data at the right time across their interfaces. There are some differences from component testing:
- Reusable components may have been used, and these tests might integrate completely self-developed software with off-the-shelf software.
- Components developed by different team members or groups may be integrated at this stage.
The goal is to reveal emergent behavior, errors that only become obvious when putting the components together.
Testing based on use cases is an effective approach.
Test-driven development
Test-driven development is an approach to program development in which you interleave testing and code development. It has been proven very successful for small and medium sized projects. The fundamental process:
- Identify the increment of functionality that is required; should be small and implementable as a few lines of code.
- Write a test for this functionality and implement it as an automated test.
- Run the test, along with all other tests that have been implemented (even if you have not written any new lines of code).
- Implement functionality and re-run the test.
- Once all tests run successfully, move on to implementing the next chunk of functionality.
Benefits:
- Better understanding of the code.
- Code coverage: Every code segment hase one associated test, and thus you are sure that all code has been executed when you run the tests.
- Regression testing: You can always run regression tests to make sure that adding new functionality hasn't affected the old.
- Simplified debugging: You know the exact place where errors occur.
- System documentation: The tests act as a form of documentation, and reading them makes it easier to understand the code.
Release testing
The process of testing a particular release of a system. A release is a version of the software intended for use outside the development team.
Differences from system testing:
- A separate team that has not been involved in develpoment should be responsible.
- The objective is not finding bugs, but checking that it meets its requirements and is good enough for outside use.
The different approaches:
| Requirements-based testing | Consider each requirement and derive a set of tests for it. |
| Scenario testing | Use the scenarios to develop test cases for the system. This is very motivating for stakeholders, because they identify with the scenarios. |
| Performance testing | Designed to ensure that the system can process its intended load. Usually, you'll test the system with several times its intended load, called stress testing. This is important, because you want to see that the system doesn't cause data corruption or other unforeseen consequences when it fails. It is important to construct an operational profile, which means the tests should reflect the actual load on the system (90% of transaction A, 5% of transaction B, etc.). |
User testing
The stage in which users and customers provide input and advice.
The stages:
- Alpha testing: Users test the software at the developer’s site.
- Beta testing: A release is made available to users for them to experiment with. Mostly used for software products that are used in many different environments.
- Acceptance testing: Customers test a system to decide whether or not it’s ready to be accepted from the system developers. Has six stages:
- Define acceptance criteria: Should take place before the contract for the system is signed, but this can be difficult.
- Plan acceptance testing: Decide on resources, time, and budget for acceptance testing and establish a testing schedule.
- Derive acceptance tests: Once the acceptance criteria have been established, the tests have to be designed. These should test both functional and non-functional characteristics of the system.
- Run acceptance tests: The acceptance tests are executed on the system, ideally in the working environment, but a testing environment may have to be set up.
- Negotiate test results: Some problems will be discovered, and this leads into negotiations between the developer and customers: Is the system good enough to be deployed, and what response should be taken to the missing features?
- Reject/accept system: The developers and the customer decide on whether or not the system should be accepted. Is further development required? If so, this acceptance testing phase will be repeated after further development.
Chapter 9: Software evolution
Software is bound to change. About ⅔ to 90% of software costs are related to evolution.
 © Thom Holwerda
© Thom Holwerda
Implementing changes in the software tends to become less and less cost-effective as time goes by. This is due to more cluttered code and changing hardware and system software. This moves the software from the evolution stage to servicing, which means only tactical changes are made to it.
Evolution processes
Software evolution usually starts with change proposals, which may be new or just unimplemented requirements from the initial development. The process of implementing a change usually goes through these stages:
- Change request
- Impact analysis
- Release planning
- Fault repair
- Platform adaptation
- System enhancement
- Change implementation
- System release
Sometimes, things that require urgent change appear, in which case you won't take the time to go through the usual process. This might be:
- A serious system fault must be repaired to allow normal operation.
- Changes to the system's operating environment have unexpected effects.
- Unanticipated changes to the business running the system, such as new competitors or new legislation.
When handing the project over from the development team to the evolution team, some problems may arise:
- The development team used an agile approach but the evolution team is unfamiliar with this and prefers a plan-based approach. The latter lacks detailed documentation because agile methods rarely produce this.
- The opposite of the first: The software was developed with plan-based approaches, but the evolution team prefers agile methods. The evolution team lacks automated tests and also has to refactor the code.
Program evolution dynamics
The study of system change.
Lehman's laws are claimed to be true for all types of large organizational software systems, which change to reflect changing business needs:
- Continuing change: A program that is used in a real-world environment must necessarily change, or else become progressively less useful in that environment.
- Increasing complexity: As an evolving program changes, its structure tends to become more complex. Extra resources must be devoted to preserving and simplifying the structure.
- Large program evolution: Program evolution is a self-regulating process. System attributes such as size, time between releases, and the number of reported errors is approximately the same for each system release.
- Organizational stability: Over a program's lifetime, its rate of development is approximately constant and independent of the resources devoted to system development.
- Conservation of familiarity: Over the lifetime of a system, the incremental change in each release is approximately constant.
- Continuing growth: The functionality offered by systems has to continually increase to maintain user satisfaction.
- Declining quality: The quality of systems will decline unless they are modified to reflect changes in their operational environment.
- Feedback system: Evolution processes must incorporate multiagent, multi-loop feedback systems to achieve significant product improvement.
Software maintenance
The general process of changing a system after it has been delivered. There are three different types of software maintenance:
- Fault repairs: Coding errors are cheap to correct, design errors are expensive because they involve rewriting several components. Requirements errors are the most expensive because extensive system redesign might be needed.
- Environmental adaptation: Is required when some aspect of the system’s environment changes, such as hardware, operating system, or other support software.
- Functionality addition: A response to organizational or business change. The scale is often much greater than for the other types of maintenance.
It is usually more expensive to add functionality after a system is in operation than while it is being implemented, because of:
- Team stability: The team that developed the code needs little time to understand the software.
- Poor development practice: The development team has no incentive to write maintainable software if they only have a contract for development – to them, it is worthwhile to cut corners.
- Staff skills: Maintenance staff are often relatively inexperienced and unfamiliar with the application domain. This is in part because software engineers like developing more than maintaining, and this leads to younger programmers being put into maintenance.
- Program age and structure: Older systems have worse structure than new ones, and have often been developed with older software engineering techniques.
Maintenance prediction
You should try to predict what system changes might be proposed and what parts of the system are the most difficult to maintain, as well as the overall costs, within a given period.
Some systems have a very complex relationship with their external environment. To evaluate the relationships between a system and its environment, find out:
- The number and complexity of system interfaces: The larger the numbers and the more complex the interfaces, the more likely it is that interface changes will be required as new requirements are proposed.
- The number of inherently volatile system requirements: Volatile means something that is likely to disappear fast. Requirements based on organizational policies and procedures are more volatile than requirements based on stable characteristics of the domain.
- The business processes in which the system is used: Business processes evolve, and thus generate system change requests. The more business processes that use a system, the more demands for system change.
Replacing complex system components with simpler alternatives is the best strategy to reduce maintenance costs.
It is possible to use process data to predict maintainability. These are some possible metrics:
- Numbers of requests for corrective maintenance: An increase in the number of bug and failure reports may indicate that more errors are being introduced into the program than are being repaired. This may indicate a decline in maintainability.
- Average time required for impact analysis: Reflects the number of program components that are affected by the change requests. If this increases, it implies that more and more components are affected and maintainability is decreasing.
- Average time taken to implement a change request: The amount of time that you need to modify the system and its documentation, after having assessed which components are affected. An increase in the time needed to implement a change may indicate e decline in maintainability.
- Number of outstanding change requests: An increase in this number over time may imply a decline in maintainability.
Software reengineering
To make legacy software systems easier to maintain, you can reengineer these systems to improve their structure and understandability. This may involve redocumenting the system, refactoring the system architecture, translating programs to a modern programming language, and modifying and updating the structure and values of the system’s data. Functionality is not changed and major changes to the system’s architecture should be avoided. The benefits of this is reduced risk and reduced cost.
There are practical limits to how much you can improve a system by reengineering. For instance, it is impossible to convert a system based on a functional approach to an object-oriented system; you'll just have to scrap it and start anew.
Preventative maintenance by refactoring
Refactoring is improving the structure and reducing the complexity of code. There are certain bad smells (signs of code that should be refactored):
- Duplicate code: If you have several pieces of code that are exactly the same, they can be turned into a method.
- Long methods: Could be several, smaller methods.
- Switch statements: Switch cases often involve duplication. Polymorphism in object-oriented languages can be used to replace this.
- Data clumping: The same group of data items reoccur several places and can be replaced by an object.
- Speculative generality: The program includes a lot of generality just in case it will be required in the future. Can be removed.
Legacy system management
Many businesses depend on legacy systems, which still have to be extended and adapted. When maintaining such a system, you have four options:
- Scrap it: If it is not contributing any more or is going against the way things are currently done, you can often choose this option with good conscience.
- Leave it unchanged and continue with regular maintenance: When the system is still required and is fairly stable (so that the users don't make a lot of change requests).
- Reengineer it to improve its maintainability: When the system quality has degraded so much that it can't be maintained, but it is still needed and there is potential for further development.
- Replace all or part of it with a new system: When new hardware or other such factors doesn't support the old system and off-the-shelf systems can replace the old system.
You can place the system in this chart to see what you should do:
| Low business value | High business value | |
| Low quality | Scrap it. Keeping it will be expensive and returns microscopic. | Reengineer the system or replace it. Maintaining the old will be expensive. |
| High quality | Keep up normal maintenance. If expensive maintenance is required, scrap it. | You're lucky: Keep up normal maintenance. |
Chapter 11: Dependability and security
The problems that result from system and software failures are increasing. That is not because software is getting worse, but because technology is becoming a bigger and bigger part of our lives. That makes dependability more important than ever, as well as:
- System failures affect a large number of people. (Ever heard about
- Users often reject systems that are unreliable, unsafe, or insecure. (Ever heard about Windows ME?)
- System failure costs may be enormous.
- Undependable systems may cause information loss. (Ever heard about Pixar?)
You have to consider the possibility of these types of failure:
- Hardware failure: System hardware may fail because of mistakes in its design, because components fail as a result of manufacturing errors, or because the components have reached the end of their natural life.
- Software failure: System software may fail because of mistakes in its specification, design, or implementation.
- Operational failure: Human users may fail to use or operate the system correctly. This has become the largest single cause of system failures.
Dependability properties
The dependability of a system is a property that reflects its trustworthiness. Trustworthiness means the degree of confidence a user has that the system will work as they expect and not fail during normal use. However, a system might be useful even if it’s not very trustworthy: Most word processors and computers crash, but users take counter-measures, such as backing up their work frequently.
The four principal dimensions of dependability:
- Availability: The probability that it will be providing useful services at any given time.
- Reliability: The probability that over a given amount of time, the service will correctly deliver services as expected by the user.
- Safety: A judgement of how likely it is that the system will cause damage to people or its environment.
- Security: Informally, how likely it is that the system can resist accidental or deliberate intrusions.
These can be broken down into even more fine-grained measurements.
Some additional properties:
- Repairability: If the system can be repaired quickly, the problems caused by failure can be minimized.
- Maintainability: Will it be cheap to adapt the software to cope with new requirements with a small probability of errors?
- Survivability: The ability of a system to deliver its services whilst under attack or while part of the system is disabled. Focuses on identifying key system components and ensuring that they can deliver a minimal service. Three strategies:
- Resistance to attack
- Attack recognition
- Recover from attack damage
- Error tolerance: How much a system has been designed so that user input errors are avoided and tolerated. These errors should be detected and either fixed automatically or data should be reinputted.
Availability and reliability
These two properties can be measured numerically:
- Reliability: The probability of failure-free operation over a specified time, in a given environment, for a specific purpose. (Because it is for a given environment, it may obviously vary from one environment to another.)
- Availability: The probability that a system, at a point in time, will be operational and able to deliver the requested services.
It might seem great to have a very reliable system, which fails rarely. However, if you have a system that fails once a year and takes 7 days to restore to a full operational state (available 51/52 of the time), it might be better to have a system that fails once a day and takes one minute to restore to a full operational state (available 1439/1440 of the time).
Some reliability terminology:
- Human error or mistake: Human behavior that results in the introduction of faults into a system. (The human inputs a time into an alarm clock that is greater than 23:59)
- System fault: A characteristic of a software system that can lead to a system error. (Often caused by a programmer assumption, such as thinking that adding one hour when you add 1 to 59 minutes is the best way to increment time, which holds until you add one hour to 23:59).
- System error: An erroneous system state that can lead to system behavior that is unexpected by system users. (The faulty code leads to the hour being set to 24:xx rather than 00:xx.) It is important to note that the fault is what loads the gun; this is what cocks it.
- System failure: An event that occurs at some point in time when the system does not deliver a service as expected by its users. (The lack of transmission due to bad time formatting). The gun is fired.
A system fault doesn't necessarily become a system error; it might be corrected by some other processes.
Some approaches used to improve the reliability:
- Fault avoidance: Development techniques that either minimize the possibility of human errors and/or that trap mistakes before they result in the introduction of system faults. This includes avoiding error-prone programming language constructs such as pointers and the use of static analysis to detect program anomalies.
- Fault detection and removal: The use of verification and validation techniques that increase the chances that faults will be detected and removed before the system is used. Systematic testing and debugging are examples.
- Fault tolerance: Techniques that ensure that faults in a system do not result in system errors or that system errors do not result in system failures. The incorporation of self-checking facilities in a system and the use of redundant system modules are examples of these.
Safety
Safety-critical systems are systems where it is essential that system operation is always safe. It is usually simpler to implement hardware control (having an electrical switch that shuts off the microwave whenever the door opens) than software control, but systems we build today are sometimes so complex that they can’t be controlled by hardware alone.
This type of software falls into two classes:
- Primary safety-critical software: Software that is embedded as a controller in a system, such as the software in an insulin pump.
- Secondary safety-critical software: Software that can indirectly result in an injury, such as in a computer-aided engineering design system. (Faulty designs might lead to a building collapsing, in the worst case. Or perhaps your nuclear plant blowing up.)
There are four reasons why software systems that are reliable are not necessarily safe:
- We can never be 100 % certain that a software system is fault-free and fault-tolerant. Undetected faults may lie dormant for many years.
- The specification may be incomplete in that it does not describe the required behavior of the system in some critical situations.
- Hardware malfunctions may cause the system to behave in an unpredictable way, and present the software with an unanticipated environment.
- The system operators may generate inputs that are not individually faulty but which, in some situations, can lead to a system malfunction. (Pressing the lift wheels button while the plane is on the ground.)
Some vocabulary: - Accident (or mishap): An unplanned event or sequence of events which result in human death or injury, damage to property, or to the environment. - Hazard: A condition with the potential for causing or contributing to an accident. (Failure of a sensor, for instance.) - Damage: A measure of the loss resulting from a mishap. - Hazard severity: An assessment of the worst possible damage that could result from a particular hazard. - Hazard probability: The probability of the events occurring which create a hazard. - Risk: A measure of the probability that the system will cause an accident.
The key to assuring safety is to make sure that accidents either do not occur or that the consequences of an accident are minimal. Three complimentary ways of doing this:
- Hazard avoidance: The system is designed so that hazards are avoided. (Requiring two buttons to be pressed at the same time avoids the hazard of the operator’s hands being in the way of a cutting machine.)
- Hazard detection and removal: The system is designed so that hazards are detected and removed before they result in an accident. (Detecting high pressure and opening a valve before an explosion occurs.)
- Damage limitation: The system may include protection features that minimize the damage that may result from an accident. (Automatic fire extinguishers in an aircraft engine.)
Accidents most often happen due to a combination of errors at the same time, which may be hard to anticipate (ever heard about Fukushima?). This is an argument against software control, which often requires that we anticipate errors beforehand. However, software is very reliable and may give us further information and opportunities for control that could never be done by hardware.
Security
Security reflects the ability of the system to protect itself from external attacks, which may be accidental or deliberate. This risk has become greater because of increased networking (via the Internet).
Terminology: - Asset: Something valuable which has to be protected. E.g. the system itself or its data. - Exposure: Possible loss or harm to a computing system. Can be a loss or damage to data, or can be a loss of time and effort if recovery is necessary after a security breach. - Vulnerability: A weakness in a computer-based system that may be exploited to cause loss or harm. - Attack: An exploitation of a system’s vulnerability. Generally, this is from outside the system and is a deliberate attempt to cause some damage. - Threats: Circumstances that have potential to cause loss or harm. You can think of these as a system vulnerability that is subjected to an attack. - Control: A protective measure that reduces a system’s vulnerability. Encryption is an example of a control that reduces a vulnerability of a weak access control system.
In any networked system, there are three main types of security threats:
- Threats to the confidentiality of the system and its data: These can disclose information to people or programs that are not authorized to have access to that information.
- Threats to the integrity of the system and its data: These threats can damage or corrupt the software or its data.
- Threats to the availability of the system and its data: These threats can restrict access to the software or its data for authorized users.
Bad authorization habits are perhaps the most vulnerable points in sociotechnical systems (medical systems, systems used by the government):
- People’s usernames resemble their real names.
- People choose easy to use passwords.
- People write down their passwords in places where they can be found (perhaps due to system administrators requiring frequent password changes).
- System administrators make errors in setting up access control or configuration files.
- The computer doesn’t have safety software.
 "To anyone who understands information theory and security and is in an infuriating argument with someone who does not (possibly involving mixed case), I sincerely apologize." (xkcd 936: Password Strength, CC-BY-NC 2.5 Randall Munroe)
"To anyone who understands information theory and security and is in an infuriating argument with someone who does not (possibly involving mixed case), I sincerely apologize." (xkcd 936: Password Strength, CC-BY-NC 2.5 Randall Munroe)
Some controls that might be put in place:
- Vulnerability avoidance: Controls that are intended to ensure that attacks are unsuccessful. (Not connecting to the network, denying external access or strong encryption.)
- Attack detection and neutralization: Controls that are intended to detect and repel attacks. (Shutting down parts of the system where suspicious activities occur.)
- Exposure limitation and recovery: Controls that support recovery from problems. (Automated backup, but perhaps even special insurance policies that cover the costs.)
Chapter 16: Software reuse
Software reuse has become the most popular method of developing new custom software. This is due to:
- Demands for software faster and cheaper
- Increased availability due to more businesses basing their revenue on developing reusable software
- Availability of open source software on the web.
- The use of standards, such as web standards.
The software units that are reused may be of radically different sizes. For example:
- Application system reuse: A whole application system is reused by incorporating it without changing into other systems or by configuring the application for different customers. Alternatively, application families that have a common architecture are tailored for specific customers.
- Component reuse: Components of an application, ranging in size from subsystems to single objects, may be reused.
- Object and function reuse: Software components that implement a single function, such as a mathematical function, or an object class may be reused.
A complementary form of reuse is concept reuse, which means reusing the concept of a solution rather than the implementation (such as an algorithm).
Benefits:
- Increased dependability: Reused software which has been tried and tested, should be more dependable than new software. Most of its design and implementation faults should have been found and fixed.
- Reduced process risk: The cost of existing software is known; costs of development are always unpredictable.
- Effective use of specialists: Application specialists can develop reusable software that encapsulates their knowledge.
- Standards compliance: Some standards, such as user interface standards, can be implemented as a set of reusable components. The risk of user mistakes is reduced if the users are familiar with the interface.
- Accelerated development: Bringing a system to market as early as possible is often more important than overall development costs.
Problems:
- Increased maintenance costs: If the source code of the reused software system is not available, maintenance costs may be higher because the reused elements of the system may become increasingly incompatible with system changes.
- Lack of tool support: Some software tools do not support development with reuse, which make them impossible or difficult to integrate with a component library system.
- Not-invented-here syndrome: Some software engineers prefer to rewrite components because they believe they can improve on them. This is both due to trust and the prestige involved in writing your own software.
- Creating, maintaining, and using a component library: Populating a reusable component library and ensuring the software developers can use this library can be expensive. Development processes have to be adapted to ensure that the library is used.
- Finding, understanding, and adapting reusable components: Software components have to be discovered in a library, understood, and sometimes adapted to work in a new environment. Engineers must be reasonably confident of finding a component in the library before they include a component search as part of their normal development process.
The reuse landscape
Key factors in planning reuse:
- The development schedule for the software: Shorter schedules increase the need for reuse.
- The expected software lifetime: A long-lifetime system should not rely on software you don’t have access to the source code of; it may change or support may discontinued.
- The background, skills, and experience of the development team: All reuse technologies are fairly complex, and you need quite a lot of time to understand and use them effectively. You should reuse software that your team has the skill to understand.
- The criticality of the software and its non-functional requirements: Critical systems must often be certified by an external regulator, which is hard if you don’t have access to the source code. Efficiency demands hare hard to meet if you don’t make the code yourself.
- The application domain: Some application domains have several generic products available for reuse. (No need to make an alternative to Microsoft Word.)
- The platform on which the system will run: Some component models run only on specific platforms (.NET runs only on Microsoft platforms, for instance.); you may not be able to use them.
Whether or not you reuse software, is often up to the customer or managers: People don't like compromising their requirements, and are willing to accept the risks involved in original development rather than adapt their requirements.
Application frameworks
When object oriented programming first started out, its proponents said stuff like: "In the future, everyone will reuse each others objects!", "We will rarely have to code anything twice, ever again", and "This will lead us to a magical land filled with unicorns". You, living several decades later, may notice that this has not become true: We often have to write things again (and there is a noticable lack of unicorns). This is because objects are often too specific to be used again without adapting them.
A framework is a generic structure that is used to create more specific subsystems or applications, and these have become more useful than object reuse. Frameworks are implemented as a collection of concrete and abstract object classes in an object-oriented programming language – they are language-specific. They are often implementations of design patterns.
Three possible classes of frameworks:
- System infrastructure frameworks: Support the development of system infrastructures, such as communications, user interfaces, and compilers.
- Middleware integration frameworks: Consist of a set of standards and associated objects classes that support component communication and information exchange. Examples: .NET framework, Enterprise Java Beans, etc.
- Enterprise application frameworks: Are concerned with specific application domains, such as telecommunications or financial systems. Embed application domain knowledge and support the development of end-user applications.
An important type of framework are web application frameworks. Most of them support the following:
- Security: They may include classes to help implement user authentication and access control.
- Dynamic web pages: Classes are provided to help you define web page templates and populate these dynamically with specific data from the system database.
- Database support: Most frameworks don’t include a database but assume that a separate database (e.g. MySQL) will be used.
- Session management: Classes to create and manage user sessions.
- User interaction: Most web frameworks now provide AJAX support, which allows for more interactive web pages.
Software product lines
A software product line is a set of applications with a common architecture and shared components, with each application specialized to reflect different requirements. This usually emerges from one initial application.
The main differences between application frameworks and software product lines:
- Frameworks rely on object-oriented features to implement extensions. A software product line is not necessarily object oriented, and components may be changed or rewritten.
- Frameworks are focused on providing technical rather than domain-specific support. A product line could be concerned with health-applications, while this is rarely seen in frameworks.
- Product lines are often control applications for equipment, and might thus be concerned with hardware interfacing. Frameworks are software-oriented and rarely provide support for hardware interfacing.
- Software product lines are made up of a family of related applications, owned by the same organization. When creating a new application, the starting point is often the closest member of the family, not the generic framework.
Various types of specialization of software product lines:
- Platform specialization: Versions of the application for different platforms.
- Environment specialization: Versions of the application are created to handle particular operating environments and peripheral devices.
- Functional specialization: Different versions of an application for specific customers who have different requirements.
- Process specialization: The system is adapted to cope with specific business processes. One version of an ordering system that supports distributed processes in one version and a centralized process in another.
The steps involved in extending a software product line to create a new application:
- Elicit stakeholder requirements: A normal requirements process, but with the twist that a system already exists and stakeholders use this as the basis for their requirements.
- Select the existing system that is the closest fit to the requirements: You may start with the family member that is the closest fit.
- Renegotiate requirements: You want to minimize the changes that are needed.
- Adapt existing system: Develop new modules and adapt the existing system modules.
- Deliver new family member: Also, document its key features; it will be useful as a basis for other developments in the future.
There are two different ways to configure the system:
- Design-time configuration: The organization that is developing the software modifies a common product line core by developing, selecting, or adapting components to create a new system for a customer.
- Deployment-time configuration: A generic system is designed for configuration by a customer or consultants working with the customer. Knowledge of the customer’s specific requirements and the system’s operating environment is embedded in a set of configuration files that are used by the generic system.
- Component selection: Select the modules that provide the required functionality.
- Workflow and rule definition: Define workflows (how information is processed, stage by stage) and validation rules that apply to information entered by users or generated by the system.
- Parameter definition: Specify the values of specific system parameters that reflect the instance of the application that you are creating.
COTS product reuse
COTS stands for Commercial-Off-The-Shelf software, and it refers to software systems that can be adapted to the needs of different customers without changing the source code. This is done using the software's built-in configuration mechanisms.
Benefits of COTS:
- Rapid deployment.
- You can see what functionality is provided.
- Some development risks avoided.
- Less money spent on IT systems development.
- The updates are the responsibility of the developer, not the customer.
Problems with COTS:
- You have to adapt requirements to the functionality provided, not the other way around.
- Assumptions made by the COTS developers may be impossible to work around, and thus you have to change your business processes.
- Choosing the right system is hard – many are not well documented. Choosing wrong is disastrous.
- You may lack the local expertise to support systems development and thus rely on the company and external consultants for development advice – who may be biased (trying to get you to purchase more products, pay for premium service, etc.).
- You leave the questions of system support and evolution at the hands of the developer. They may go out of business or make changes that you don’t like.
COTS-solution systems
Generic application systems that may be designed to support a particular business type, activity, or sometimes, a complete business enterprise with an Enterprise Resource Planning system. (ERP)
Key features of an ERP system:
- A number of modules to support different business functions.
- A defined set of business processes, associated with each module, which relate to activities in that module.
- A common database that maintains information about all related business functions.
- A set of business rules that apply to all data in the database.
The configuration process may involve:
- Selecting the required functionality from the system.
- Establishing a data model that defines how the organization’s data will be structured in the system database.
- Defining business rules that apply to data.
- Defining the expected interactions with external systems.
- Designing the input forms and the output reports generated by the system.
- Designing new business processes that conform to the underlying process model supported by the system.
- Setting parameters that define how the system is deployed on its underlying platform.
COTS-integrated systems
Systems that include two or more COTS products or sometimes legacy application systems. They usually interact through their APIs or service interfaces. Alternatively, they might process each others’ outputs or manipulate the same database.
Some design choices: - Which COTS products offer the most appropriate functionality? This will be hard if you don’t have experience with them. - How will data be exchanged? Exchanging data from one program to the other usually requires converting data to different formats. - What features of a product will actually be used? If appropriate, try to deny access to unused functionality.
Four important COTS system integration problems
- Lack of control over functionality and performance: The published interface may appear to offer the required facilities, but may be improperly implemented or perform poorly.
- Problems with COTS system interoperability: Each COTS product might make its own assumptions, which vary for even the simplest things (such as event handling).
- No control over system evolution: Vendors decide on system changes. Especially PC products are subject to rapid change.
- Support from COTS vendors: The level of support varies widely.
Chapter 17: Component-based software engineering
When off-the-shelf alternatives aren’t available, component-based software engineering is an effective approach.
Components are higher-level abstractions than objects and are defined by their interfaces. CBSE is the process of defining, implementing and integrating or composing loosely coupled, independent components into systems.
The essentials of CBSE:
- Independent components that are completely specified by their interfaces. This means that you should only specify what goes in and out, and not be specific about how the gears inside work. This makes it easy for you to replace the gears later.
- Component standards that makes it easy to integrate components; these are embodied in a component model. They define (at minimum) how component interfaces should be specified and how components communicate, but may also specify interfaces that should be implemented by all components that conform to the standard. If components conform to standards, then their operation is independent of programming language. (You can thus have components written in different languages in the same system.)
- Middleware that provides software support for component integration. Middleware for component support handles low-level issues efficiently and allows you to focus on application-related problems. The middleware might also provide support for resource allocation, transaction management, security, and concurrency.
- A development process that is suitable for component-based software engineering.
Design principles:
- Independence: Components are independent so that they don’t interfere with each other’s operation.
- Interfaces: Components communicate through well defined interfaces.
- Services: Component infrastructures offer a range of standard services that can be used in application systems, which reduces the amount of new code needed in each project.
Components and component models
A component is an independent software unit that can be composed with other components to create a software system. Practically, it can be viewed as a service.
Component characteristics:
- Standardized: Means that a component used in a CBSE process has to conform to a standard component model. This may define component interfaces, component metadata, documentation, composition, and deployment.
- Independent: It should be independent, which means it should not depend on other specific components. In case this is needed, it should be specified in a ‘Requires’ interface specification.
- Composable: All external interactions must take place through publicly defined interfaces. This requires it to give external access to information about itself, such as methods and attributes. (This part is called the ‘Provides’ interface specification.)
- Deployable: It has to be self-contained – usually this means it has to be binary and not be compiled before it is deployed.
- Documented: Documentation has to be available so that users can decide on whether to use it or not. The syntax and ideally also the semantics of its interfaces should be specified.
Component models
A definition of standards for component implementation, documentation and deployment. Examples are Enterprise Java Beans and .NET.
Elements of a component model:
- Interfaces: The component model specifies how the interfaces should be defined and the elements which should be included in the interface definition.
- Usage: In order for components to be distributed and accessed remotely, they need to have a globally unique name or handle associated with them, such as the com.. specification in EJB. Components have meta-data, such as information about its interfaces.
- Deployment: The component model includes a specification of how components should be packaged for deployment as independent, executable entities. Should also include rules for how replacement of the component with new versions should be done.
The services provided by a component model implementation fall into two categories:
- Platform services: Enable components to communicate and interoperate in a distributed environment.
- Support services: Common services that are likely to be required by many different components.
CBSE processes
Software processes that support component-based software engineering. Two types:
- Development for reuse
- Development with reuse
We will now elaborate on them.
CBSE for reuse
Developing reusable components and making them available for reuse through a component management system. In the beginning of component based engineering, the programmers imagined that a few years in the future, we would have a a huge global marketplace of components, and everyone would buy components (and unicorns would finally fly through the sky). However, nearly all component reuse today takes place within the organization that originally made the components.
When deciding whether a component should be reused, evaluate whether a component is likely to be reused and if the cost-savings will be greater than the costs expended to make the component reusable.
Some changes to make components more reusable:
- Removing application specific methods
- Changing names to make them general.
- Adding methods to provide more complete functional coverage.
- Making exception handling consistent for all methods.
- Especially difficult, because the component should not handle exceptions itself. Rather, you should only define what exceptions can arise.
- This makes the component harder to understand and harder to code for
- Adding a ‘Configuration’ interface to allow the component to be adapted to different situations of use.
- Integrating required components to increase interdependence.
This is often done when reengineering legacy systems.
CBSE with reuse
Essential differences between CBSE with reuse and software processes for original software development:
- The user requirements are initially developed in outline rather than in detail, and stakeholders are encouraged to be as flexible as possible.
- Requirements are refined and modified early in the process depending on the components available.
- There is a further component search and design refinement activity after the system architecture has been designed. (Components might turn out to be unsuitable after all.)
- Development is a composition process where the discovered components are integrated. Often the components must be reconciled with adaptors.
Architectural design is especially important in CBSE.
Component composition
The process of integrating components with each other, with glue code, to create a system or another component.
There are three ways to compose two components (called A and B):
- Sequential composition: A and B both have provides interfaces, which are put together using glue code. This glue code transfers the results of one component sequentially to the other and might also convert it to a format readable by the receiver. (You can think of the way a McFlurry is made by two machines: One provides ice cream and the other some yummy sprinkling. The ice cream and sprinkling are given by their machines' provides interfaces, and that little paper cup is the glue code.)
- Hierarchical composition: One component has a provides interface, the other a requires. They are then put together as two pieces of lego. No glue code required.
- Additive composition: Two or more components are put together to create a new component that combines their functionality (like those old combined VHS and DVD players). They are not dependent and do not call each other. There might be glue code inside to transform their requires and provides interfaces.
Three types of interface incompatibility can occur:
- Parameter incompatibility: Operations on each side have the same name, but their parameter types and number of parameters are different.
- Operation incompatibility: The names of the operation in the provides and requires interfaces are different.
- Operation incompleteness: The provides interface of a component is a subset of the requires interface of another component or vice versa.
All are solved by writing an adaptor, or glue code if you like to call it that.
One might want to specify conditions that are always true when using an interface. This is specified in the Object Constraint Language (Wikipedia), which is now a part of the UML. This might specify constraints, such as that the size of an array should always grow by one when we use the add()-method, for instance.
Chapter 18: Distributed software engineering
"[A distributed system is a] collection of independent computers that appears to the user as a single coherent system." – Tanenbaum and van Steen (2007)
Nearly all large computer-based systems today are distributed systems. These involve several computers. A centralized system is the opposite, and it executes on a single computer. Distributed systems are, obviously, more complex than centralized systems.
Advantages of a distributed approach:
- Resource sharing: Sharing of hardware and software resources on a network.
- Openness: Distributed systems are normally open; they use standard protocols that allow equipment and software from different vendors to be combined.
- Concurrency: Several processes operate at the same time on separate computers in the network. They may (but need not) communicate with each other during normal operation.
- Scalability: In principle, a system can be scaled by simply adding new resources.
- Fault tolerance: The availability of several computers and the potential for replicating information mean that distributed systems can be tolerant of some hardware and software failures – providing a degraded service to the users. The only error that causes a total shutdown in practice is a network failure.
Distributed systems issues
The reason for distributed systems being more complex is that it is impossible to have a top-down model of control of the system – having a single authority is impossible. They are therefore a bit unpredictable, and this has to be considered in design.
Some important design issues:
- Transparency: To what extent should the system appear to the user as a single system? When is it useful for users to understand that the system is distributed?
- Ideally, a distributed system should be transparent to the user: They wouldn’t be able to distinguish it from a centralized system. This is impossible to achieve in practice due to the lack of centralized control and network delays.
- We have to create abstractions of the resources in a distributed system, so that parts can be replaced without having to change the interfaces. Middleware is used to map the logical resources referenced by a program onto the actual physical resources and to manage the interactions between these resources. In general, it is good to let the users know that the system is distributed so that they can prepare for the "consequences".
- Openness: Should the system use standard protocols that support interoperability, or should more specialized protocols be used that restrict the freedom of the designer?
- In networking, openness is taken for granted due to the IP protocol. This is not the case at the component level; the CORBA standard (Wikipedia) was intended to achieve this, but it is not widely used.
- Some web service standards have been developed as open standards for service-oriented architectures. Developers consider them inefficient, and therefore they have not achieved widespread usage; instead, RESTful protocols (Wikipedia) are being used.
- Scalability: The system should be constructed to be scalable; how can this be done? Three dimensions:
- Size: It should be possible to add more resources.
- Distribution: Geographical spread of components without degrading the performance.
- Manageability: It should be possible to manage a system as it increases in size, even if parts of the system are located in independent organizations (which is often the case).
- Security: How can we define and implement usable security policies that can be applied across a set of independently managed systems? The main difficulty in establishing this is that separate organizations may own parts of the system. Distributed systems are open to even more attacks than centralized systems:
- Interception: An attacker intercepts communications between parts of the system.
- Interruption: System services are attacked and can’t be delivered as expected. DoS attacks (Wikipedia) are an example.
- Modification: An attacker changes data or services in the system.
- Fabrication: An attacker generates information that shouldn’t exist and uses this to gain privileges.
- Quality of service: How should we define an acceptable quality of service, and how should we deliver this to users? It is hard to define it in advance because:
- It may not be cost effective to design and configure the system to deliver a high quality of service under peak load. Cloud computing makes it easier to add resources when they are needed.
- There are trade-offs in quality of service parameters. Having a high reliability often means decreased throughput.
- Failure management: How can system failures be detected, contained (to have minimal effects on other components in the system), and repaired?
- Involves applying fault tolerance techniques (discussed in ch. 13, not in curriculum. Hurrah!)
Models of interaction
There are two fundamental types of interaction between computers in a distributed system:
- Procedural interaction: One computer calls on a known service offered by another computer.
- Similar to communicating with a waiter in a restaurant: You ask for food, and after you've waited for a while, he brings it in.
- Usually done with Remote Procedure Calls – this allows one component to call another as if it was a local procedure or method.
- A problem is that both the caller and the callee need to be available at the time of communication and need to know how to refer to each other.
- Message-based interaction: The sender defines what is required by the receiver in a message. Usually transmits more information in one step than in procedural interactions.
- Like mail-ordering from Ellos (the middleware).
- The services don't need to be available at the same time or aware of each other. They communicate with the middleware, which handles the passing of messages.
Middleware
Middleware sits between the distributed components of the system, which may be programmed in different programming languages and execute on different types of processors. Usually, the middleware is a set of libraries and a run-time system to manage communications. This is installed on every computer in the distributed system.
Middleware usually provides two distinct types of support:
- Interaction support: The coordination of interactions between different components in the system. Transparency is provided to local components. May do parameter conversions between different components.
- Provision of common services: Middleware provides reusable implementations of services that may be required by several components in the distributed system.
Client–server computing
In client–server architectures, an application is a set of services that are provided by servers, such as on the web (this compendium is provided to your web browser by the Wikipendium servers). The clients access these services and present results to end users. The clients are usually single-processor systems that run multiple processes. The servers might be multiple-processor systems.
There should be a clear separation between presentation of information and the computations required to get the information. Thus, the design should contain several logical layers with clear interfaces between them.
A possible layering:
- Presentation layer: Presents the information to the user and manages user interactions.
- Data management layer: Manages the data that is passed to and from the client. May check data, generate web pages etc.
- Application processing layer: Implements the logic of the application and thus provides the required functionality to users.
- Database layer: Stores the data and provides transaction management.
Architectural patterns for distributed systems
We will discuss five architectural styles:
- Master-slave architecture: Used in real-time systems in which guaranteed interaction response times are required.
- Two-tier client–server architecture: Used for simple client-server systems and in situations where security reasons demand we centralize the system (usually with encryption of communications).
- Multitier client-server architecture: Used when there is a high volume of transactions that the server has to process.
- Distributed component architecture: Used when resources from different systems and databases need to be combined, or just as an implementation model for multi-tier client-server systems.
- Peer-to-peer architecture: The server’s role is to introduce clients to each other. The peers exchange locally stored information. May also be used when a large number of independent computations may have to be made.
Master-slave architectures
Commonly used in real-time systems where there may be separate processors associated with data acquisition from the system’s environment, data processing, and computation and actuator management. An actuator is a device controlled by the software system that acts to to change the system’s environment, such as a device that changes a valve from a closed to an open state.
The master process’ responsibilities are usually computation, coordination and communications, and it controls the slave processes. The slaves are dedicated to specific actions, such as data acquisition from sensors.
The master-slave model should be used in situations where it is possible to predict the distributed processing that is required, and where processing can be easily localized to slave processors.
Two-tier client–server architectures
A two-tier client–server architecture is the simplest form of client–server architecture: A single logical server plus an indefinite number of clients that use this server. There are two versions:
- Thin-client model: The presentation layer is implemented on the client, and all other layers are on the server.
- Advantages: Easy to manage; you avoid installing new software, which might be time-consuming.
- Disadvantages: Places a heavy processing load on the server and network.
- Fat-client model: Some or all of the application processing is carried out on the client. The server is mainly a transaction server.
- Advantages: Less load on the server and network.
- Disadvantages: Requires additional system management to deploy and maintain the software.
Multi-tier client–server architectures
The main problem with the two-tier client–server architectures is that it is hard to scale. It is possible to distribute the layers even more, and this is done in a multi-tier architecture.
This is usually done when there are very many clients, the data and application are volatile, and/or data from multiple sources are integrated.
Distributed component architectures
The problem with layering, is that it’s not always clear where a service belongs – or it may not be possible to layer the services at all. Distributed component architectures are a solution to this: The system is considered a set of services implemented in a separate components that interact with each other. They rely on middleware, which we have described earlier.
Benefits:
- The system designer can delay decisions on where and how services should be provided and disregard layering.
- Allows new resources to be added with very little disruption to the system. It is thus very open.
- A flexible and scalable system: When the load increases, add new or replicated components.
- It is possible to reconfigure the system dynamically with components migrating across the network as required – a service providing component can migrate to the same processor as service-requesting objects, thus improving the performance of the system.
Disadvantages:
- The design is more complex than for client–server systems. This is partially because it is easier for humans to relate the client–server architecture to their everyday lives.
- There is no widespread standard for middleware; Microsoft and Sun have developed different incompatible middleware solutions.
These disadvantages have lead to service-oriented architectures replacing distributed component architectures. Distributed component architectures have the advantage of faster performance: Remote procedure call communications are usually faster than message-based interactions. Consider this trade-off.
Peer-to-peer architectures
Peer-to-peer architectures are decentralized, and in principle all nodes in the network are equal. This means processing can be carried out in any node. The nodes have to run an application that includes the standards and protocols for communication in the network. This has been more successful in personal use (ever heard about BitTorrent? I've heard they have free music there) than in business use, but examples of the latter occur.
This is appropriate for a system in two circumstances:
- The system is computationally intensive and it is possible to separate the processing required into a large number of independent computations. Usually involves super-peers to distribute work and collect the results.
- The system primarily involves the exchange of information between individual computers on a network (file-sharing, etc.).
Its main advantage is that the network is robust, due to a large distribution of data. Its main disadvantage is that there is a large overhead involved in finding the required data.
Software as a service
Modern web technologies such as AJAX have made it easy to perform computations locally through scripts. This means a web browser can be turned into a client, and this has lead to software as a service (SaaS).
The key elements of SaaS
- Software is deployed on a (number of) server(s) and accessed through a web browser. It is not deployed on a local PC.
- The software is owned and managed by a software provider, rather than the organizations using the software.
- Users may pay for the software according to usage amount or through a subscription. It may be funded by ads.
The main advantages and disadvantages go hand in hand here: - Control over software is transferred to the software providers. This means less worrying about hardware and bugs for the customers, but also means less control over evolution – and transferring your organization's data to an external company (perhaps located in another country) might breach laws. - Network access means it is available anywhere, but this increases load on the network and transferring large amounts of data takes time.
SaaS resemble Service-Oriented Architectures, but they are not the same. The main difference is that transactions in SOAs are usually very short and their services might be distributed – there is usually just a short service.
Service development resembles other types of software development in a number of ways – but it’s usually driven by the provider’s assumptions about what people need (the guys at Google sit down and ask themselves: "What features do people want from Google Docs?"). The software should be developed with agile development, being able to respond to user’s feedback quickly.
Different organizations use the software, so take three factors into account:
- Configurability: How do you configure the software for the specific requirements of each organization?
- Multi-tenancy: How do you present each user of the software with the impression that they are working with their own copy of the system while still making efficient use of system resources?
- Multi-tenancy is the requirement that is the hardest to meet.
- Relational databases have a huge overhead in these applications; Google uses a simpler system.
- Data management is hard – employing a separate database for each specific user is also inefficient in terms of capacity.
- The simplest alternative to a single database for each user is to have one database with each user virtually isolated.
- Multi-tenancy is the requirement that is the hardest to meet.
- Scalability: How can you scale the system for an unpredictably large number of users?
- Scalability is usually done by scaling out – adding more servers. Some guidelines:
- Develop applications where each component is implemented as a simple stateless service that may be run on any server.
- Design the system using asynchronous interaction (the client will not have to wait).
- Manage resources, such as network and database connections, as a pool, so that no single server is likely to run out of resources.
- Design your database to allow fine-grain locking – the whole record is not locked when only a part of it is used.
- Scalability is usually done by scaling out – adding more servers. Some guidelines:
You should allow for user configuration:
- Branding: Users are presented with an interface that reflects their own organization.
- Business rules and workflows: Each organization defines its own rules that govern the use of the service and its data.
- Database extensions: Each organization defines how the generic service data model is extended to meet its specific needs.
- Access control: Customers create individual accounts for their staff and define what resources and functions that are available to each one individually.
Chapter 19: Service-oriented architectures
Service oriented architectures are a way of developing distributed systems where the system components are stand-alone services. Standard protocols have been designed to support service communication and information exchange. This gives way for platform and language independency. A web service defines data available from some organization and how it can be accessed. More generally, it is a standard representation for some computational or information resource that can be used by other programs.
From the start, SOA services have had clear standards that the providers have committed to using. A lot of them are based on XML.
Key standards:
- SOAP: Simple object access protocol (Wikipedia), a message interchange standard that supports communication between services. Defines essential and optional components of messages passed between services.
- WSDL: Web Service Definition Language. A standard for service interface definition. Sets out how the service operations (operation names, parameters, and their types) and service bindings should be be fined.
- WS-BPEL: A standard for a workflow language that is used to define process programs involving several different services.
Some supporting standards that have been designed to support SOA in enterprise applications:
- WS-Reliable messaging: Ensures messages will be delivered once and once only.
- WS-Security: Set of standards that supports web service security, among them definition of security policies and the use of digital signatures.
- WS-Addressing: Defines how address information should be represented in a SOAP message.
- WS-Transactions: Defines how transactions across distributed services should be coordinated.
Web service standards will not be discussed in detail.
A main criticism of these standards is that they are heavyweight: Too general and inefficient. The use of XML for messaging introduces a lot of overhead. Some organizations, Amazon among them, use a simpler more efficient approach to service communication using RESTful services.
The main advantages of SOA is that organizations can cooperate more easily. The architectures are loosely coupled: The service bindings can change without notice – which means different, equivalent versions of the service may be executed at different times.
Services as reusable components
Services are the next step in the evolution of component based engineering. A possible definition of a service:
A [service is a] loosely-coupled, reusable software component that encapsulates discrete functionality, which may be distributed and programmatically accessed. A web service is a service that is accessed using standard Internet and XML-based protocols.
An important distinction between a service and a component is that it should operate independently from its environment; it only has a "provides" interface and no "requires" interface. The communication is entirely message-based – no remote procedure calls.
Before communicating with a service, one needs to know its location (URI) and the details of its interface (described in WSDL). The WSDL specification defines:
- What: An interface specifies what operations the service supports and defines the format of the messages that are sent and received by the services.
- How: Called a binding. Maps the abstract interface to a concrete set of protocols – it specifies the technical details of how to communicate with a web service.
- Where: Describes the location of a specific web service implementation (its endpoint).
A WSDL conceptual model shows the elements of a service description; these are expressed in XML and may be provided in separate files. These parts are.
- An introductory part. Usually defines the XML namespaces used and may include a documentation section providing additional information about the service.
- An optional description of the types used in the messages exchanged by the service.
- A description of the service interface (the operations that the service provides).
- A description of the input and output messages processed by the service.
- A description of the binding used by the service (the messaging protocol). The default is SOAP. Sets out how the input and output messages should be packaged into a message and specifies the communication protocols used. The binding may also specify how supporting information, such as security credentials or transaction identifiers, is included.
- An endpoint specification. The physical location of the service, specified as an URI – the address of a resource that can be accessed over the Internet.
Service engineering
The process of developing services for reuse in service-oriented applications. Has much in common with component engineering: The services have to be a reusable abstraction with a good documentation which makes its services clear to potential users.
Three stages in the process:
- Service candidate identification: Identify possible services that might be implemented and define the service requirements.
- Service design: Design the logical and WSDL interfaces.
- Service implementation and deployment: Implement and test the service. Then make it available for use.
Service candidate identification
Service-oriented computing is usually done to support business processes.
Fundamental types of services:
- Utility services: Services that implement some general functionality, which may be used by many different processes. E.g. currency conversion.
- Business services: Services associated with a specific business functions, such as student registrations for a course.
- Coordination or process services: Support a more general business process which usually involves different actors and activities. This might be an ordering service keeping track of stock, suppliers and payments.
You might also split them into the categories entity-oriented (concerned with one entity, such as a job application form) or task-oriented (concerned with some activity).
Although there is no single formula for making a service, there are some questions you may ask to identify potentially reusable services:
- For an entity-oriented service: Is there a single logical entity that is used in different business processes that this service can be made for? What operations are normally performed on that entity, and which of them will you support?
- For a task-oriented service: Is the task carried out by different people in the organization? Will they accept that they have to begin conforming to a process set out by the service?
- Is the service independent? I.e. does it rely on other services?
- Does the service have to maintain state? Services are stateless, and if a state is required, you also need a database – which is possible, but a hassle. In general, it is easier to reuse a service if the state is passed to it, not contained in it.
- Could the service be used by clients outside of the organization?
- Are different users of the service likely to have different non-functional requirements? If so, perhaps you should implement more than one version of the service.
Service interface design
Once you have selected services, you move into designing the service interfaces. This defines the operations associated with the service and their parameters. The aim is to minimize the number of message exchanges that must take place to complete requests – as much information as possible must be passed in each message.
The three stages of the service interface design:
- Logical interface design: Define operations along with their associated inputs, outputs and exceptions.
- Start with the service requirements and define the operations from them.
- Make exceptions for incorrect outputs. Users will probably not have understood your specification completely.
- Leave the error handling completely to the users of the service.
- Message design: Design the structure of the messages sent and received.
- Don’t use XML at this stage. Defining objects in UML is better.
- WSDL development: Translate your logical and message design to an abstract interface description written in WSDL.
- Some IDEs, such as Eclipse, have tools that can translate a logical interface description to WSDL automatically.
Service implementation and deployment
The final stage of the service engineering process. You may either program the service in a programming language or implement service interfaces to legacy systems: Many organizations rely on old systems that are practically impossible to replace. An important application of service engineering is to create wrappers for legacy systems, so that they can be accessed via the Web.
After this is done, you have to test the service the way you would with a normal component.
Once the service is ready for deployment, deploying should be no harder than installing it in a specific directory on a web server. The users will probably like having a service description, which can include the following:
- Business and contact details, etc: This makes users trust the service.
- An informal description of the functionality: Helps users decide if its the service they want.
- A detailed description of the interface types and semantics.
- Subscription information: Allows users to register for information about updates to the service.
Software development with services
Service composition is the process of integrating separate business processes to provide more functionality. For instance, when booking a flight, the airline might also give you the option of booking a hotel or renting a car. If you choose to do so, the airline will pass along information about your flight to the hotel booking service. Such a flow of information is called a workflow. The workflow should be able to compensate for errors in connected services (going back in case the information in the next step changes the user’s mind, renders the previous action invalid, etc.). An action which is used to undo actions that have already been completed, but must be changed as a result of later workflow activities, is called a compensation action.
The six key stages in the process of service construction by composition:
- Formulate outline workflow: Use the requirements for the composite service to create an ideal service design. This should be very abstract – add details later.
- Discover services: Search service registries to discover existing services, their providers and the details associated with using them.
- Select possible services: See who can implement your workflow activities. The main criterium is functionality, but also keep cost and quality of service in mind.
- Refine workflow: Refine it based on the services selected. (You might need to repeat steps 2 and 3 to refine the design).
- Create workflow program: Transform the design to an executable program and define the service interface. You may also create a web-based user interface.
- Test completed service or application: This process is more complicated than usual testing. This will be discussed below.
Workflow design and implementation
This involves analyzing existing or planned business processes to understand the different activities that go on and how to exchange information. Define the new business process in a workflow design notation. The two most common ways are UML activity diagrams and Business Process Modeling Notation (BPMN) (Wikipedia). The latter is best, because mappings to low-level XML exist. Visually it resembles a normal flowchart.
As mentioned, the initial business process model must be refined based on available services and your understanding of the process. After refining, it will be converted to an executable program. This may involve:
- Implementing the services that haven’t been found as reusable services.
- Generating an executable version of the workflow model. There are automatic tools for this, but some models may require hand coding to generate readable code.
Service testing
Testing is, as always, important. In service-based system testing, having access to the source code of the services is rare, and so looking directly at the code is not an option.
Some other difficulties:
- External services are under the control of the service provider. They are not necessarily available at the time of and changes may happen to them after you have integrated them.
- The long-term vision of SOAs is for services to be bound dynamically to service-oriented applications. Or, simpler: The application doesn’t necessarily use the same service every time. Thus, a successful test using one service doesn’t mean the test will be successful when using another service.
- The non-functional behavior is dependent on the services that are being used. When the application is deployed, conditions, such as the load on external services, may have changed.
- The payment model for services could make testing very expensive.
- A free service doesn’t want its servers bombed with your tests.
- A subscription service costs money to subscribe to, money you don't want to spend you if you aren’t yet ready to deploy your application.
- A pay-per-use service could be very expensive if you run extensive tests.
- Compensation actions are hard to test if the services you rely on don’t fail.
Chapter 22: Project management
Some important goals in project management.
- Delivering the software at agreed time.
- Keeping within budget.
- Assure that software meets customer expectations.
- Keep the development team happy and well functioning.
Some differences from ordinary engineering:
- The product is intangible; opposed to a building or a ship, you cannot see or touch software.
- A software project is usually different from older projects: If the problem was solved, you wouldn't be making a new solution. New technology renders old solutions obsolete.
- Software processes vary from organization to organization and are not as standardized as other engineering processes.
Some tasks a project manager may do:
- Project planning
- Reporting
- Risk management
- People management
- Proposal writing
Risk management
A risk is something you'd prefer not to happen. Risk managing is anticipating the risks that may affect the schedule or quality of the project and taking action to avoid them. The following sections are the stages of risk management.
Risk identification
Identify the risks and place them in one or more of the following categories of risk, according to what they affect:
| Project risks | Affect the project schedule or resources. E.g: An experienced programmer quits. |
| Product risks | Affect the quality of performance of the software being developed. E.g: A purchased component doesn't work as expected. |
| Business risks | Affects the organization developing or combining software. E.g: Your main competitor just released a cheaper and better product. |
As well as this, you may want to find out what type of risk it is; what causes it:
| Technology risks | Come from the software or hardware technologies used. Perhaps the database cannot handle the number of queries required. |
| People risks | Associated with the development team. For example, key staff members are ill. |
| Organizational risks | Stems from the organizational environment, such as a restructuring that might lead to the managers being switched out. |
| Tools risks | The tools you develop with don't work as expected. |
| Requirements risk | Changes in the requirements |
| Estimation risks | Wrong estimates. |
Risk analysis
Estimate the likelihood and consequences of the risk.
Probability
| Very low | < 10% |
| Low | 10-25% |
| Moderate | 25-50% |
| High | 50-75% |
| Very high | > 75% |
Effects
| Catastrophic | Threatens the survival of the project. |
| Serious | Would cause major delays. |
| Tolerable | Delays are within the acceptable |
| Insignificant | "Pfft…" |
When you are done with these two first stages, you might want to list all risks as well as your assessment of probability and effect in a table.
Risk planning
Plan to address the risks. The strategies fall within these categories:
| Avoidance | The probability of the risk occuring is reduced |
| Minimization | The impact of the risk is reduced. |
| Contingency plans | "Houston, we have a problem" – what you do when the worst occurs. |
Risk monitoring
You should monitor risks regularly and update your plans. When there are indicators that risk has become reality, try to put the plans into action as soon as possible.
People management
 "Hey, what are the odds -- five Ayn Rand fans on the same train! Must be going to a convention." (xkcd 610: Sheeple, CC-BY-NC 2.5 Randall Munroe)
"Hey, what are the odds -- five Ayn Rand fans on the same train! Must be going to a convention." (xkcd 610: Sheeple, CC-BY-NC 2.5 Randall Munroe)
People are the most important factor in software development. Many software people are great with technology, but not with people. If this description fits you, this section might help you a bit along the way, but we recommend you also try to practice what you read.
The critical factors when you manage people:
| Consistency | Team members should feel that they are being treated in a comparable way. |
| Respect | Respect the different skills and personalities of team members. If someone "just doesn't fit in", you're probably doing a bad job; try to find a way for them to contribute. |
| Inclusion | People contribute more when they feel they are being listened to. Be open to proposals from junior staff. |
| Honesty | Be honest about what is going well and not as well as your own knowledge. Never lie; the trust of your team members is alpha and omega. |
Motivating people.
People have different needs you have to pay attention to. These can be found in Maslow's hierarchy of needs.

(Maslow's Hierarchy of Needs, CC-BY-SA 3.0 J. Finklestein)
{kind=link}
You will probably not have to worry about the lower levels, unless your company has a serious lack of toilets or is currently at war with some totalitarian regime. Some ways to nourish the higher levels:
- Love/belonging: Provide places and times for co-workers to meet. If people are not in the same place, consider teleconferencing and meet-ups.
- Esteem: Show people that they are valued by the organization. Public recognition of their work is most important, but pay can be an issue.
- Self-actualization: Give people responsibility for their work and give them demanding, but not impossible tasks.
The problem with the pyramid is it only sees people as a collection of their individual needs: It is important to remember that people are also motivated by the success and well-being of their group as a whole.
According to Bass and Dunteman, there are three types of personalities in the professional environment:
- Task-oriented: Motivated by the work they do; do the work for the intellectual challenge.
- Self-oriented: Motivated by personal success and recognition. Interested in sofware development as a means of achieving their long-term goals (e.g. career). Not necessarily equivalent to selfish.
- Interaction-oriented: Motivated by the prescence and actions of co-workers.
The latter prefers group work and are more effective communicators. The two first prefer individual work. Women are overrepresented in the last group. People may change category over time.
Teamwork

Most software is developed in teams (from two to several hundred people) which are usually split into groups (should not exceed 10 members). It is important to have a balance of technical skills, experience and personalities in a group.
Try to get team members to socialize and build an identity, as well as building trust and good sharing habits. A cohesive group shares knowledge and supports each other. They often establish a high quality standard for their work which is easy to reach because they aren't afraid of refactoring their code.
We will now discuss some factors that affect the team work.
Selecting group members
You need a mix of personalities in the group (if this can't be achieved, more management is needed during the process). Here are some attributes of the different personalities previously discussed.
- Task-oriented: Most technical, but might follow their own intentions rather than orders.
- Self-oriented: Push the work forward to finish the job.
- Interaction-oriented: Detect tensions and disagreements at an early stage and does something about them.
Try to avoid part-time members; this harms team spirit.
Group organization
An informal structure might be well suited for smaller groups with more experienced programmers. If either of these are lacking, you should consider a more formal structure.
Hierarchical structures (with more important members on top) are well suited for problems that can be easily broken down (which is, quite ironically, no piece of cake). The problem with these structures is that communication doesn't flow horizontally, but only up and down the pyramid, which harms team spirit and exchange of ideas.
Some important questions for any group:
- Who will be the technical leader of the group? THe project manager, or some senior engineer?
- Who will be involved in making technical decisions? Should one take them or a consensus be reached?
- How will interactions with external stakeholders and senior company management be handled? Often the project manager will do this, but a team member with good interaction skills can take the job.
- How can groups integrate people that are not on site?
- How can knowledge be shared across the group? It is good to share information, but avoid too much information, because this leads to people not paying attention.
Group communications
Efficient communication is essential to success. Some factors that affect communication:
- Group size: The number of face-to-face communication links is given by
$\frac{n*(n+1)}{2}$ . Keeping the group size small can have a positive impact. - Group structure: Informal group structures helps communication.
- Group organization:
- Same personality types may clash.
- Mixed-sex groups are better.
- Interaction-oriented people help facilitate communication.
- Physical work environment: The organization of the workplace.
- Available communication channels: Distributed projects are dependent on communication technology.
The best modes of communication are two-way-communication (face-to-face, instant messaging) and collaborative communications.
As a rule of thumb, avoid meetings. You might think they are effective, but they're not. Most probably, you're giving people information they don't need (and in the rare case that you give people information they need, they're not paying attention). You're wasting their time, and probably your own money. (You can simulate the costs on your Android or iPhone).
Chapter 23: Project planning
Project planning is usually the responsibility of the project manager. It consists of work breakdown and assignment as well as risk management.
Planning takes place at three stages in a project life cycle:
- Proposal stage: You are bidding for a contract to develop or provide a system. See Software pricing for the process.
- Project startup phase: Who will work on the project, how will it be broken into increments, how to allocate resources etc., as well as refining the estimates from step 1. This phase is not very detailed in agile approaches. Define monitoring mechanisms to asess progress.
- Periodically: You modify your plan in light of experience and monitoring information, as well as when requirements change.
Software pricing
When making your initial estimate, add up:
- Effort cost (paying programmers)
- Hardware and software costs (including maintenance)
- Travel and training costs
- Profit
And you've got yourself a price estimate. However, you aren't stoopid; you factor in some other stuff:
- Market opportunity: This project gives your company the opportunity to try out a new market segment; a lower profit now might pay off later.
- Cost estimate uncertainty: If unsure about your estimate, it is better to add a little extra.
- Contractual terms: You may get to retain the ownership of your source code and software after making the software. If you don't think this is important, you can call Bill Gates' bank account and ask how it feels.
- Requirements volatility: If requirements are likely to change, you may lower your price to win the contract. When the requirements change, you can charge for that.
- Financial health: When in financial difficulty, you may lower your price to gain a contract. It's better to have a little of something than all of nothing.
There is a tactic called pricing to win, which is setting the price according to what you think customer wants to pay. This might be okay, on the condition the customer is expecting the price to rise after you enter negotiations. Use this with caution.
Plan-driven development
In plan-driven development, the planning process centers around the project plan. A project plan keeps track of the resources available, the work breakdown and a schedule. It should also contain risks and risk management.
The plan normally contains the following sections:
- Introduction: A brief description of the objectives of the project and the constraints that affect it.
- Project organization: The way the development team is organized, the people involved, and their roles in the team.
- Risk analysis
- Hardware and software requirements: The hardware and software necessary to carry out the development.
- Work breakdown: The project broken down into activities and milestones (stages where progress can be assessed) and deliverables (products that can be delivered to the customer) associated with each activity.
- Project schedule: Shows the dependencies between activities, estimated time required to reach each milestone, and the allocation of people to activities.
- Monitoring and reporting mechanisms: Defines the management reports that should be produced and when, as well as what project monitoring mechanisms will be used.
Some possible supplements:
- Quality plan: The quality procedures and standards that will be used in a project.
- Validation plan: Describe the approach, resources, and schedule used for system validation.
- Configuration management plan: Describes the configuration management procedures and structures to be used.
- Maintenance plan: Predicts the maintenance requirements, costs and effort.
- Staff development plan: Describes how the skills and experience of the project team will be developed.
The planning process is iterative: The initial plan is developed in stages, and it is necessary to revise it during development (probably as often as every 2-3 works).
Project scheduling
Deciding how the work will be organized as separate tasks, and when they will be executed. This is needed both in agile and plan-driven development, but the former doesn't need as much detailed.
Tasks should ideally take about one week to finish (finer division means you'll have to update too often), and no longer than two months. A project activity should contain:
- Duration: Its estimated duration in real life time.
- Effort estimate: The number of person-days or person-months required.
- Deadline: The point in time by which it must be completed.
- Endpoint: A tangible result of completing the activity (successful tests, a document, review meeting etc.)
You should also map the dependencies of a task (what tasks have to be finished before this works).
The schedule can be represented by either bar charts (a Gantt chart) or an activity network.
Agile planning
Scrum and Extreme Programming (XP) have a two-stage approach to planning:
- Release planning: Looks several months ahead and decides on the features that should be included in a release of the system.
- Iteration planning: Has a shorter outlook (typically 2-4 weeks) and focuses on planning the next increment.
Scrum is discussed in Chapter 3, so we only discuss XP here.
The XP release planning consists of the planning game, which takes place before the project starts:
- System specification: Based on user stories.
- Estimation stage: The team reads and discusses the stories and rank them in order of the amount of time they estimate they will take to implement.
- After ranking, they are given effort points according to how hard they seem.
- The effort points are converted into work hours, given by the team's estimation of their own velocity (number of points completed per day).
- Release planning: Selecting and refining the stories that will reflect the features to be implemented in a release of a system and the order in which the stories should be implemented. (Must involve the customer).
In each iteration:
- Iteration planning: Stories to be developed in this iteration are selected.
- Task breakdown: Break the stories into develpoment tasks that should be between 4 and 16 hours.
- Task selection: Each developer selects tasks that they should complete based on interests. This is limited by the individual velocity. The benefits of this are:
- The whole team gets an overview of the tasks in each iteration.
- The developers get a sens of ownership in the tasks.
- Implementation: Go out and code.
- Recalculate velocity: Based on the number of points completed in this iteration, calculate the velocity of the team and use this as a basis for future iterations.
Estimation techniques
Schedule estimation is no exact science. Research has shown that the initial estimate is usually between a quarter and four times of the actual cost and time of a project (a huge variance). There are two types of estimation techniques:
- Experience based: Based on the manager's previous experience. Its major disadvantage is that no software project is like any previous, and thus you can never be certain.
- Algorithmic cost modeling: A formula is used to compute the project effort based on estimates of project attributes and process characteristics. This is not perfect either, because you're still estimating – only smaller things.
Estimates have a tendency to be self-fulfilling: People work harder when their budgets are tighter. This might come at the expense of quality.
Algorithmic cost modeling
 "But seriously, there's loads of intelligent life. It's just not screaming constantly in all directions on the handful of frequencies we search." (xkcd 384: The Drake equation, CC-BY-NC 2.5 Randall Munroe)
"But seriously, there's loads of intelligent life. It's just not screaming constantly in all directions on the handful of frequencies we search." (xkcd 384: The Drake equation, CC-BY-NC 2.5 Randall Munroe)
The basic formula for algorithmic cost estimation is as follows:
$A$ is a constant factor which depends on local organizational practices and the size of the software being developed.$Size$ is either an estimation of the size of the project (usually the lines of source codes) or application points.$B$ is a value between 1 and 1.5.$M$ is a multiplier made by combining process, product and development attributes.
If you don't understand a lot yet, don't worry. You'll be fed up with algorithmic cost estimation once you've read about …
The COCOMO II model
The COCOMO II model consists of several submodels that estimate effort, schedule and costs of a software project. We will go through them one by one, explaining their details and their different applications.
An application-composition model
An application-composition model models the effort required to prototype a system and to develop systems that are created from composing existing components. (Note that another formula is used when reusing software.)
The formula here is:
$PM$ is the effort estimate in person-months.$NAP$ is the total number of application points in the delivered system.- Application points are calculated from a number of factors (such as number of screens, reports, number of modules in imperative languages, lines of code, etc.)
$\%reuse$ is the percentage of reuse (i.e. 99%, not 0.99) in your application.$PROD$ is the application point productivity of the development team.
An early design model
An early design model is used during early stages of system design, after the requirements have been established, but before you have a detailed architectural design. It's most useful for comparing different ways of implementing the user requirements.
It's based on the basic formula, but the new thing is that it provides a detailed way to compute M. As well as this, the book notes that Boehm has found through research that
The different components of M are rated on a 1-6 scale, where 1 is very low and 6 is very high. What they mean:
| PERS | Personnel capability |
| RCPX | Product reliability and complexity |
| RUSE | Reuse required |
| PDIF | Platform difficulty |
| PREX | Personnel experience |
| FCIL | Support facilities |
| SCED | Schedule |
A reuse model
A reuse model is used to compute the effort required to integrate reusable components and/or automatically generated program code. It is normally used in conjuction with a post-architecture model.
When integrating automatically generated code, you use:
$PM_{auto}$ is the effort in person-months.$ASLOC$ is the total number of lines of reused code, including code that is automatically generated.$AT$ is the percentage of reused code that is automatically generated.$ATPROD$ is the productivity of engineers in integrating such code. Estimated to be about 2400 source statements per month.
When estimating the cost of integrating a reusable component, we simply use the standard formula, but compute a new estimate for size, called
More details to come
The post-architecture level
Project duration and staffing
As well as estimating overall costs, we must estimate how long the software will take to develop. COCOMO has (to the surprise of nobody) a formula for this as well:
$TDEV$ is the nominal project schedule in calendar months.$PM$ is the person month effort computer by the COCOMO model.$B$ is the complexity related exponent. See The post architecture level.
What this quite complicated formula, combined with the last section, shows, is that you can't simply throw people at a project to decrease months, because this increases the complexity of
Chapter 24: Quality management
With the first large software systems in the 1960s came the first quality problems. Ever since we have been concerned with software quality management. The larger a system is, the more important quality management is.
It has three principal concerns:
- At the organizational level: Establishing a framework of organizational processes and standards that will lead to high quality software. The quality management team should take responsibility for defining the software development processes and standards that apply to software and related documentation.
- At the project level (1): Application of specific quality processes, checking that these have been followed and ensuring that the project outputs are conformant with the standards that are applicable to that project.
- At the project level (2): Establishing a quality plan for a project. This sets quality goals for the project and define what processes and standards are to be used.
In the manufacturing industry, the terms ‘quality assurance’ and ‘quality control’ are widely used. Quality assurance refers to the definition of processes and standards that should lead to high-quality products, and quality control is the application of these quality processes. In the software industry, the application of the terms is not clearly defined. We will use the term quality assurance referring to the process of verification and validation, as well as checking that quality procedures have been properly applied. The other term is rarely used in the industry.
The QA team manages the release testing process, which is covered in chapter 8, and the process is referred to as ‘quality management’ (it seems, though it is not explained in the book). This testing process provides an independent check on the software development, and the team should thus be independent from the development team. Ideally, the quality assurance team should not be associated with any particular development group, but have an organization-wide responsibility. Their reports should be delivered to the management rather than project managers, because a project manager might be tempted to compromise quality because of budget and schedule and thus ignore reports.
Quality planning is the process of developing a quality plan for a project. This should set out the desired software qualities and how they should be assessed. In plan-driven development, the definition of ‘high quality’ should not be fuzzy. More room for interpretation is given in agile development.
Humphrey suggests an outline structure for a quality plan (which is a part of the project planning process) in his 1989 publication "Managing the Software process", including:
- Product introduction: A description of the product, intended market, and the quality expectations.
- Product plans: Critical release dates along with plans for distribution and product services.
- Process descriptions: The development and service processes and standards that should be used for product development and management.
- Quality goals: The quality goals and plans for the product, including an identification and justification of critical product quality attributes.
- Risks and risk management: The key risks that might affect product quality and the actions to be taken to address these risks.
Try to keep this as short as possible, so that everyone reads it. You should also keep in mind that standards will undoubtably lead to more bureaucracy.
Quality culture is also important; this is the developers’ commitment to achieving high product quality.
Software quality
In the manufacturing industry, quality means that a product meets its specification (within certain margins of tolerance). This is not possible to transfer directly to software, for several reasons:
- Software requirements specifications are never complete and unambiguous.
- Specifications are the compromises of requirements from several stakeholders. It is practically impossible to satisfy all stakeholders.
- It is impossible to measure certain quality characteristics, such as maintainability.
This requires judgment. You might want to consider these questions:
- Have programming and documentations standards been followed in the development process?
- Has the software been properly tested?
- Is the software sufficiently dependable to be put into use?
- Is the performance of the software acceptable for normal use?
- Is the software usable?
- Is the software well structured and understandable?
Software standards
Software standards are important for three reasons:
- They capture wisdom from previous experience that is of value to the organization.
- They provide a framework for defining what ‘quality’ means in a particular setting.
- They assist continuity by ensuring that all engineers adopt the same practices.
There are two related types of software engineering standards that may be defined:
- Product standards: Apply to the software product. Includes document standards and coding standards.
- Process standards: Define processes which encapsulate good development practice. May include processes for specification, design and validation, as well as process support tools and a description of the documents that result from these processes.
There are a number of bodies that define standards, such as the IEEE, ANSI and even defense organizations such as NATO. The latter might require that all software developed for the organization follows their standards.
People might like the idea of standards … as long as the standards implement what they have also done: Once other people's rules apply to them but often find them tedious and of little relevance. To minimize dissatisfaction, quality managers should:
- Involve software engineers in the selection of product standards: This increases satisfaction with them.
- Review and modify standards regularly to reflect changing technologies: Even though this costs a lot, the alternative might result in standards becoming outdated and never used.
- Provide software tools to support standards: Providing a simple Word document template for the required documents might go a long way in getting people to cooperate.
Standards aren’t the ten commandments: The project managers should be allowed to choose which standards apply to their project and also make appropriate adjustments – as long as this doesn’t compromise quality.
The ISO 9001 standards framework
The ISO 9000 standard applies to the development of quality management systems in all industries. The ISO 9001 is the most general, and applies to organizations that design, develop and maintain products – including software. It defines general quality principles and quality processes in general and lays out the organization standards and procedures that should be defined. The ones you document your specific implementations in an organizational quality manual.
The standards are oriented around nine core processes:
- Product delivery processes
- Business acquisition
- Design and development
- Testing
- Production and delivery
- Service and support
- Supporting processes
- Business management
- Supplier management
- Inventory management
- Configuration management
To conform to ISO 9001, your company must have defined the types of processes and have procedures that demonstrate that its quality processes are being followed.
Customers might require that your company is ISO 9001 certified, which makes them more confident that you have an approved quality management system in place. However, this isn’t a universal "Perfect stamp"; the standard only concerns quality control and is not very much concerned with your development practices and the quality of the software you deliver.
It is hard for an agile process to follow the ISO 9001 standard, and agile developers consider it bureaucratic.
Reviews and inspections
These are QA activities that check the quality of what your project delivers.
Inspection is when a team of inspectors examine the software. It then then makes informed judgments about the level of quality of a system or project deliverable and delivers this to the project managers.
Quality reviews is when a team reviews your project's documentation and records of the process to discover errors and omissions and to see if quality standards have been followed. The results should be formally recorded. Problems should be passed on to the people in charge.
A quality review is not the same as a progress review – the latter is concerned about whether the product delivered is keeping its schedule and budget, while the former is concerned with the quality of what is actually there.
When errors are found, keep the ‘finger-pointing’ behavior at a minimum; the project manager should establish a good culture for responding to errors.
The review process
There are many variations, but the review process is generally structured into three phases:
- Pre-review activities: Setting up a review team, arranging a time and place, distributing documents to be reviewed. Team members prepare themselves for the meeting by reading through the supplied materials and making notes.
- The review meeting: Should be short – two hours at most. The author of the document or program should walk through the document with the review team. A team member chairs the review and another records all review decisions.
- Post-review activities: The issues and problems raised during the review must be addressed by the development team. Sometimes a management review is also deemed necessary; the project may require more resources. After some time, the chair checks if the changes have been made.
The review process is far less formal in agile methods, partially because they adhere to standards as little as possible.
Program inspections
Program inspections are peer reviews where team members collaborate to find bugs in the program that is being developed. The system does not have to be complete. Usually, this involves expecting the program at source code level according to a checklist. Languages have their own characteristic errors, and the checklist should be adapted to this as well as your organization’s experiences and standards.
An inspection generally reveals a higher number of errors than unit testing, but the process is of course more costly. Agile methods rarely use inspections, but instead have as a principle that members should check code before checking in. Pair-programming is a technique leads to continuous checking.
24.4 is yet to come …
Chapter 25: Configuration management
Systems always change to cope with bugs and introduce new features. A new version is created when changes are made to the system. Configuration management (CM) is the policies, processes, and tools for managing changing systems. It involves four closely related activities:
- Change management: Keeping track of requests for changes to the software from customers and developers, working out the costs and impact of making these changes, and deciding if and when the changes should be implemented.
- Version management: Keeping track of the multiple versions of system components and ensuring that changes made to components by different developers do not interfere with each other.
- System building: Assembling the program components, data, and libraries, and then compiling and linking these to create an executable system.
- Release management: Preparing software for external release and keeping track of the system versions that have been released for customer use.
Often, the CM and quality management tasks are at the hand of the same manager.
CM terminology differs between organizations; this has historical reasons. The CM terminology used in the book:
- Configuration item or software configuration item (SCI): Anything associated with a project that has been placed under configuration control. Often different versions of a configuration item. They have a unique name.
- Configuration control: Ensuring that versions of systems and components are recorded and maintained so that changes are managed and all versions of components are identified and stored for the lifetime of the system.
- Version: An instance of an item that differs from other instances of that item. Has a unique identifier: Component name and version number.
- Baseline: Collection of component versions that make up one version of a system. No components can be replaced with other components and new versions.
- Codeline: A set of versions of a software component and other configuration items on which that component depends.
- Mainline: A sequence of baselines representing different versions of a system.
- Release: A version of a system that has been released to customers for use.
- Workspace: A private work area where software can be modified without affecting other developers.
- Branching: Creation of a new codeline from a version in an existing codeline.
- Merging: Creation of a new version of a software component by merging separate versions in different code lines.
- System building: The creation of an executable system version by compiling and linking the appropriate versions of the components and libraries making up the system.
Change management
Change management is intended to ensure that the evolution of the system is a managed process and to prioritize changes. You analyze costs and benefits, approve changes and track what components have been changed.
The process usually starts with a customer submitting a change request through a form. The request is then checked for validity (has this been fixed or implemented already; has the user misunderstood?). If it’s valid, its costs are analyzed. The change request is then usually passed on to the change control board (CCB) if it’s not minor. They consider the impact of the change from a strategic and organizational standpoint (not technical), and if it’s accepted, it’s passed on.
Important factors in deciding whether or not to approve a change request and how to prioritize it:
- The consequences of not making the change: Is the error major or minor?
- The benefits of the change: Will this benefit many users?
- The number of users affected by the change: If only a few users are affected, it is given low priority – fixing the change may lead to problems for even more users.
- The costs of making the change.
- The product release cycle: If a new version of the software has just been released, it may make sense to delay the implementation of the change until the next planned release.
In some agile methods, customers are directly involved in deciding whether a change should be implemented.
Version management
The process of keeping track of different versions of software components or configuration items and the systems in which these components are used – think of it as managing codelines and baselines. This is often done with version management tools, which provide features like:
- Version and release identification.
- Storage management: To save space, the version management tools often only store the differences between versions (deltas).
- Change history recording: All of the changes made to the code or components are recorded and listed.
- Independent development: Different developers can work at the same code at the same time. A check out means you’re working on a certain file; this will usually warn others that check out the same component.
- Project support: The version management system may support the development of several projects sharing the same components.
System building
The process of creating a complete, executable system by compiling and linking the system components, external libraries, configuration files etc. The tool used for this must usually communicate with the version management tools. Building is a complex process, and errors are likely to show up because three different system platforms can be involved:
- The development system: The development tools: compilers, source code editors, etc.
- The build server: Used to build definitive executable versions of the system. May rely on libraries that are not included in the version management system.
- The target environment: The platform on which the system executes. It is often not possible to build and execute the system on the same computer/build server.
This process is usually automated, but the source code often has to be linked to external libraries and data files beforehand – sometimes manually.
A build system may provide some or all of the following features:
- Build script generation: The build system should analyze the program being built, identify dependent components, and automatically generate a build script – as well as support manual configuration of build scripts.
- Version management system integration: It should interface with the VM system.
- Minimal recompilation: The system should not compile code that doesn’t need to be recompiled.
- Executable system creation: It should link the compiled object code files with each other to create the executable system.
- Test automation: The system can run unit tests to see if the build has not been broken by changes.
- Reporting: It should report about whether the build and tests have been successful.
- Documentation generation: The system may be able to generate release notes about the build and system help pages.
To keep track of when objects have to be recompiled, the compiler associates a unique signature with each file where a source code component is stored. If signatures match, there is no need to recompile. Two possible signature types:
- Modification timestamps: Simply a time stamp of when the file was modified. The disadvantage is that it is impossible to keep track of several versions at the same time, because you only have one timestamp in the file and the compiled version.
- Source code checksums: A checksum is calculated for the source file and is placed into the file before compilation and into the compiled file. Can keep track of several versions of the compiled code at the same time.
Continuous integration
Agile methods recommend very frequent system builds to discover software problems; this might be part of a process of continuous integration. The steps in these processes are:
- Check out the mainline system from the version management system into the developer’s private workspace.
- Build the system and run automated tests to ensure that the built system passes all tests. If not, the build is broken and you should inform whoever checked in the last baseline system. They are responsible for repairing the problem.
- Make the changes to the system components.
- Build the system in the private workspace and rerun system tests. If the tests fail, continue editing.
- Once the system has passed its tests, check it into the build system, but do not commit it as a new system baseline.
- Build the system on the build server and run tests. You need to do this in case others have modified components since you checked out the system. If this is the case, check out the components that have failed and edit these so that tests pass on your private workspace.
- If the system passes its tests on the build system, then commit the changes you have made as a new baseline in the system mainline.
This process has been invented to ensure that problems caused by the interactions between developers are discovered and repair as soon as possible. It is not always possible to use this approach because:
- If the system is very large, it may take a long time to build it.
- If the development platform is different from the target platform, it might not be possible to run tests on the developer workspace.
In these cases, you might use daily build:
- The development organization sets a delivery time for system components. All components must be delivered by that time – even if incomplete, so that its limited functionality can be tested.
- A new version of the system is built from these components by compiling and linking them to form a complete system.
- The system is delivered to the testing team. The development team is working in parallel on the system.
- Faults that are discovered during system testing are documented and returned to the development team.
The advantage of this is discovering errors early as well as developers being more aware of writing software that doesn’t break the system.
Release management
A release is a version that is distributed to customers. Managing the releases is a complex process. A release needs documentation: All of the involved files and software should be noted and backed up in case they are needed in the future.
The release may include (in addition to executable code):
- Configuration files defining how the release should be configured for particular installations.
- Data files, such as files of error messages, that are needed for successful system operation
- An installation program.
- Electronic and paper documentation.
- Packaging and associated publicity designed for that release.
You must take into account that people wanting to install your latest release may not necessarily have installed the most recent version, so you shouldn't rely on files from an intermediate version.
Factors influencing release planning:
- Technical quality of the system: You should not release a system with major faults. Minor faults can be fixed with patches.
- Platform changes: A new version of the users' operating system may demand a new release.
- Lehman’s fifth law: If you introduce a lot of new functionality, there’s also bugs.
- Competition: If competitors have introduced new features, you may have to follow up.
- Marketing requirements: If the marketing department has set a release date, you might have to release no matter what.
- Customer change proposals: If customers have paid for changes, they expect them as soon as they’re implemented.
Chapter 26: Process improvement
As with project management, a good process will not guarantee success, but the lack of one will almost certainly mean failure. In fact, the larger the project is the more the process has to say for the outcome, more than any other factor. Therefore, large corporations spend a lot of money to continously improve theirs processes.
Process Characteristics
- Understandability
- Standardization
- Visibility
- Measurability
- Supportability
- Acceptability
- Reliability
- Robustness
- Maintainability
- Rapidity