MA0301: Elementary Discrete Mathematics
This study guide is primarily based on the textbook Discrete and Combinatorial Mathematics: An Applied Introduction, 5th ed. by Ralph Grimaldi.
Another source of the 5th edition is here, and the third edition is available here. The instructor's manual with solutions to all the problems in the textbook can be found here. (If the links break at some point, some of the PDFs can be retrieved from the Internet Archive by pasting the links in their Wayback Machine search engine.)
Denne engelske-norske ordlisten kan være nyttig.
General Remarks
Short on time? Overwhelmed? Here are some suggestions for covering the basics which often pop up in exams:
- Learn how to work with and simplify logical expressions, set expressions and boolean algebra expressions, using the laws listed in this guide. (When it comes to the operators, all three are pretty much the same thing, just with different symbols.)
- Learn to write the basic structure of a proof using the principle of mathematical induction.
- Learn the definitions of an equivalence relation and a partial ordering relation.
- Learn the definitions of surjective, injective and bijective functions.
- Learn the definitions of a directed graph, undirected graph and a tree.
- Learn the difference between a permutation and combination, and how to calculate the numbers of each.
- Learn how to draw a state diagram.
Good luck!
Logic
Sections 2.1–2.5 in Grimaldi.
Terminology and Notation
- Statement (or proposition)
- A declarative sentence that is either true or false, but not both. Statements are typically denoted with the lowercase letters
$p$ ,$q$ ,$r$ ,$s$ ,$t$ . - Primitive statement
- A statement which cannot be broken down to simpler statements.
- Truth value
- A value which is either true or false, but not both. Denoted either in plain text as true and false, with single letters "T" and "F", or as binary integers "1" (true) and "0" (false).
- Negation
- A transformation of a statement to its opposite truth value. The negation of the statement
$p$ is denoted$\neg p$ . - Compound statement
- A combination of two or more statements using logical connectives.
- Tautology
- A compound statement is a tautology if it is true for all truth value assignments.
- Contradiction
- A compound statement is a contradiction if it is false for all truth value assignments.
- Argument
- An argument consists of two parts: a series of statements, called premises, and a single statement, called the conclusion. An argument can be either valid or invalid, but not both.
Examples of statements:
Logical Connectives
- Conjunction
- The conjunction of the statements
$p$ ,$q$ is denoted by$p \land q$ , which is read "$p$ and$q$ ". The conjunction of two statements is true only when both statements are true, and false otherwise. - Disjunction
- The disjunction of the statements
$p$ ,$q$ is denoted by$p \lor q$ , which is read "$p$ or$q$ ". The disjunction of two statements is true if one or both statements are true, and false otherwise. - Exclusive "or"
- The exclusive "or" is denoted by
$p \veebar q$ or$p \oplus q$ . The compound statement$p \veebar q$ is true if either$p$ or$q$ is true, but is false if both are true. - Implication
- The implication of
$q$ by$p$ is written$p \rightarrow q$ , and we say that "$p$ implies$q$ ". In the compound statement$p \rightarrow q$ ,$p$ is called the hypothesis of the implication and$q$ is called the conclusion. Note: An implication does not signify any causal relationship between the statements. "$p$ implies$q$ " is true when both$p$ and$q$ are true, is false when$p$ is true and$q$ is false, and is true when$p$ is false, regardless of the truth value of$q$ ("with a false hypothesis, anything can be proved to be true"). See table 1 for clarification. - Biconditional
- The biconditional of two statements
$p$ ,$q$ is denoted by$p \leftrightarrow q$ , which is read "$p$ if and only if$q$ " (often abbreviated "$p$ iff$q$ "), or "$p$ is necessary and sufficient for$q$ ". The compound statement$p \leftrightarrow q$ is true if$p$ and$q$ have equal truth values. - Dual of a statement
- If a statement
$s$ contains no logical connectives other than$\land$ and$\lor$ (i.e. no implication, biconditional, exclusive "or"), then the dual of$s$ , denoted$s^d$ , is the statement obtained from$s$ by replacing each occurrence of$\land$ by$\lor$ and vice versa, and replacing each occurence of$T_0$ by$F_0$ and vice versa. Note that since$\neg$ is not a logical connective,$\neg p \equiv (\neg p)^d$ . - Principle of duality
- Let
$s$ and$t$ be statements that contain no logical connectives other than$\land$ and$\lor$ . If$s \equiv t$ , then$s^d \equiv t^d$ . In other words, if two statements are equivalent, then their duals are also equivalent.
Other ways to express "
- "If
$p$ , then$q$ " - "
$p$ is sufficient for$q$ " - "
$q$ is necessary for$p$ " - "
$p$ only if$q$ "
Precedence Rules
Just as in regular arithmetic, where the operator for multiplication (and division) has a higher order of precendence than the operator for addition (and subtraction), the logical operators have the following order of precendence:
$\neg$ $\land$ $\lor$ $\rightarrow$ $\leftrightarrow$
Thus, the expression
Truth Tables
The truth value of a compound statement depends only on the truth values of its components. The above definitions can be summarized by the following truth table (table 1). Note how
| 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
Using truth tables you can prove theese two theorems:



The Laws of Logic
Two statements
The following table lists the laws for the algebra of propositions, or "The Laws of Logic", for any primitive statements
| Law | Symbolic Form |
| Law of Double Negation | |
| DeMorgan's Laws | |
| Commutative Laws | |
| Associative Laws | |
| Distributive Laws | |
| Idempotent Laws | |
| Identity Laws | |
| Inverse Laws | |
| Domination Laws | |
| Absorption Laws |
Contrapositive, Converse and Inverse
The implication
- Contrapositive
$\neg q \rightarrow \neg p$ is the contrapositive of$p \rightarrow q$ . The contrapositive of an implication is generated by negating both sides and having the hypothesis and the conclusion change places.- Converse
$q \rightarrow p$ is the converse of$p \rightarrow q$ . The converse of an implication is generated by having the hypothesis and conclusion change places. (Think "converse = reverse", as in reversing the direction of the arrow.)- Inverse
$\neg p \rightarrow \neg q$ is the inverse of$p \rightarrow q$ . The inverse of an implication is generated by negating both the hypothesis and conclusion, but they do not change places.
Note: It is only the contrapositive which is equivalent to the original implication. That is,
This can be observed in the following truth table.
| Contrapositive | Converse | Inverse | |||
| 1 | 0 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 |
| 0 | 1 | 1 | 1 | 0 | 0 |
| 0 | 0 | 1 | 1 | 1 | 1 |
Logical Implication
If
The Rules of Inference
The three dots
| Name of Rule | Rule of Inference | Related Logical Implication |
| Rule of Detachment | ||
| Law of the Syllogism | ||
| Modus Tollens | ||
| Rule of Conjunction | ||
| Rule of Disjunctive Syllogism | ||
| Rule of Contradiction | ||
| Rule of Conjunctive Simplification | ||
| Rule of Disjunctive Amplification | ||
| Rule of Conditional Proof | ||
| Rule for Proof by Cases | ||
| Rule of the Constructive Dilemma | ||
| Rule of the Destructive Dilemma | ||
| Resolution |
Validity of Arguments
An argument, i.e. a series of one or more premises followed by a conclusion, can be valid or invalid. The truth values of the primitive statements the premises and the conclusion are comprised of determine the argument's validity.
To show that an argument is invalid, we only need one assignment of truth values for each of the statements in the argument such that the conclusion is false, while the premises are all true. Thus, only one case is needed to disprove an argument's validity.
To prove that an implication of the form
Open Statements
A declarative sentence is a open statement if
- it contains one or more variables (e.g.
$x$ ), and - it is not a statement, but
- it becomes a statement when the variables in it are replaced by certain allowable choices.
These allowable choices constitute what is called the universe or universe of discourse for the open statement. The universe comprises the choices we wish to consider or allow for the variable(s) in the open statement.
An example of an open statement with a single variable:
An example of an open statement with two variables:
Given a universe of integers, we can make the following true statements:
- For some
$x$ ,$p(x)$ - For some
$x$ ,$y$ ,$q(x, y)$
The phrases "For some x" are said to quantify the open statements
Quantifiers
- The existential quantifier
- The existential quantifier is denoted by
$\exists x$ and can be expressed as "For some$x$ ", "For at least one$x$ ", "There exists and$x$ such that". Thus, "For some$x$ ,$p(x)$ " is written$\exists x \; p(x)$ in symbolic form. "For some$x$ ,$y$ ,$q(x, y)$ " is written$\exists x \, \exists y \; q(x, y)$ in symbolic form, which can be abbreviated to$\exists x,y \; q(x, y)$ . - The universal quantifier
- The universal quanitifier is denoted by
$\forall x$ and can be expressed as "For all$x$ ", "For any$x$ ", "For each$x$ " or "For every$x$ ". Same as with the existential quantifier, "For all$x$ ,$p(x)$ " is written$\forall x \; p(x)$ in symbolic form, and "For all$x$ and$y$ " is written$\forall x \, \forall y$ , abbreviated to$\forall x, y$ .
Note: The statements
The truth values of quantified open statements are summarized in table 5.
| Statement | When Is It True? | When Is It False? |
| For some (at least one) |
For every |
|
| For every replacement |
There is at least one replacement |
|
| For at least one choice |
For every replacement |
|
| For every replacement |
There is at least one replacement |
Logical Equivalence and Logical Implication of Open Statements
Let
Similarly, if
For a prescribed universe and any open statements
Rules for negating statements with one quantifier:
- Rule of Universal Specification
- If an open statement becomes true for all replacements by the members in a given universe, then that open statement is true for each specific individual member in a given universe. In semi-symbolic form: If
$p(x)$ is an open statement for a given universe, and if$\forall{x} \; p(x)$ is true, then$p(a)$ is true for each$a$ in the universe. - Rule of Universal Generalization
- If an open statement
$p(x)$ is proven to be true when$x$ is replaced by any arbitrarily chosen element$c$ from our universe, then the universally quantified statement$\forall{x} \; p(x)$ is true. Furthermore, the rule extends beyond a single variable. So if, for example, we have an open statment$q(x, y)$ that is proved to be true when$x$ and$y$ are replaced by arbitrarily chosen elements from the same universe, or their own respective universes, then the universally quantified statement$\forall{x} \; \forall{y} \; q(x, y)$ is true. Similar results holdfor the cases of three or more variables.
See also the rules of existential specification and existential generalization in exercise 10, section 2.5 in Grimaldi.
Sets
Sections 3.1 and 3.2 in Grimaldi.
Terminology and Notation
- Set
- A well-defined collection of objects. Sets are typically denoted with uppercase letters, such as
$A$ ,$B$ ,$C$ , etc. The specification of a set is done with set braces. Example:$A = \{1, 2, 3\} = \{x|x \in \mathbb{Z} \text{ and } 1 \leq x \leq 3 \}$ . - Element
- A member of a set. Members of sets are typically denoted with lowercase letters. If
$x$ is an element of$A$ , we write$x \in A$ , and if$y$ is not an element of A, we write$y \not\in A$ . - Universe (of discourse)
- Specifies what "bag" of elements we are choosing from when forming a set. The set
$\{x|1 \leq x \leq 3\}$ with$x$ from the universe of all integers is not the same set as$\{x|1 \leq x \leq 3\}$ with$x$ from the universe of all real numbers. We will use the notation$\mathcal{U}$ for the universe here. - Cardinality
- The number of elements in a set. The cardinality of a set
$A$ is denoted by$|A|$ . - Finite set
- A set which has a finite number of elements. Think of it as a set you can count and finish counting at some point. Formally, it is a set whose cardinality is less than the cardinality of the natural numbers.
- Infinite set
- Simply put, a set that is not a finite set. Infinite sets are either countable or uncountable, but that is not important for this course.
- Subset
- If every element in set
$A$ is also an element of set$B$ , we say that$A$ is a subset of$B$ and write$A \subseteq B$ (also,$B \supseteq A$ ). If$A$ i not a subset of$B$ we write$A \not\subseteq B$ . - Proper subset
- If every element in set
$A$ is also an element of set$B$ and$B$ contains an element (or more) which is not in$A$ ,$A$ is a proper subset of$B$ , and we write$A \subset B$ (also$B \supset A$ ). If$A$ is not a proper subset of$B$ we write$A \not\subset B$ . - Equality of sets
- If
$A$ is a subset of$B$ and$B$ is a subset of$A$ , they are equal and we write$A = B$ . This is the same as saying that$A$ and$B$ contain exactly the same elements. Note that the order in which the elements appear in a set does not matter. - Null set or empty set
- The set containing no elements. It is denoted by
$\emptyset$ or { }. Its cardinality is 0. If$A$ is a set, then the empty set is always a subset of$A$ ($\emptyset \subseteq A$ ), and if$A$ is not empty ($A \neq \emptyset$ ), then the empty set is a proper subset of$A$ ($\emptyset \subset A$ ). - Power set
- The collection of all subsets of a given set
$A$ . It is denoted by$\mathcal{P}(A)$ . The total number of subsets of a set$A$ where$|A| = n$ is$2^n$ . Stated differently,$|\mathcal{P}(A)| = 2^{|A|}$ . - Union
- The union of two sets
$A$ and$B$ is written$A \cup B$ . If an element is either in$A$ or$B$ (or both), it is in the set$A \cup B$ . In symbolic form their union is given by$A \cup B = \{x|x \in A \lor x \in B \}$ . Note that in the same way that$1 +2 +3 + \dots + n = \Sigma^n_{i=1}i$ , we can write the union of multiple sets with the big union notation, for example:$S_1 \cup S_2 \cup S_3 \cup \dots \cup S_n = \bigcup^n_{i=1}S_i$ . - Intersection
- The intersection of two sets
$A$ and$B$ is written$A \cap B$ . If an element is in$A$ and also in$B$ , it is in the set$A \cap B$ . In symbolic form their intersection is given by$A \cap B = \{x|x \in A \land x \in B \}$ . As above with unions, the intersection of multiple sets can be written with the big intersection notation, for example:$S_1 \cap S_2 \cap S_3 \cap \dots \cap S_n = \bigcap^n_{i=1}S_i$ . - Symmetric difference
- The symmetric difference of two sets
$A$ and$B$ is written$A \vartriangle B$ . If an element is in either$A$ or$B$ but not in both, it is in the set$A \vartriangle B$ . In symbolic form the symmetric difference is given by$A \vartriangle B = \{x|x \in A \cup B \land x \not\in A \cap B\}$ . - Disjoint
- Two sets in the same universe are called disjoint or mutually disjoint when they do not share any elements. For the sets
$S, T \subseteq \mathcal{U}$ , we write this as$S \cap T = \emptyset$ . - Complement
- The complement of a set
$A \subseteq \mathcal{U}$ consists of all the elements in the universe except the elements in$A$ . It is denoted$\overline{A}$ (sometimes$\mathcal{U} - A$ ). In symbolic form the complement is given by$\overline{A} = \{x|x \in \mathcal{U} \land x \not\in A\}$ . - Relative complement
- The (relative) complement of
$A$ in$B$ , denoted$B - A$ , consists of all the elements of$B$ except the elements which are in$A$ . In symbolic form the relative complement of$A$ in$B$ is given by$B - A = \{x|x \in B \land x \not\in A\}$ . - Duality of set expressions
- The dual of a set expression is obtained by replacing all "
$\emptyset$ " with "$\mathcal{U}$ " and vice versa, and replacing all "$\cap$ " with "$\cup$ " and vice versa. - Principle of Duality
- Simply put, if two set expressions are equal, then their duals are also equal.
Laws of Set Theory
- Law of Double Complement
$\begin{equation} \overline{\overline{A}} = A \end{equation}$ - DeMorgan's Laws
$\begin{equation} \overline{A \cup B} = \overline{A} \cap \overline{B} \\ \overline{A \cap B} = \overline{A} \cup \overline{B} \end{equation}$ - Generalized DeMorgan's Laws
$\begin{equation} \text{Let } I \text{ be an index set,} \\ \overline{\bigcup_{i \in I}A_i} = \bigcap_{i \in I} \overline{A_i} \\ \overline{\bigcap_{i \in I}A_i} = \bigcup_{i \in I} \overline{A_i} \end{equation}$ - Commutative Laws
$\begin{equation} A \cup B = B \cup A \\ A \cap B = B \cap A \end{equation}$ - Associative Laws
$\begin{equation} A \cup (B \cup C) = (A \cup B) \cup C \\ A \cap (B \cap C) = (A \cap B) \cap C \end{equation}$ - Distributive Laws
$\begin{equation} A \cup (B \cap C) = (A \cup B) \cap (A \cup C) \\ A \cap (B \cup C) = (A \cap B) \cup (A \cap C) \end{equation}$ - Idempotent Laws
$\begin{equation} A \cup A = A \\ A \cap A = A \end{equation}$ - Identity Laws
$\begin{equation} A \cup \emptyset = A \\ A \cap \mathcal{U} = A \end{equation}$ - Inverse Laws
$\begin{equation} A \cup \overline{A} = \mathcal{U} \\ A \cap \overline{A} = \emptyset \end{equation}$ - Domination laws
$\begin{equation} A \cup \mathcal{U} = \mathcal{U} \\ A \cap \emptyset = \emptyset \end{equation}$ - Absorption Laws
$\begin{equation} A \cup (A \cap B) = A \\ A \cap (A \cup B) = A \end{equation}$
A Few Important Sets of Numbers
| the set of natural numbers | ||
| the set of integers | ||
| the set of rational numbers | ||
| the set of real numbers | i.e. all numbers along the number line |
Note! We have defined the set of natural numbers to include 0. This is a convention in discrete mathematics/number theory (c.f. Grimaldi, Rosen), but it is not the most common practice in mathematics as a whole (where the natural numbers usually start at 1). An unambiguous notation for the set of non-negative integers is
Boolean Functions and Boolean Algebra
Sections 15.1 and 15.4 in Grimaldi.
Boolean Functions
Operations on Boolean elements
Let
A variable
Table ? gives an overview of the definitions of addition, multiplication and complement on the elements in
| Elements in |
Boolean variables | |
| Addition | ||
| Multiplication | ||
| Complement |
Terminology and Notation
The conjunctive normal form, sum of minterms, disjunctive normal form and product of maxterms may require looking at more examples than are provided here in order to grasp the concepts.
- Boolean variable
- A variable which only takes the values 0 or 1, and is operated on using the Boolean arithmetic described in table ?.
- Switching function or Boolean function
- A function which takes in
$n$ Boolean variables and outputs a single Boolean value; 0 or 1 depending on the input to the function. We write this as$f \! : B^n \rightarrow B$ . Example of a Boolean function:$g \! : B^3 \rightarrow B$ , where$g(x, y, z) = xy + z$ . - Dual of a Boolean function
- The dual of a Boolean function is obtained by replacing all occurences of + by
$\cdot$ and vice versa, and all occurences of 0 by 1 and vice versa. - Principle of Duality
- Simply put, if two Boolean functions or expressions of Boolean variables are equal, then their duals are also equal.
- Literal
- Each term
$x_i$ of a Boolean function$f(x_1, x_2, \dots, x_n)$ or its complement. The literals of$f(x, y, z)$ are "$x$ or$\overline{x}$ ", "$y$ or$\overline{y}$ " and "$z$ or$\overline{z}$ ". - Fundamental conjunction
- A single term in which all literals of a Boolean function are multiplied, for example
$\overline{x}y\overline{z}$ or$xy\overline{z}$ for$f(x, y, z)$ . - Disjunctive normal form (d.n.f.)
- A representation of a Boolean function as a sum of fundamental conjunctions. For example, the d.n.f. for
$f: B^3 \rightarrow B$ , where$f(x, y, z) = xy + \overline{x}z$ is$f(x, y, z) = \overline{x}\overline{y}z + \overline{x}yz + xy\overline{z} + xyz$ . - Minterm
- A way of representing a fundamental conjunction. A minterm is an encoding of a fundamental conjunction as a binary label, which is converted to a number. We write the minterms of the function
$f$ defined above as$m(1, 3, 6, 7)$ . See table ? for how the encoding is done. - Sum of minterms
- The disjunctive normal form (d.n.f.) of a function can be expressed as a sum of minterms, since the minterms are just a way to represent the fundamental conjunctions of the d.n.f. For the function
$f$ defined above, we write this as$f = \sum m(1, 3, 6, 7)$ . This is simply a more concise way of expressing the d.n.f. - Fundamental disjunction
- A single term in which all literals of a Boolean function are added together, for example
$x + \overline{y} + z$ for the function$f(x, y, z)$ . - Conjunctive normal form (c.n.f.)
- A representation of a Boolean function as a product of fundamental disjunctions.
- Maxterm
- A way of representing a fundamental disjunction. A maxterm is an encoding of a fundamental disjunction as a binary label, which is converted to a number. A capital M is used for maxterms (as opposed to lowercase m for minterms):
$M(0, 2, 6)$ . See table ? for how the encoding is done. - Product of maxterms
- The conjunctive normal form (c.n.f.) of a function can be expressed as a product of maxterms. For a function
$f$ with the maxterms$M(0, 2, 6)$ we write$f = \prod M(0, 2, 6)$ .
For a function with three variables
| Binary label | Minterm/maxterm number | |||
| 0 | 0 | 0 | 000 | 0 |
| 0 | 0 | 1 | 001 | 1 |
| 0 | 1 | 0 | 010 | 2 |
| 0 | 1 | 1 | 011 | 3 |
| 1 | 0 | 0 | 100 | 4 |
| 1 | 0 | 1 | 101 | 5 |
| 1 | 1 | 0 | 110 | 6 |
| 1 | 1 | 1 | 111 | 7 |
Laws of Boolean Functions and Boolean Variables
Notice how the laws of Boolean algebra are just a restatement of the laws of logic and the laws of set theory, using "+" for "
| Law | Boolean Functions | Boolean Variables |
| Law of the Double Complement | ||
| DeMorgan's Laws | ||
| Commutative Laws | ||
| Associative Laws | ||
| Distributive Laws | ||
| Idempotent Laws | ||
| Identity Laws | ||
| Inverse Laws | ||
| Dominance Laws | ||
| Absorption Laws |
Boolean Algebra
Definition
Let
- Commutative Laws
$\begin{equation}x + y = y + x \\ xy = yx \end{equation}$ - Distributive Laws
$\begin{equation}x(y + z) = xy + xz\\ x + yz = (x + y)(x + z) \end{equation}$ - Identity Laws
$\begin{equation}x + 0 = x \\ x \cdot 1 = x \end{equation}$ - Inverse Laws
$\begin{equation} x + \overline{x} = 1 \\ x \cdot \overline{x} = 0 \end{equation}$ - Inequality of the Special Elements
$0 \neq 1$
When the operations and identity elements are known, we simply write
Currently missing from this section: More Laws for a Boolean Algebra (derived from the definition of a BA), Hasse diagrams, partial ordering of any finite Boolean algebra, atoms of a Boolean algebra, isomorphism of Boolean algebras, some examples of Boolean algebras other than the two-element Boolean algebra.
Induction and Recursion
Sections 4.1 and 4.2 in Grimaldi.
To get a good grasp of mathematical induction, you need to practice writing detailed, correct proofs.
- The Well-Ordering Principle
- Every nonempty subset of
$\mathbb{Z^+}$ contains a smallest element. (This is important as a basis for mathematical induction. Consider also the fact that neither$\mathbb{Q^+}$ nor$\mathbb{R^+}$ have a smallest element, i.e. they are not well ordered like$\mathbb{Z^+}$ ). - The Principle of Mathematical Induction
- Let
$n$ represent a positive integer and let$S(n)$ be a mathematical statement involving$n$ . If$S(1)$ is true and if$S(k+1)$ is true whenever$S(k)$ is true for an arbitrarily chosen positive integer$k$ , then$S(n)$ is true for all positive integers. For the geeks out there:$\Big(S(n_0) \land \big( \forall \; k \geq n_0 \; (S(k) \Rightarrow S(k+1)) \big)\Big) \Rightarrow \forall \; n \geq n_0 \; S(n).$ - Basis step
- The first step in mathematical induction: Proving that the statement is true for a smallest integer of choice, typically 0 or 1. The rest of the induction rests upon this step.
- Inductive step
- The second step in mathematical induction: Proving that whenever the statement is true for any arbitrary integer
$k$ greater than or equal to the integer in the basis step, the statement is also true for$k + 1$ . So if$S(1)$ is true, and we succeed in the inductive step, then$S(2), S(3), S(4), \dots$ will also be true. To inifinity and beyond! - Recursion
- A recursive definition has two parts: 1) A base case (or cases) which do not use recursion for their values, and 2) a set of rules that reduce all other cases toward the base case. See the below entries for examples.
- Fibonacci numbers
- Base case:
$F_0 = 0, F_1 = 1$ . Recursive rule:$F_n = F_{n-1} + F_{n-2}$ , for$n \in \mathbb{Z^+}$ with$n \geq 2$ . The first eight Fibonacci numbers are 0, 1, 1, 2, 3, 5, 8, 13, 21. - Harmonic numbers
- Base case:
$H_1 = 1$ . Recursive rule:$H_{n+1} = H_n + (\frac{1}{n+1})$ , for$n \in \mathbb{Z^+}$ with$n \geq 1$ . The$n$ th harmonic number$H_n$ is$1 + \frac{1}{2} + \frac{1}{3} + \cdots + \frac{1}{n}$ . - Lucas numbers
- Base case:
$L_0 = 2, L_1 = 1$ . Recursive rule:$L_n = L_{n-1} + L_{n-2}$ , for$n \in \mathbb{Z^+}$ with$n \geq 2$ . The first eight Lucas numbers are 2, 1, 3, 4, 7, 11, 18, 29.
Combinatorics
Sections 1.1–1.5 and 8.1 in Grimaldi.
When learning the formulas for the combinatorial principles, permutations, combinations etc., make sure you also know what practical problems the formulas are used to solve (and practice solving them).
This section on combinatorics could be improved by adding a subsection with a handful examples of common practical problems (string permutations, team selections, stars and bars problems, etc.).
- Rule of sum (addition principle)
- Simply put, if we have
$m$ ways of doing something and$n$ ways of doing another thing and we can not do both at the same time, then there are$m + n$ ways to choose one of the actions. - Rule of product (multiplication principle)
- Simply put, if we have
$m$ ways of doing something and$n$ ways of doing another thing, then there are$m \cdot n$ ways to do both actions. - Factorial
- For an integer
$n \geq 0$ , "$n$ factorial" is denoted by$n!$ and is defined by$0! = 1$ ,$n! = (n)(n-1)(n-2)\cdots(3)(2)(1)$ , for$n \geq 1$ . For example,$4! = 4\cdot3\cdot2\cdot1 = 24$ . Also, knowing that$(n+1)! = (n+1)(n!)$ is often useful. - Permutation (ordered arrangement)
- A linear arrangement of a collection of distinct objects where the order of the objects in the arrangement is important, and repetition of objects is not permitted. The number of permutations of size
$r$ (where$0 \leq r \leq n$ ) from a collection of$n$ objects is$P(n, r) = \frac{n!}{(n-r)!}$ . - Linear arrangements with repetition
- The number of linear arrangements of size
$r$ from a collection of size$n$ when objects can be repeated, is$n^r$ , with$r \geq 0$ . - Linear arrangements with identical objects
- If there are
$n$ objects with$n_1$ identical objects of a first kind,$n_2$ identical objects of a second kind, …, and$n_r$ identical objects of an$r$ th kind, where$n_1 + n_2 + \cdots + n_r = n$ , then there are$\begin{equation} \frac{n!}{n_1!n_2!\cdots n_r!}\end{equation}$ linear arrangements of the given$n$ objects. - Circular arrangement
- For a collection of
$n$ objects, each circular arrangement corresponds to$n$ linear arrangements, so that there are in total$\frac{n!}{n}$ circular arrangements. - Binomial coefficient
- The notation
$\binom{n}{r}$ is called the binomial coefficient and is equal to$\frac{n!}{r!(n-r)!}$ (see "Combination" below). - Combination (unordered selection)
- A selection from a collection of distinct objects where the order of the objects is not important, and repetition is not allowed. The number of combinations of size
$r$ (where$0 \leq r \leq n$ ) from a collection of$n$ objects is$C(n, r) = \binom{n}{r} = \binom{n}{n - r} = \frac{P(n, r)}{r!} = \frac{n!}{r!(n-r)!}$ . - Combination with repetition
- The number of combinations of
$n$ objects of size$r$ with repetition is$\binom{n \;+ \;r \;- \;1}{r}$ , where$r$ may exceed$n$ . - Integer solutions
- The number of nonnegative integer solutions of the equation
$x_1 + x_2 + \cdots + x_n = r$ ,$x_i \geq 0$ ,$1 \leq i \leq n$ is a case of combination with repetition, equivalent to distributing$r$ identical objects among$n$ distinct containers. Thus the answer is$\binom{n \;+\; r \;-\; 1}{r}$ . The number of positive integer solutions is$\binom{r \;-\; 1}{n \;-\; 1}$ . - Integer compositions
- Ways in which to write a number as a sum of positive integers, where the order of the summands is considered relevant. There are
$\sum_{k=0}^{n-1}\binom{n \;-\; 1}{k} = 2^{n-1}$ integer compositions for each positive integer$n$ . - Binomial theorem
- If
$x$ and$y$ are variables and$n$ is a positive integer, then$(x+y)^n = \binom{n}{0}x^0y^n + \binom{n}{1}x^1y^{n-1} + \binom{n}{2}x^2y^{n-2} + \cdots + \binom{n}{n-1}x^{n-1}y^1 + \binom{n}{n}x^ny^0 = \sum_{k=0}^n \binom{n}{k}x^ky^{n-k}.$ - Inclusion–exclusion principle
- A counting technique which generalizes the method of obtaining the number of elements in the union of two finite sets;
$|A \cup B| = |A| + |B| - |A \cap B|$ . The general formula goes as follows...$$\left|\bigcup _{i=1}^{n}A_{i}\right| = \sum _{i=1}^{n}|A_{i}| \\ - \sum _{1\leqslant i<j\leqslant n}|A_{i}\cap A_{j}| \\ + \sum _{1\leqslant i<j<k\leqslant n}|A_{i}\cap A_{j}\cap A_{k}| \\ - \cdots \\ + (-1)^{n-1}\left|A_{1}\cap \cdots \cap A_{n}\right|.$$ Since the formula is a bit complicated, it is useful to begin with looking at examples with three or four sets in the book or online.
Relations and Functions
Sections 5.1–5.3, 5.6, 7.1–7.4 in Grimaldi.
Terminology and Notation
- Cartesian product or cross product
- For sets
$A$ and$B$ , the cartesian product$A \times B$ is the set of all ordered pairs$(a, b)$ where$a \in A$ and$b \in B$ . - Relation
- Any subset of
$A \times B$ is called a relation from$A$ to$B$ . Any subset of$A \times A$ is called a relation on$A$ . We use$\mathcal{R}$ to denote a relation, and if$(a, b) \in \mathcal{R}$ we can use the infix notation$a~\mathcal{R}~b$ (and if$(a, b) \not\in \mathcal{R}$ ,$a~\mathord{\not\mathrel{\mathcal{R}}}~b$ ). - Function
- A function
$f$ from set$A$ to set$B$ , denoted$f\!: A \to B$ , is a special kind of relation from$A$ to$B$ , in which every element of A appears exactly once as the first component of an ordered pair in the relation. If$(a, b)$ is an ordered pair in the relation, we write$f(a) = b$ . Also,$f(A) = \{b\in B|b = f(a)$ , for some$a \text{ in } A \}$ . - Image and preimage
- For
$(a, b) \in f$ ,$b$ is called the image of$a$ under$f$ and$a$ is a preimage of$b$ . Similarly, if$f\!: A \to B$ and$A_1 \subseteq A$ ,$f(A_1)$ is called the image of$A_1$ under$f$ . - Domain
- The set the function is defined upon to have as input. For the function
$f\!: A \to B$ ,$A$ is called the domain. Every$a$ in$A$ maps to some$b$ in$B$ . - Codomain
- The set which contains all possible outputs of a function. For the function
$f\!: A \to B$ ,$B$ is called the codomain. For each$b$ in$B$ , there may or may not be an$a$ in$A$ such that$f(a) = b$ . In other words, not all functions have mappings to all of the elements in the codomain. See injective and surjective below for the definitions of different types of functions in this regard. - Range
- For
$f\!: A \to B$ ,$f(A)$ is the range of the function. This is the subset of the codomain$B$ consisting of the elements$b$ for which there exist an$a$ in$A$ such that$f(a) = b$ . - Restriction
- Restrictin the domain of a function to a subset of the original domain. If
$f\!: A \to B$ and$A_1 \subseteq A$ , then the restriction of$f$ to$A_1$ is denoted$f|_{A_1}\!: A_1 \to B$ , and it is valid as long as$f|_{A_1}(a) = f(a)$ for all$a$ in$A_1$ . - Extension
- Expanding a function beyond its original domain. Let
$A_1 \subseteq A$ and$f\!: A_1 \to B$ . If$g\!: A \to B$ and$g(a) = f(a)$ for all$a$ in$A$ , then we call$g$ an extension of$f$ to$A$ . - Injective or one-to-one
- A function
$f\!: A \to B$ is injective if each element of$B$ appears at most once as the image of an element of$A$ . Therefore, given an injective function, no two elements$x_1, x_2$ in$A$ can map to the same element$y$ in$B$ . If they do, then$x_1 = x_2$ . - Surjective or onto
- A function
$f\!: A \to B$ is surjective if each element of$B$ appears at least once as the image of an element of$A$ . Therefore, given a surjective function, for every$b$ in$B$ there exists at least one$a$ in$A$ such that$f(a) = b$ . For a surjective function, the range and the codomain of the function are the same,$f(A) = B$ . - Bijective or one-to-one correspondence
- A function is bijective if it is both injective and surjective. Therefore, a function
$f\!: A \to B$ is bijective if each element of$B$ appears only once as the image of an element of$A$ . - Number of onto functions
- May or may not be exam relevant. For finite sets
$A$ ,$B$ with$|A| = m$ and$|B| = n$ there are$\sum^n_{k=0}(-1)^k\binom{n}{n \;-\; k}(n - k)^m$ onto functions from$A$ to$B$ . - Equality of functions
- Two functions are equal if and only if their domains and codomains are equal, and
$f(x) = g(x)$ for all$x$ in their domain. As a counterexample, if$f\!: \mathbb{Z} \to \mathbb{Z}$ ,$g\!: \mathbb{Z} \to \mathbb{Q}$ , where$f(x) = g(x)$ for all$x$ in$\mathbb{Z}$ , then$f$ and$g$ are not equal ($f \neq g$ ), since their domains are not equal, even though they have equal outputs for every possible input. - Identity function
- The identity function for a set
$A$ ,$1_A\!: A \to A$ , is defined by$1_A(a) = a$ for all$a$ in$A$ . - Composition of functions
- The composite function of
$f\!: A \to B_1$ and$g\!: B \to C$ is denoted$g \circ f\!: A \to C$ and is defined by$(g \circ f)(a) = g(f(a))$ , for each$a$ in$A$ , as long as$B_1 \subseteq B$ . You can think of it as the first function$g$ "eating" the output of the second function$f$ . If the range of$f$ is not a subset of the domain of$g$ , then the composite function$g \circ f$ is not defined. - Powers of functions
- If
$f\!: A \to A$ we define$f^1 =f$ , and for a positive integer$n$ ,$f^{n+1} = f \circ (f^n)$ . - Converse of a relation
- If
$\mathcal{R}$ is a relation from$A$ to$B$ , then the converse of$\mathcal{R}$ , denoted$\mathcal{R}^c$ , is the relation from$B$ to$A$ defined by$\mathcal{R}^c = \{(b, a)|(a, b) \in \mathcal{R} \}$ . Simply put, it is the relation$\mathcal{R}$ just in reverse. The converse of a function is a relation which may or may not be a function. - Inverse of a function
- For a function to have an inverse, it must be invertible. A function
$f\!: A \to B$ is invertible if there exists a function$g\!: B \to A$ such that$g\circ f = 1_A$ and$f \circ g = 1_B$ . You could also say that a function is invertible if it has a converse which is also a function. More specifically, a function is invertible if and only if it is injective (one-to-one) and surjective (onto), i.e. it is bijective (one-to-one correspondence). The notation for the inverse of$f$ is$f^{-1}$ , and since$f$ is invertible,$f^{-1} = f^c$ .
More on Relations
- Reflexivity
- A relation
$\mathcal{R}$ on a set$A$ is called reflexive if for all$x$ in$A$ ,$(x, x)$ is in$\mathcal{R}$ . So if$x$ is related to anything else ($x$ occurs as a member of an ordered pair in the relation), it also means that$x$ is related to itself. - Symmetry
- A relation
$\mathcal{R}$ on a set$A$ is called symmetric if$(x, y) \in \mathcal{R} \Rightarrow (y, x) \in \mathcal{R}$ , for all$(x, y)$ in$A$ . So if$x$ is related to$y$ , it means that$y$ is related to$x$ . - Transitivity
- For a set
$A$ , a relation$\mathcal{R}$ on$A$ is called transitive if, for all$x, y, z \in A$ ,$(x, y), (y, z) \in \mathcal{R} \Rightarrow (x, z) \in \mathcal{R}$ . So if$x$ is related to$y$ and$y$ is related to$z$ , then$x$ is also related to$z$ ,. - Antisymmetry
- Given a relation
$\mathcal{R}$ on a set$A$ ,$\mathcal{R}$ is called antisymmetric if for all$a, b \in A$ ,$(a~\mathcal{R}~b \text{ and } b~\mathcal{R}~a) \Rightarrow a = b$ . So the only way that we can have both "$a$ is related to$b$ " and "$b$ is related to$a$ " is if$a$ and$b$ are the same. - Partial ordering relation or partial order
- A relation is called a partial ordering relation if it is reflexive, antisymmetric and transitive.
- Equivalence relation
- A relation is called an equivalence relation if it is reflexive, symmetric and transitive.
- Composition of relations
- If
$A$ ,$B$ and$C$ are sets with$\mathcal{R}_1 \subseteq A \times B$ and$\mathcal{R}_2 \subseteq B \times C$ , then the composite relation$\mathcal{R}_1 \circ \mathcal{R}_2$ is a relation from$A$ to$C$ defined by$\mathcal{R}_1 \circ \mathcal{R}_2 = \{(a, c)|a \in A, c \in C$ and there exists$b\in B$ with$(a, b) \in \mathcal{R}_1, (b, c)\in \mathcal{R}_2 \}$ . Be careful in the composition in relations, since the order the composition is written in is different from the order function compositions are written in! - Partially ordered set or poset
- If a relation
$\mathcal{R}$ on a set$A$ is a partial ordering relation, we call the pair$(A, \mathcal{R})$ a partially ordered set or poset. If we call$A$ a poset, this is shorthand for saying that there is a partial order$\mathcal{R}$ on$A$ that makes$A$ into this poset. - Hasse diagram
- A graphical representation of a partially ordered set, as a directed graph with an implied upward orientation. We construct a Hasse diagram for a poset by drawing an edge from
$x$ up to$y$ if$x \mathcal{R} y$ and, most important, if there is no other element$z$ such that$x~\mathcal{R}~z$ and$z \mathcal{R} y$ , i.e. it is the most "direct" way of relating. See the figure below. - Totally ordered poset
- Also called linearly ordered. Let
$(A, R)$ be a poset,$A$ is totally ordered, if every element is comparable to each other, i.e. for all$x,y \in A$ either$x~\mathcal{R}~y$ or$y~\mathcal{R}~x$ .$R$ is then called a total order on$A$ . We can create a total order from a partial order by implementing the topological sorting algorithm (see next). - Topological sorting algorithm
- We can create a total order
$\mathcal{T}$ from a partial order$\mathcal{R}$ for which$\mathcal{R} \subseteq \mathcal{T}$ . Step 1: Set$k = 1$ . Let$H_1$ be the Hasse diagram of the partial order. Step 2: Select a vertex$v_k$ in$H_k$ such that no edge in$H_k$ starts at$v_k$ . Step 3: If$k = n$ , the process is completed and we have a total order$\mathcal{T}\!: v_1 > v_2 > \cdots > v_{n-1} > v_n$ that contains$\mathcal{R}$ . - Maximal element
- If
$(A, \mathcal{R})$ is a poset, then an element$x$ in$A$ is called a maximal element of$A$ if there are no other elements$a$ in$A$ such that$x~\mathcal{R}~a$ (as long as$a \neq x$ ). A poset can have several maximal elements. For a finite set there is at least one maximal element. - Minimal element
- If
$(A, \mathcal{R})$ is a poset, then an element$x$ in$A$ is called a minimal element of$A$ if there are no other elements$a$ in$A$ such that$a~\mathcal{R}~x$ (as long as$a \neq x$ ). A poset can several minimal elements. For a finite set there is at least one minimal element. - Least element
- If
$(A, \mathcal{R})$ is a poset, then an element$x$ in$A$ is called a least element if$x~\mathcal{R}~a$ for all$a$ in$A$ . A poset can have at most one least element. - Greatest element
- If
$(A, \mathcal{R})$ is a poset, then an element$x$ in$A$ is called a greatest element if$a~\mathcal{R}~x$ for all$a$ in$A$ . A poset can have at most one greatest element. - Greatest lower bound (glb) or infimum
- Let
$(A, \mathcal{R})$ be a poset with$B \subseteq A$ . An element$x \in A$ is called a lower bound of$B$ if$x~\mathcal{R}~b$ for all$b \in B$ . An element$y$ is called a greatest lower bound (glb) of$B$ if it is a lower bound of$B$ and if for all other lower bounds$z$ of$B$ , we have$z~\mathcal{R}~y$ . There is at most one greatest lower bound for any subset of a poset. For finite, totally ordered sets, glb and the least element are the same. There can be a glb for$B$ without the glb being in$B$ . - Least upper bound (lub) or supremum
- Let
$(A, \mathcal{R})$ be a poset with$B \subseteq A$ . An element$x \in A$ is called a upper bound of$B$ if$b~\mathcal{R}~x$ for all$b \in B$ . An element$y$ is called a least upper bound (lub) of$B$ if it is an upper bound of$B$ and if for all other lower bounds$z$ of$B$ , we have$y~\mathcal{R}~z$ . There is at most one least upper bound for any subset of a poset. There can be a lub for$B$ without the lub being in$B$ . - Lattice
- A poset
$A$ is called a lattice if for all$x, y, \in A$ the elements lub{$x, y$ } and glb{$x, y$ } both exist in$A$ . - Partition
- A partition of a set is a grouping of the set's elements into non-empty subsets, in such a way that every element is included in one and only one of the subsets. Each subset in a partition is called a cell or block of the partition.
- Equivalence class
- A set of elements where all the elements are related to one another through an equivalence relation. Any equivalence relation
$\mathcal{R}$ on$A$ induces a partition of$A$ , and each cell/block in the partition of$A$ can be called an equivalence class. Also, any partition of$A$ gives rise to an equivalence relation$\mathcal{R}$ on$A$ .
Hasse diagram
It would be helpful with a bit more information about Hasse diagrams here, and perhaps a visual demonstration of the topological sorting algorithm.
A Hasse diagram is a way of visualising the partially ordered digraph, drawed in an as minimal way as possible, cutting out loops due to the implisit reflextivity, and edges from the lower vertices to the higher ones that hop over a tier, due to the implisit transitivity. You also omit the direction of the edges, by implying a "flow of order", conventially bottom up. The following example represents the hassediagram for the poset
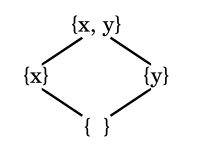
As you can see the Hasse diagram is rather simple, while the full set of edges for this graph would be
Graphs and Trees
Sections 11.1–11.5 and 12.1–12.3 in Grimaldi.
Graphs
Terminology and Notation
 Directed graph.
Directed graph.
 Undirected, loop-free graph.
Undirected, loop-free graph.
- Vertex or node
- One of the two basic units of which graphs are formed. The plural of vertex is vertices. In the figures above, the labeled dots
$a, b, \dots$ are the vertices of the graphs. The set of vertices of a graph is denoted$V$ . - Edge and arc
- One of the two basic units of which graphs are formed. An edge connects two vertices. Edges may be directed or undirected; undirected edges are also called lines, and directed edges are also called arcs. An edge may be represented as a pair of its vertices (so if
$a$ and$b$ are vertices connected by an edge, we write$(a, b)$ for this edge). The set$E$ of edges of a graph is thus a subset of the cross product of the vertices;$E \subseteq V \times V$ . - Directed graph or digraph
- We write
$G = (V, E)$ for a directed graph on$V$ , where$E$ is the set of ordered pairs of elements taken from$V$ . For the edge$(a, b) \in E$ ,$a$ is the starting vertex and$b$ is the end vertex. We indicate this direction on a graph by drawing a directed arrow on the edge. - Undirected graph
- If the direction of the edges is unimportant, for
$G = (V, E)$ ,$E$ is the set of unordered pairs of elements taken from$V$ , and we call the graph undirected. The we simply draw a line without any arrows for the edges of an undirected graph. When a graph is not specified as directed or undirected, it is assumed to be undirected. - Incident
- For any edge
$(a, b)$ , we say that the edge is incident with the vertices$a, b$ . - Adjacent
- For an edge
$(a, b)$ of a directed graph,$a$ is adjacent to$b$ and$b$ is adjacent from$a$ . - Origin or source
- For an edge
$(a, b)$ of a directed graph, vertex$a$ is called the origin of the edge. - Terminus or terminating vertex
- For an edge
$(a, b)$ of a directed graph, vertex$b$ is called the terminus. - Loop
- An edge
$(a, a)$ if a directed graph is called a loop. A graph that contains no loops is called loop-free. - Isolated vertex
- A vertex which as no incident edges.
- Walk
- A finite alternating sequence of vertices and edges. An
$x$ –$y$ walk is the sequence$x=v_0,e_1,v_1,e_2, v_2, e_3, \dots ,e_k,v_k=y$ of vertices and edges from the graph, starting from vertex$x$ , ending in vertex$y$ . The length of this walk is the number of edges in the walk. The walk is called closed if the starting vertex is the same as the ending vertex, otherwise it is called open. - Trail
- An
$x$ –$y$ trail is an$x$ –$y$ walk where no edge in the walk is repeated. - Circuit
- A circuit is a closed trail (
$x$ –$x$ ). - Path
- An
$x$ –$y$ path is an$x$ –$y$ walk where no vertex is repeated. - Cycle
- A cycle is a closed path where no other vertices are repeated apart from the start/end vertex.
- Connected graph
- If there is a path between all the vertices of the underlying graph of a digraph, then the graph is connected. A graph that is not connected is called disconnected.
- Components
- If a graph is disconnected, the connected pieces of the graph are called components. A graph is connected if and only if it has only one component. The number of components of
$G$ is denoted by$\kappa(G)$ . - Multigraph
- If there is more than one edge between two adjacent vertices in the graph, it is called a multigraph.

- Subgraph
- A graph whose vertices and edges are a subset of another graph.
- Spanning subgraph
- If
$H$ is a subgraph of$G$ ,$H$ is a spanning subgraph of$G$ if it contains all the vertices of$G$ . - Induced subgraph
- If
$H$ is a subgraph of$G$ ,$H$ is an induced subgraph if it contains all the edges from$G$ . - Complete graph
- A loop-free, undirected graph where all vertices are joined to each other by exactly one edge. It is denoted
$K_n$ . - Complement of a graph
- The subgraph of the complete graph
$K_n$ , consisting of the$n$ vertices in$G$ and all edges that are not in$G$ . The subgraph of$G$ is denoted$\overline{G}$ . - Isomorphic graphs
- Two graphs with the same number of vertices, connected in the same way are said to be isomorphic.
Vertex Degree, Euler Trails, Circuits
- Degree of a vertex
- The degree of a vertex
$v$ , written$\deg(v)$ , is the number of edges incident with$v$ . A loop in vertex$v$ is considered as two incident edges. - Sum of degrees of vertices
- For any graph, the sum of the degrees of the vertices equals twice the number of edges;
$\sum_{v \in V} \deg(v) = 2|E|$ . - Incoming degree of a vertex
- In a directed graph, the incoming degree of
$v$ is the number of edges incident into$v$ , denoted$id(v)$ . (Each loop at a given vertex$v$ contributes a count of 1 to each of$id(v)$ and$od(v)$ .) - Outgoing degree of a vertex
- In a directed graph, the outgoing degree of
$v$ in the number of edges incident from$v$ , denoted$od(v)$ . (Each loop at a given vertex$v$ contributes a count of 1 to each of$id(v)$ and$od(v)$ .) - Euler circuit
- A closed trail containing all edges of a graph, which returns to the start vertex and does not repeat any edges. An undirected graph with no isolated vertices has an Euler circuit if and only if the graph is connected and every vertex has even degree.
- Euler trail
- An open trail from
$a$ to$b$ in a graph which traverses every edge exactly once. An undirected graph with no isolated vertices has an Euler trail if and only if the graph is connected and has exactly two vertices of odd degree. These two vertices of odd degree are the start and end points of the Euler trail. - Directed Euler circuit
- A directed graph with no isolated vertices has a directed Euler circuit if and only if it is connected and
$id(v) = od(v)$ for all vertices. - Planar graph
- A graph is planar if it can be drawn in the plane, with its edges only intersecting at vertices of
$G$ . That is, it must be possible to draw the graph without any of the edges crossing each other.$K_1, K_2, K_3$ and$K_4$ are planar graphs. - Bipartite graphs
- A graph that has a partition
$V= V_1 \cup V_2$ and$V_1 \cap V_2 = \emptyset$ . This means that all edges share a vertex from both set$V_1$ and$V_2$ , and there are no edges formed between two vertices within either set$V_1$ or$V_2$ . - Complete bipartite graphs
- If each vertex in
$V_1$ is joined with every vertex in$V_2$ , it is called a complete bipartite graph, and is denoted$K_{m, n}$ , where$m = |V_1|$ and$n = |V_2|$ . - Elementary subdivision
- You create an elementary subdivision of a graph when you remove an edge, and replace it with a new vertex indicent to the two vertices the edge was originally indicent to. Think of it as putting a vertex "dot" right on top of an edge, removing the old edge and replacing it with two new ones.
- Homeomorphic graphs
- Graphs are homeomorphic if they are isomorphic or if they can both be obtained from the same "parent" graph by a sequence of elementary subdivisions. If two graphs are homeomorphic, they are either both planar or they are both nonplanar.
- Proof of nonplanarity (Kuratowski's theorem)
- A graph is nonplanar if and only if it contains a subgraph that is homeomorphic to either
$K_5$ or$K_{3, 3}$ . Recall that$K_{3,3}$ is the complete bipartite graph of three vertices in each partition. - Another way to prove nonplanarity
- If
$G$ is a loop-free, connected planar graph with$v$ vertices and$e > 2$ edges and$r$ regions, then$3r \leq 2e$ and$e \leq 3v - 6$ . For example, if a loop-free, connected graph has$e > 2$ , but$e > 3v - 6$ , the graph is not planar. Note that the converse is not the case, i.e. if$e \leq 3v - 6$ , we cannot conclude that the graph is planar. - Number of regions from a planar graph (Euler's formula)
- For a connected planar simple graph
$G=(V,E)$ with$e=|E|$ and$v=|V|$ , if we let$r$ be the number of regions that are created when drawing a planar representation of the graph, then$r=e−v+2$ . - Cut-set
- A subset
$E'$ of$E$ from$G = (V, E)$ is called a cut-set of$G$ if by removing the edges in$E'$ from$G$ resulting in$G'$ , there are more components in$G'$ than in$G$ , written as$\kappa(G) < \kappa(G')$ , but when we remove any proper subset$E''$ of$E'$ from$G$ , the number of components remains unchanged, written as$\kappa(G) = \kappa(G'')$ . Hence, a cut-set is a minimal disconnecting set of edges (since by removing any of the edges in the cut-set, the remaining edges are no longer a cut-set). - Hamilton cycle
- A graph with more than two vertices (
$|V| \geq 3$ ) has a Hamilton cycle if there is a cycle in the graph which contains every vertex. If a graph has a Hamilton cycle, then all vertices have a degree of two or greater ($\deg(v) \geq 2$ ). - Hamilton path
- A Hamilton path is a path (and not a cycle) in a graph that contains each vertex.
- Formula for existence of Hamilton path
- Needs content. See 11.5, theorem 8 and corollary 4.
- Formula for existence of Hamilton cycle
- Needs content. See 11.5, theorem 9 and corollaries 5 and 6.
Trees
Terminology and Notation
- Tree
- Let
$G$ be a loop-free, undirected graph. The graph$G$ is called a tree if$G$ is connected and contains no cycles. - Subtree
- A subgraph of a tree which is also a tree.
- Spanning tree
- A spanning tree of
$G$ is a subgraph of$G$ that is a tree containing every vertex of$G$ . - Connected graphs and spanning trees
- Every connected graph has a spanning tree. An undirected graph is connected if and only if it has a spanning tree.
- Unique path theorem
- A graph is a tree if and only if there is exactly one path between every pair of its vertices.
- Number of vertices and edges
- In every tree
$T = (V,E), |V|=|E|+1$ . - Pendant vertex and pendant edge
- A vertex of degree one is called a pendant vertex, and the edge incident to it is a pendant edge.
- Number of vertices/edges in a tree
- For a tree
$T = (V, E)$ , the number of vertices$|V| = |E| + 1$ , and the number of edges$|E| = |V| - 1$ . - Directed tree
- A tree with directed edges.
- Rooted tree
- A directed tree where there is a unique root vertex which has incoming degree of 0, and all other vertices have incoming degree of 1. This results in a directed tree which "flows" in only one direction, from the root to the terminal vertices (leaves) of the tree.
- Leaf or terminal vertex
- A vertex in a rooted tree which has outgoing degree of 0.
- Branch node or internal vertex
- A vertex of a rooted tree which is not the root and not a leaf.
- Height and levels of a tree
- The level number of a vertex in a rooted tree is the length of the path from the root to the vertex. The height of a tree is the maximum level of a vertex in the tree, i.e. the length of the path from the root to the deepest node.
- Descendant and ancestor
- If
$v_1$ and$v_2$ are vertices in a rooted tree and$v_1$ has the smaller level number, then$v_1$ is an ancestor of$v_2$ , and$v_2$ is a descendant of$v_1$ . - Child and parent
- If
$v_1$ is an ancestor of$v_2$ and there is a single edge connecting them, then$v_1$ is the parent of$v_2$ and$v_2$ is a child of$v_1$ . - Siblings
- If two vertices in a rooted tree have the same parent, they are called siblings.
- Lexicographic order or dictionary order labeling algorithm
- A rooted tree it called an ordered rooted tree if it is ordered according to this algorithm. Step 1: Assign the root the label 0. Step 2: Next assign the labels 1, 2, 3, … to the vertices at level 1, going from left to right. Step 3: Now let
$v$ be an internal vertex at level$n \geq 1$ , and let$v_1, v_2, \dots, v_k$ denote the children of$v$ , going from left to right. If$a$ is the label assigned to vertex$v$ , assign the labels$a.1, a.2, \dots ,a.k$ to the children$v_1, v_2, \dots, v_k$ respectively. - Binary rooted tree
- A rooted tree in which each vertex has at most two children. If the outgoing degree of all vertices is either 0 or 2, the it is called a complete binary rooted tree.
- Preorder traversal
- The preorder traversal of a rooted tree first visits the root, then traverses the the left subtree in preorder, and then traverses the right subtree in preorder.
- Postorder traversal
- The postorder traversal of a rooted tree first traverses the left subtree in postorder, then the right subtree in postorder, and then visits the root.
- Inorder traversal
- The inorder traversal of a rooted tree first traverses the left subtree in inorder, then visits the root, and then traverses the right subtree in inorder.
- Merge sort algorithm
- Needs content.
Search algorithms
Depth-first search algorithm
Let
- Step 1
- Assign
$v_1$ to the variable$v$ and initialize$T$ as the tree consisting of just this one vertex, (The vertex$v_1$ will be the root of the spanning tree that develops.) Visit$v_1$ - Step 2
- Select the smallest subscript
$i$ , for$2\leq i \leq n$ , such that$\{v, v_i\}\in E$ and$v_i$ has not already been visited, If no such subscript is found, then go to step (3). Otherwise, perfom the following: - 2.1
- Attach the edge
$\{v,v_i\}$ to the tree$T$ and visit$v_i$ - 2.2
- Assign
$v_i$ to$v$ - 2.3
- Return to step (2).
- Step 3
- If
$v = v_1$ , the tree$T$ is the (rooted ordered) spanning tree for the order specified. - Step 4
- For
$v \neq v_1$ , backtrack from$v$ to its parent$u$ in$T$ , Then assign$u$ to$v$ and return to step (2).
Breadth-first search algorithm
Like with Depth-first, let
A queue is a data structure, where the first item inserted is the first item taken out, like a normal queue. Also known as a First-in, First-out or FIFO, structure.
- Step 1
- Insert vertex
$v_1$ at the rear of the (initially empty) queue$Q$ and initialize$T$ as the tree made up of this one vertex$v_1$ (the root of the final version of$T$ ). Visit$v_1$ . - Step 2
- While the queue
$Q$ is not empty, delete the vertex$v$ from the front of$Q$ . Now examine the vertices$v_i$ ,(for$2\leq i \leq n$ ) that are adjacent to$v$ - in the specified order. If$v_i$ has not been visited, perform the following: - 2.1
- Insert
$v_i$ at the rear of$Q$ - 2.2
- Attach the edge
$\{v, v_i\}$ to$T$ - 2.3
- Visit vertex
$v_i$
[ If we examine all of the vertices previously in the queue
Languages and Finite State Machines
Sections 6.1–6.3 in Grimaldi, and sections 12.1–12.5 in Schaum's Outline of Discrete Mathematics, 3rd Edition.
Language
Terminology and Notation
- Alphabet
- A nonempty, finite set of symbols (characters). We use
$\Sigma$ , the uppercase Greek letter sigma, to denote an alphabet. For example, we may have$\Sigma = \{0, 1\}$ or$\Sigma = \{a, b, c, d, e\}$ . - String
- A finite sequence of symbols (characters).
- Concatenation of strings
- The concatenation of the strings
$x$ and$y$ is written$xy$ and as an example, if$x = 01$ and$y = 00$ , then$xy = 0100$ . Concatenation of strings is associative, i.e.$(xy)z = x(yz)$ , but not commutative, i.e.$xy \neq yx$ holds (unless there is only one symbol in the alphabet). - Empty string
- The empty string is the string consisting of no symbols, and we will use the notation
$\varepsilon$ here, although$\lambda$ is used in Grimaldi. The empty string is not a blank space (which is a symbol), and it is not the empty set$\emptyset$ . The empty string is the identity for the operation of concatenation, so that$x\varepsilon = \varepsilon x = x$ , and$\varepsilon\varepsilon = \varepsilon$ . (Compare with the identity for the operation of regular addition$x + 0 = 0 + x = x$ and$0 + 0 = 0$ .) - Powers of an alphabet
- The powers of an alphabet
$\Sigma$ are defined recursively: 1)$\Sigma^1 = \Sigma$ ; and 2)$\Sigma^{n+1} = \{xy|x\in\Sigma, y\in\Sigma^n\}$ . Also,$\Sigma^0 = \{\varepsilon\}$ . The set$\Sigma^n$ is the set of all strings of length$n$ over the alphabet. Somewhat strangely, since the empty string is not an element of the alphabet,$\{\varepsilon\} \not\subseteq \Sigma$ , and$\{\varepsilon\} \neq \emptyset$ . - Kleene closure and positive closure of an alphabet
- The set of all possible (finite) strings over an alphabet is denoted
$\Sigma^*$ (where the * is called the Kleene star operator) and is called the Kleene closure. It is the union of all sets$\Sigma^n$ ,$n \in \mathbb{N}$ , i.e.$\Sigma^* = \bigcup_{i\geq0} \Sigma^i$ . The positive closure$\Sigma^+$ is the Kleene closure on$\Sigma$ without the empty string, i.e.$\Sigma^+ = \Sigma^* - \{\varepsilon\}$ . - Word
- An element of
$\Sigma^*$ . Simply put it is just another name for a string. - Equality of strings
- Two strings are equal when they have the same length, and have the same symbols in the same order. String equality is exactly what you would think it is, so that
$abab = abab$ , but$abab \neq abba$ . - Length of a string/word
- The length of a string is the number of symbols it consists of in total, and is denoted
$\|w\|$ . Formally,$\|w\| = n$ when$w = x_1 x_2 \cdots x_n \in \Sigma^+$ , where$x_i \in \Sigma$ for each$1 \leq i \leq n$ . Note that$\|\varepsilon\| = 0$ and$\|xy\| = \|x\| + \|y\|$ for all$(x, y) \in \Sigma^*$ . - Powers of strings
- For each
$x \in \Sigma^*$ , we define the powers of$x$ by$x^0 = \varepsilon, x^1 = x, x^2 = xx, x^3 = xxx = xx^2, \dots, x^{n+1} = xx^n, \dots$ , where$n \in \mathbb{N}$ . Also, for all$n \in \mathbb{N}$ ,$\|x^n\| = n \|x\|$ . - Prefix
- If
$w = xy$ , then$x$ is called a prefix of$w$ , and if$y$ is not the empty string, then$x$ is said to be a proper prefix of$w$ . - Suffix
- If
$w = xy$ , then$y$ is called a suffix of$w$ , and if$x$ is not the empty string, then$y$ is said to be a proper suffix of$w$ . - Substring
- If
$w = xyz$ , then$y$ is called a substring of$w$ . When at least one of$x$ and$z$ is different from the empty string (so that$w \neq y$ ),$y$ is called a proper substring. - Reversal of a string
- The reversal of the string
$x$ is denoted$x^R$ , and is the string obtained from$x$ by reading the symbols from right to left, just as one would expect. - Language
- For an alphabet
$\Sigma$ , any subset of$\Sigma^*$ is called a language over$\Sigma$ ("a language over an alphabet"). This includes the subset$\emptyset$ , which is called the empty language. - Concatenation of languages
- For an alphabet
$\Sigma$ and languages$A, B \subseteq \Sigma^*$ , the concatenation of$A$ and$B$ , denoted$AB$ , is$\{ab|a \in A, b\in B\}$ . Think of it as the cross product of two languages. - Powers of a language
- For a language
$A \subseteq \Sigma^*$ ,$A^0 = {\varepsilon}, A^1 = A$ , and for all$n \in \mathbb{Z}^+, A^{n+1} = \{ab|a\in A, b\in A^n\}$ . - Kleene closure and positive closure of a language
- The Kleene closure of
$A$ is the language$A^* = \bigcup_{i \geq 0}A^i$ , while the positive closure of$A$ is$\Sigma^+ = \Sigma^* - \{\varepsilon\}$ .
Properties (Rules) of Languages
For an alphabet
Finite State Machines
A finite-state machine (FSM) is an abstract machine that can be in exactly one of a finite number of internal states at any given time. The FSM "remembers" certain information when it is in a particular state. The FSM can change from one state to another in response to some external inputs; the change from one state to another is called a transition. An FSM is defined by a list of its states, its initial state, and the conditions for each transition.
Major Features
- Internal state
- The set of internal states available to a machine is finite. The machine can only be in one state at a time.
- Input alphabet
- The machine will accept a finite number of symbols as input, the set of which is referred to as the input alphabet
$\mathcal{I}$ . E.g. the input alphabet may be$\mathcal{I} = \{0, 1\},$ or even$\mathcal{I} = \{$ 1kr, 5kr, 10kr, 20kr, red button, green button, blue button$\}$ in the case of a simple vending machine. - Output alphabet
- An output and a next state are determined by each combination of inputs and internal states. The finite set of all possible outputs constitutes the output alphabet
$\mathcal{O}$ for the machine. - Synchronization
- We assume that the sequential processings of the machine are synchronized by separate and distinct clock pulses.
Formal definition: A finite state machine is a five-element tuple
State Tables (Transition Tables)
A state table represents the functions

State Diagrams
A state diagram is another way of representing a machine. A state diagram is a labeled directed graph which shows the output and next state for a given input and initial state. Each internal state

More Terminology
- Sequence recognizer
- A FSM which typically has input and output alphabets {0, 1}, and "recognizes" each occurence of a given sequence in an input string. Each time the sequence is encountered by the machine, the machine will output 1, otherwise 0.
- Reachable state
- A state
$s_j$ of a FSM is said to be reachable from$s_i$ if$s_i = s_j$ or if there exists an input string$x$ such that$\nu(s_i, x) = s_j$ . A state can be reachable from some states and not from others in a given machine. - Transient state
- Simply put, a state is called transient if there is no way of getting back to the state after it has been reached. Formally, a state
$s \in S$ is transient if$\nu(s, x) = s$ for$x \in \mathcal{I}^*$ implies$x = \varepsilon$ ; i.e. there is no$x \in \mathcal{I}^+$ with$\nu(s, x) = s$ . - Sink or sink state
- A state is called a sink if there is no way of getting out of that state when it first has been reached;
$\nu(s, x) = s$ for all$x \in \mathcal{I}^*$ . - Submachine
- Informally, a submachine is a machine represented by a subgraph of a state diagram, like a part of a bigger machine. Formally, though... Let
$S_1 \subseteq S, \mathcal{I}_1 \subseteq \mathcal{I}$ . If$\nu_1 = \nu|_{S_1 \times \mathcal{I}_1}\!: S_1 \times \mathcal{I}_1 \to S$ (i.e. the restriction of$\nu$ to$S_1 \times \mathcal{I}_1 \subseteq S \times \mathcal{I}$ ) has its range within$S_1$ , then with$\omega_1 = \omega|_{S_1 \times \mathcal{I}_1}$ ,$M_1 = (S_1, \mathcal{I}_1, \mathcal{O}, \nu_1, \omega_1)$ is called a submachine of$M$ . - Strongly connected
- A machine is strongly connected if every state is reachable from every other state.
- Transfer sequence or transition sequence
- The shortest sequence between two states. When there is more than one transfer sequence between two states, the sequences are of equal length.
Regular Expressions and Languages
Incomplete section. Content for completing this section can be found in sections 12.1–12.5 in Schaum's Outline of Discrete Mathematics, 3rd Edition.
A regular expression
Definition of a regular expression: Consider a nonempty alphabet
- The empty string
$\varepsilon$ and the empty expression$()$ are regular expressions. - Each letter in
$\Sigma$ is a regular expression. - If
$r$ is a regular expression, then$(r^*)$ is a regular expression (the Kleene closure of$r$ ). - If
$r_1$ and$r_2$ are regular expressions, then$(r_1 \lor r_2)$ is a regular expression. - If
$r_1$ and$r_2$ are regular expressions, then$(r_1r_2)$ is a regular expression.
Definition of a regular language: A regular language is a language over an alphabet defined by a regular expression over the alphabet. A language
$L(\varepsilon) = \{\varepsilon\}$ and$L((~)) = \emptyset$ .$L(a) = \{a\}$ , where$a$ is a letter in$\Sigma$ .$L(r^*) = L(r)^*$ , i.e. the Kleene closure of$L(r)$ .$L(r_1 \lor r_2) = L(r_1) \cup L(r_2)$ .$L(r_1r_2) = L(r_1)L(r_2)$ , i.e. the concatenation of the languages.
In this guide, we will make the following (loose) distinction between a finite state machine and a finite machine automaton: The FSM has an output function and an output alphabet, while the FSA has no output function or alphabet, but is rather defined by a set of accepting states and a starting state.
Definition of a finite state automaton:
A finite state automaton (FSA) consists of five parts:
- An input alphabet
$\mathcal{I}$ - A finite set
$S$ of internal states - A subset
$Y$ of$S$ called accepting states - An initial state
$s_0$ in$S$ - A next-state function
$\nu\!: S \times \mathcal{I} \to S$
A FSA recognizes those strings of a language over the input alphabet which end in an accepting state. When drawing the state diagram for a FSA, the accepting states are denoted with a double circle.