CS-450: Advanced algorithms
Introduction
This compendium is made for the course CS-450 Advanced Algorithms at École Polyteqnique Fédérale de Lausanne (EPFL) and is a summary of the lectures and lecture notes. Is is not the complete curriculum, but rather a list of reading material.
Professor: Moret Bernard
Course website: http://lcbb.epfl.ch/algs16/
Three tests during the semester counts towars the final grade. Homework every week, but is only for feedback.
Algorithm analysis and design.
- Algorithms Analysis
- Fast reminders about worst-case analysus, & asymptotic notation
- Amortized, competitive, randomized analysis
- Algorithms design
- Design strategies
- greedy
- divide and conquer
- iterative improvement
- dynamic programming
- (but implement in a different way, randomized, sampling, projections)
- Design strategies
Algorithm analysis
Asymptitic notation
- a.e.: almost everywhere
- There exist a bound where this is always true.
- i.o.: infinitely often
- Only needs another example. This is good for lower bounds
Wagner's conjection: Given a family of graphs defined by a property P. If P is closed under subgraphs and edge contraciton then there exists a finite set of "obstruction" graphs, s.t. every graph not in family includes an obstruction (we can test in polynomial time whether the graphs belogns to the family or not).
An algorithm was also given to find this, which runs in time
Kuratowski's theorem:
A graph is planar iff it does not include one of
Example:
P: Can be embedded in 3D without knots. Was believed to be impossible, but Wagner's conjection tells us that this can be solved in polynomial time.
Worst-case analysis
Ex. Merge sort:
Be able to solve reccurence relations!!
Amortized analysis (connected with data structures)
Look at the cost of a sufficiently long sequence of operations. Do worst-case analysis on sequences of operations (of unknown lenght)
Standard tool: A potential function
Ex: Stacks; push and pop
How many operations is sufficient to calculate amortized? Max
Add a new operation: "empty", but this has to be implemented as pop'ing as long as there are elements left.
Claim: If we start with an empty stack, then any sequence of
Push, pop and empty takes some time and also modify the potential function.
| time | ||
| Push | 1 | -1 |
| Pop | 1 | +1 |
| Empty | - |
Example:
Incrementing a binary integer: Worst-case
Amortized:
Design of potential: We want a simple potential function. Instead of counting trailing 1's, we can simplify and take to number of 1's in the binary representation.
Increment
Yes, you had to do a lot of work, but this made the number nice for further incrementations. It improves the state of the structure.
| cost | sum | |
| i | 1 - (i - 1) = 2 - i | 2 (constant) |
| j | ||
| j+1 | ||
| j+2 |
For
Amortized data structures
Does not try time give a worst-case guaranty, but will give a worst-case over
Example: priority queue:
- Insert (item, priority)
- Delete min.
Binary heap:

Guaranty heap property: Priority of the parent is better (i.e. smaller) than the priority of the children. Delete takes at max
Binary tree, obeying the heap property & it has the leftist property, i.e. the shortest path to a leaf from an internal node is on the right. The consequence is that the tree leans to the left.
THe right edge can at most have lenght
How to merge two trees in
We just have to merge the two right paths. We can rotate the tree (see wikipedia article linked in this header). We can merge teh top part (the right siden in the unrotated one) as two sorted lists. Takes

Delete min:
Behead the tree. How long time does this take? As the frenchmen found out during the revolution, is very easy, constant time!!! - Our French professor
Then we can just meld the two child trees.
Amortized:
When merging trees, instread of keeping track of length to leaf node we can always swap the children instead. This will give just as good time, but amortized. If you do nothing, you double the lenght of the path.
Claim: amortizes to
Design a potential function:
How far is it from a leftist tree? This gets a bit complicated.
We can try to define the potential as
If
$\log n$ is all I'm after - Professor
If we have a path from
The weigth of whats under the node decreasing by half for every time(binary search).
On any parh from the roow to a leaf, there are
TODO: Fill in conclusion. A little unclear for me.
| cost | |
cost is made out of light & heavy nodes,
Sum is
Compeatable (<- TODO) algorithms
Splay trees.
Think of meldable trees. It has to be some kind of link structure to be melded efficiently. Often trees. KISS. Binary trees.
Either heap-ordered of a sorted inorder.
A binary search tree!
Idea: search(
operations of splay(
Move
If
If x is one step down:

If 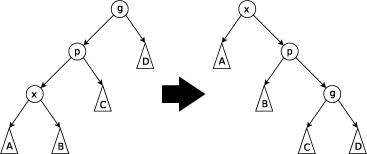
or
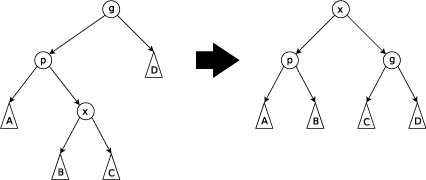
splay(
What if
All operations defined in terms of splay
All I can do is splay. I'm sorry, I'm not very good at this. - Professor
We can implement this in a smarter way, but the reason to do everything in terms of splay is that the analysis is smoother.
- Insert
- run splay(x); if root has
$x$ done; if not in tree is splay($x$ ) on$B$ if$B \neq \emptyset$ . ($x$ must go in$B$ ). If we do splay on$B$ , then we will get the successor. Put in in the root, and we can easily insert$x$ . - Deletemin
- Just splay minimum possible key. This will either bring up the smallest possible key or the predeccessor, which is then the smalles key in the tree.
Amortized analysis
Cost of splay(
Rotation
$r_{after}$ $r^{'}$ $r_{before}$ $r$ $\Delta \Phi$ $r^{'}(x)$ -$r(x) + r^{'}(y)$ -$r(y) + r^{'}(z)$ -$r(z) \leq 3(r^{'}(x)$ -$r(x))$
We have to sum up real cost and
TODO: Fill in
What is the max of
TODO: fill in
laziness is good (for data structures)! - Professor
Lazy leftist tree
Leftist trees that support arbitrary delete. We are prepared to do operations on the right side of the tree, but not in an arbitrary place. The solution is to not delete it, but jusk mark it as deleted.
Deletemin: partial fix. The min node might be dead, so not the min. Fix the top of the tree. Go down to une level under the one taht has alive nodes. We can then get many subtrees and meld them two by two. Cost is
Competitive Analysis
Amortized analysis against an unknown optimal strategy -> so ration instead of absolute values.
Example: Paging strategy LRU (least resently used)
A list that can only be searched sequentially. We can move a used item to the front of the list MTF(move-to-front). We can not do worst time, and it is difficult to do amortized.
We can compare it to the optimal, even though we don't know the optimal strategy.
- Claim: MTF does no worse that twice the cost of the optimal strategy.
- SubClaim: MTF does no worse that twice the cost of the static strategy. (But this method can look at all the expected searches and then decide the fixed order).
- Alg(1)(unknown)
- Picks a fixed oridering that is optimal for the sequence of queries to come.
- Alg(2)
- MTF
We will compare the two algorithms and do an amortized analysis.
- real cost(x) in MTF: i
- real cost(x) in optimal: j
| cost(x) | cost(x) + |
|
| MTF: | ||
| Optimal: |
Example: Dynamic arrays
- Array is to small, double it
- Array is too large, reduce it
- We need a halving threshold
Randomized analysis
- Protection / guerantee against bad distribution of the real data
- Yields very simple & very fast algorithms
- Higher reliability than deterministic version
Make a deterministic algorithm stochastic to protect against unknown events in the outside world. We cannot do average case, since we can not control the probability distribution of the outside world. The real world is not perfect random.
Problem with for instance quicksort. By providing the randomness ourselves, we get an expected
Analysis of 2d hull
- The addition and removal of edges and vertices amortizes to
$\Theta(n)$ over algorithm. - The running time is determined by the maintanance of the conflict list structure by backwards analysis.
- What needs to change if we remove the last vertex added. Last vertex is any of the
$i$ vertices with equal prob. THe order in which the$i$ vertices were added does not matter.
- What needs to change if we remove the last vertex added. Last vertex is any of the
Karger's algorithm for min cut in a graph
Given a connected, indirected graph,
Def: A cut is a subset of edges whose removal disconnects the graph.
Select an edge on random, with the assumption that this edge is not a part of the graph, since the cut is smalled compared to the total size of the graph. Mincut size is
Idea: Pick an edge at random and decide it's not in the cut; modify the graph to reflect that. The edge we have removed does not contribute on disconnecting the graph. Then merge the two end points of the edge. This removes one vertex and one edge. Keep duplicate edges. This is known as multigraph. The size of the min cut has not changed. Repeat this until we only have two vertices. The edges connection these two vertices are the cut.
The probability that we manage to avoid the min cut in the start is good, but as the algortihm runs, the cut size
- Min cut size
$k$ - # edges
$geq \frac{nk}{2}$ - Not hitting min cut at first choice:
$1 - \frac{k}{nk/2} = 1 - \frac{2}{n}$ - Not hitting min cut at second choice:
$1 - \frac{2}{n - 1}$
Probability of geting a mincut at the end:
Probability is
Repeat the algorithm
This is very robust, very fast and very cute! - Professor
Make assumptions to analyse the tails of deviation.
Markov theorem (Markov inequality):
Probability distribution x with exp.
Need more knowledge about distrubution to get tighter bounds. We know the variance and the mean.
Assume
Proof: Use Markov inequality using exponential generating functions.
Algorithm design
Dynamic programming
Discrete, finite Markoc models.
- A collection of states,
$S = \{S_1, S_2 \}$ - A stochastic transition matrix
$T = [t_{ij}]$
Add an output function (emission), also stochastic. If we have finite output alphabet
Slightly dishonest casino
Dice are supposed to create an equally possible output. You can create a slightly weighted (pipped) die.
Baum-Welch algoritm